近年来,自动定理证明(ATP)取得了显著进展,但大部分工作都集中在处理纯文本形式的定理。
然而,在现实世界中,尤其是在几何学领域,许多定理的呈现和理解都离不开图像、图表等视觉元素。
人类数学家善于从这些图表中获取直觉,并将其作为引导严谨证明过程的关键。
那么,当下的多模态大模型(MLLMs)能否模仿人类的这一能力,从图文中汲取信息,完成可被机器严格验证的形式化证明 (Formal Proof) 呢?
这一重要潜能,在很大程度上仍未被探索。
为了系统性地回答这一问题,香港科技大学的研究团队推出了 MATP-BENCH,一个全新的多模态、多层次、多形式化语言的自动定理证明基准,旨在全面评估MLLMs作为自动定理证明者 (Automated Theorem Prover) 的真实能力。

论文地址:https://arxiv.org/pdf/2506.06034
项目主页:https://matpbench.github.io/
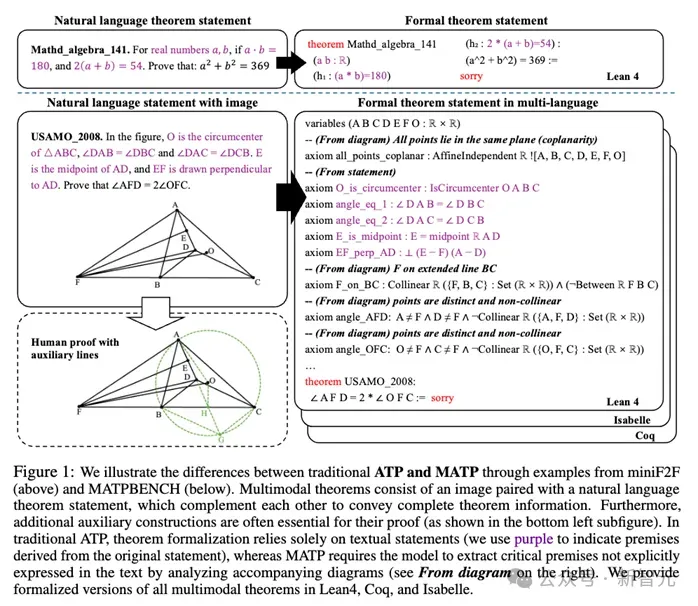
MATP-BENCH任务与传统ATP任务的对比。传统ATP仅依赖文本化的定理陈述,而MATP-BENCH要求模型必须结合图像和自然语言,并从中提取文本中未明确说明的关键前提(如图中「From diagram」部分所示),才能构建完整的形式化定理 。
MATP-BENCH的设计
MATP-BENCH是首个专为多模态定理证明设计的基准,涵盖了三种主流的形式化证明语言:Lean 4、Coq和Isabelle。
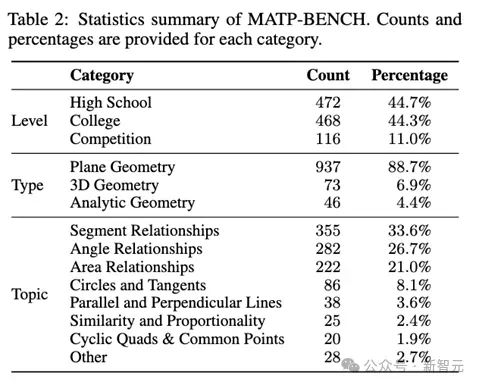
MATP-BENCH 的统计数据。左表展示了不同难度级别和几何类型的题目分布,右表展示了更细分的数学主题分布 。
核心特点包括:
- 多模态上下文:每个问题都由一张图像和一个自然语言陈述组成,二者互为补充,共同构成完整的定理信息。
- 多层次与多样性:基准共包含 1056个多模态定理 ,题目难度横跨高中、大学和竞赛三个级别 。内容上则覆盖了平面几何、3D几何、解析几何等多个领域 。
- 多语言形式化:所有定理都提供了在 Lean 4、Coq 和 Isabelle 三种证明辅助工具中的形式化版本,确保了广泛的兼容性 。

