昨天,马斯克的 xAI 发布了新模型 Grok 4 Fast。作为 Grok 4 的“兄弟型号”,它更便宜、更快、可大规模扩展,目标是在长上下文推理和智能体工具使用上进一步突破。
🚀 核心看点
Grok 4 Fast 是 xAI 的 Grok 4 的一个变体,强调效率和可用性,同时不牺牲性能。
200万token上下文窗口:可以一次性处理整本书级别的文档、庞大的代码库或数月的聊天记录。(全球天花板水平)
统一推理与非推理模型:单一权重集,可根据指令切换行为。
比 Grok 4 少用 40% 的“思考 token”:在深度推理时更高效。
原生工具使用:通过强化学习训练,能够判断何时以及如何上网浏览、调用 X或执行代码。
激进的价格策略:社区报告显示,输入约 $0.20 / 百万 token,输出约 $0.50 / 百万 token(折3.5元),相比 Grok 4 之前的 $3 / $15,便宜了一个数量级。

💡 为什么这很重要
长上下文突破:200万token 让“分块+检索”的做法成为了非必要。无论是法律文件、代码库还是学术档案,都能一次性放进prompt。
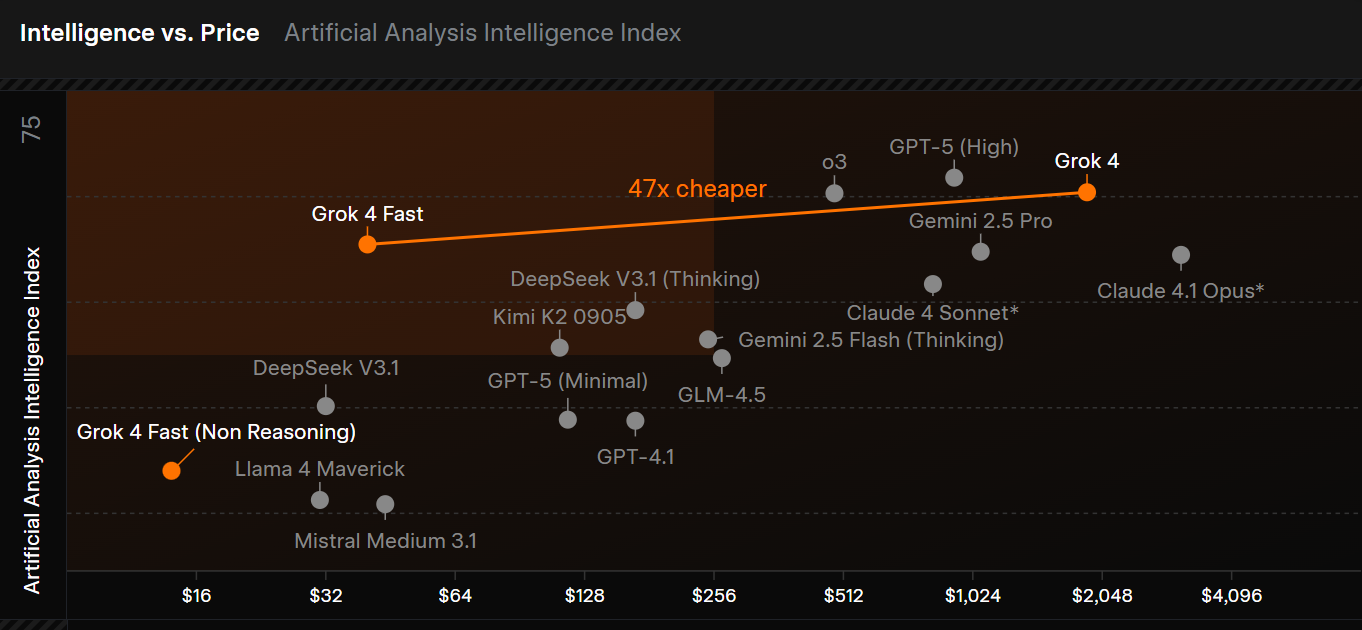
成本优势:对初创公司、研究人员和需要高并发任务的企业来说,价格比DS都便宜一大半。
智能体工作流:Grok 4 Fast 原生支持浏览、多步推理和工具编排,这是构建自主智能体的关键能力。
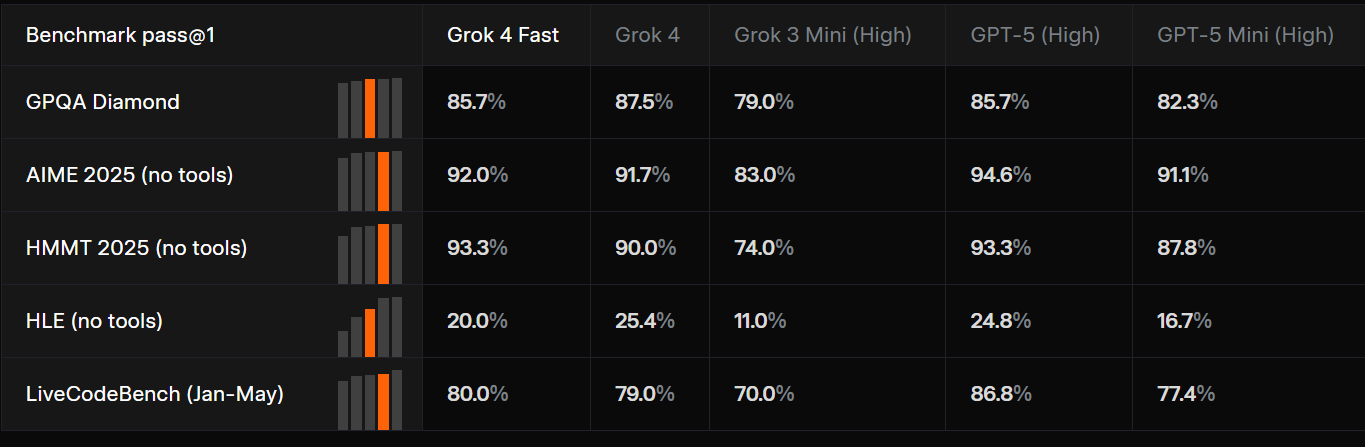
竞争性测试:从GPQA到LMArena,Grok 4 Fast 与顶尖模型正面较量,尤其在搜索任务中表现出色。
⚠️ 需要注意的限制
透明度缺口:尚不清楚200万token窗口是密集注意力机制,还是混合方案。这会影响延迟与可扩展性。
领域差异:在浏览/搜索上表现优秀,但在金融或法律等细分任务中表现参差不齐。务必针对你的场景做验证。
🛠️ 如何生产评估
如果你想在生产环境中验证 Grok 4 Fast,建议清单:
✅ 在保留集上运行可复现的测试(MMLU、GPQA、AIME)。
✅ 压测长上下文输入(10 万 → 200 万 token)。
✅ 基准测试智能体工作流(浏览 + 工具调用)。
✅ 按预计token规模计算模型成本。
✅ 在你的领域内对比 Claude、GPT-5 和 Gemini。
🎯 入手建议
特别适合智能体搜索、超大输入场景、成本敏感的部署场景,比如法律科技工具、研究助手或大规模总结系统等,都值得尝试。