MATP-BENCH与相关可验证基准的详细对比。MATP-BENCH在多模态、多层次和多形式化语言支持上具有综合优势。
多数现有基准如 miniF2F 和 ProofNet 仅包含纯文本定理 。虽然 LeanEuclid 等基准包含多模态几何问题,但其主要任务是「自动形式化」(将人类语言证明转为代码),而非从零开始生成证明 。
为了精准评估模型在不同阶段的能力,MATP-BENCH 设置了两个关联的核心任务:
(1)多模态自动定理证明 (Multimodal Automated Theorem Proving):模拟人类专家的端到端形式化定理及证明过程;
(2)多模态定理形式化 (Multimodal Theorem Formalization):单独评估模型理解和翻译多模态信息为形式化定理的能力。
实验结果
通过在MATP-BENCH上进行的大量实验,研究团队不仅定位了当前多模态大模型(MLLM)在形式化定理证明上的核心瓶颈,更从多个维度揭示了其能力的边界和挑战。
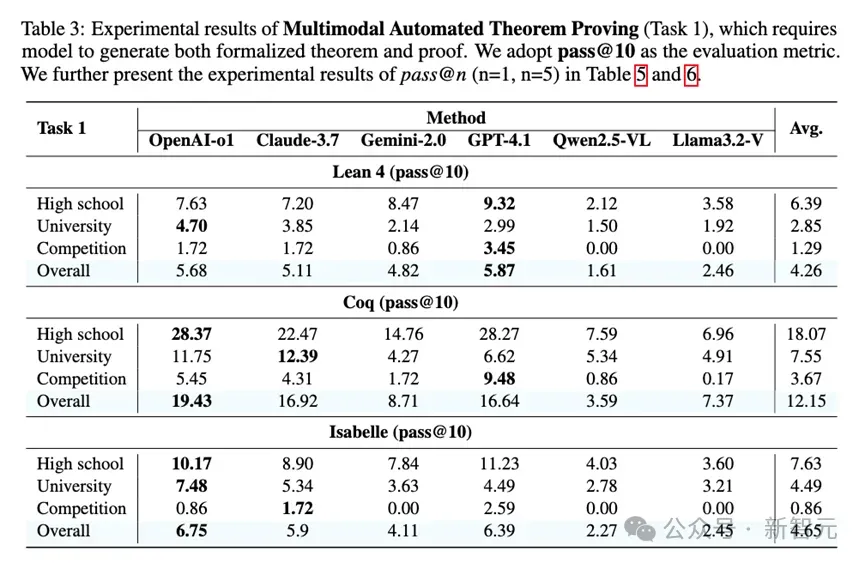
实验揭示了模型在不同形式化语言上的性能差异,最强大的模型在Lean 4语言上pass@10成功率仅为4.26%,而在生成Coq语言上表现出人意料地好,任务一的成功率达到了12.15%,显著高于Lean 4和Isabelle。
研究者推测,这可能得益于Coq更成熟的策略库、丰富的数学资源以及更适合大模型学习的命令式策略风格。
模型的性能随着题目难度的增加而显著下降。
在Lean 4的任务一中,模型在高中、大学和竞赛级别问题上的平均成功率分别为6.39%、2.85%和1.29%
不同模型「犯错」方式不同
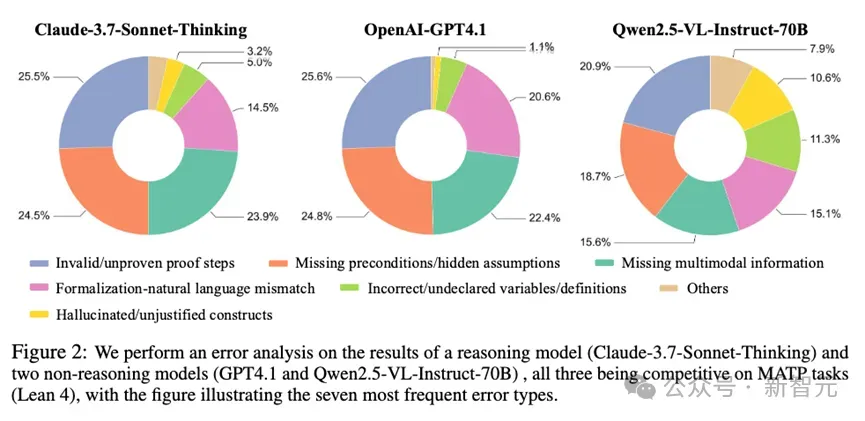
图中展示了三类模型在 Lean 4 任务上的错误分布。可以清晰地看到,Qwen2.5-VL(右)的基础性错误(如变量定义和库导入)比例显著高于 Claude-3.7(左)和 GPT-4.1(中)
对于表现较好的闭源模型(如Claude-3.7和GPT-4.1),其错误主要集中在「无效或未完成的证明步骤」和「缺失前提/隐藏假设」 。而对于一些开源模型(如Qwen2.5-VL),错误模式则有所不同。
虽然它们同样存在逻辑推理问题,但取它们出现了更多基础性的生成错误,例如「不正确或未声明的变量/定义」以及「缺失/错误的库导入」。这说明,这类模型不仅在高级逻辑上面临挑战,在掌握形式化语言的基本语法和规范上就已困难重重 。
核心瓶颈——「证明」而非「看懂」
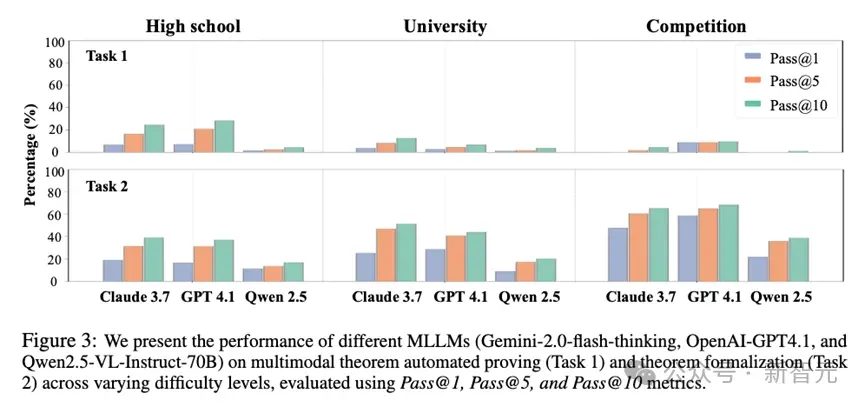
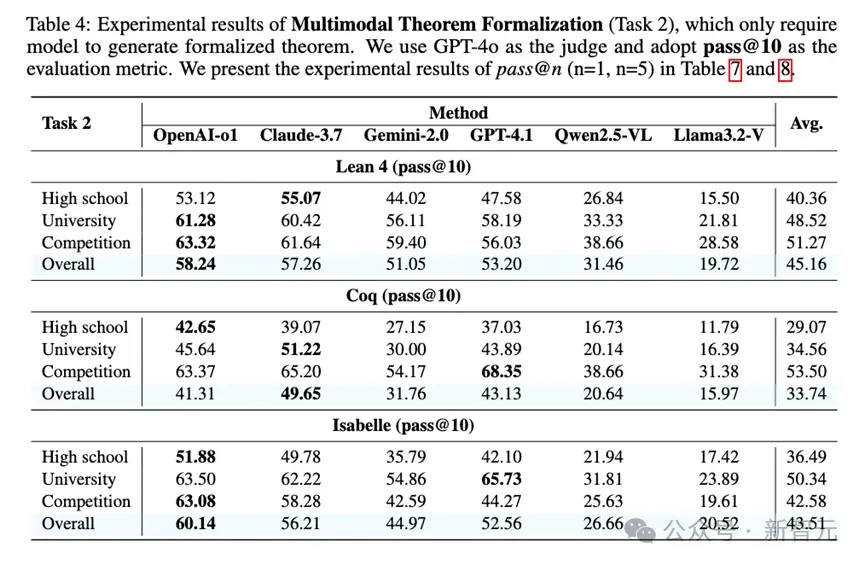
实验另外揭示了一个普遍现象:模型在任务一(端到端形式化证明)上的表现普遍不佳,但在任务二(仅形式化定理)上表现要好得多。
以Lean 4语言为例,模型在任务二上的平均pass@10成功率(即10次尝试内成功一次的概率)可达45.16%,这说明它们具备了相当不错的图文理解和形式化转译能力。
然而,在需要完整证明的任务一上,该数值骤降至仅4.26%,这一差距清晰地表明:当前MLLM的主要瓶颈并非「看懂题目」,而是后续「构建证明」的复杂逻辑推理过程 。
辅助线难题——「画不好也用不好」
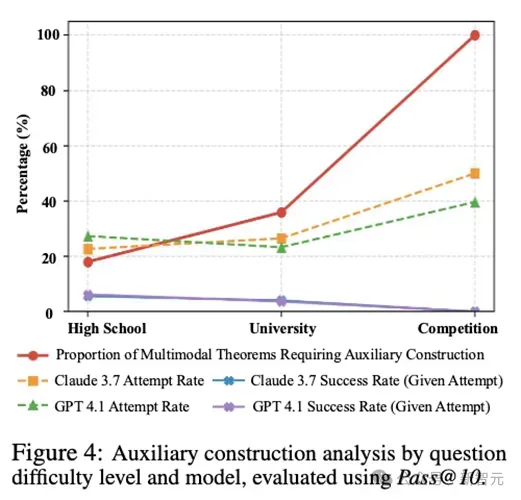
图中灰色曲线显示需要辅助线的问题比例随难度上升。模型的尝试率(虚线)也随之上升,但成功率(实线)却始终处于极低水平
在人类的几何解题中,添加辅助线是一种常见且强大的策略。
实验发现,随着题目难度的增加,需要辅助线的问题比例也显著上升。
模型在一定程度上能够模仿人类,尝试在证明中引入辅助线等构造性步骤 。
然而,它们几乎无法有效构造和利用辅助线来推进证明,导致包含辅助线构造的证明成功率极低 。
总结与展望
MATP-BENCH的研究结果清晰地表明要让MLLM成为合格的多模态定理证明者,研究需要重点关注:
- 提升符号推理能力:开发新的模型架构或训练方法,专门增强模型在严谨的形式化逻辑系统中的推理和证明构建能力。
- 增强视觉-符号联合推理:让模型不仅能「看见」图中的几何关系,更能将其无缝转化为可用于证明的形式化符号语言。
- 探索交互式证明生成:让其利用外部工具进行辅助思考,可能是一个充满希望的研究方向 。


