最近,有学员在公司要做一个用户反馈的智能分类功能,需要打上“积极”、“消极”、“中性”这样的标签,他的第一反应是要微调模型了,来问我如何微调模型,我说,并不一定要微调模型,可以先了解一下什么是:Zero-Shot Learning、One-Shot Learning、Few-Shot Learning。
假设我们现在有一个需要分类的用户反馈:“这新功能真是太棒了,体验感一流!”
第一种方式:Zero-Shot (零样本学习)
我们直接向模型下达指令,不给它任何参考范例。
复制第二种方式:One-Shot (一样本学习)
我们在提出要求时,给模型一个例子,让它照着学。
复制第三种方式:Few-Shot (少样本学习)
别怕麻烦,多给模型几个例子,让它更好地领悟你的意图。
复制我们没有写一行 ,没有进行任何的模型训练,仅仅是通过提示词,就可以引导模型完成任务。
那么,问题来了:为什么只是多给了几个例子,模型就知道该怎么做了?这背后到底发生了什么?
很多同学看到 "Learning" 这个词,可能会下意识地认为模型在学习我们提供的样本,实时地更新了它的内部参数,就像我们用新数据训练模型一样,这是一个常见的误区!
在 Zero/One/Few-Shot 场景下,大语言模型的权重是完全冻结的,没有任何参数被更新。这个过程并非我们传统意义上的“学习”或“训练”,它更像是一种“上下文引导”或“能力激活”。
我们可以把 DeepSeek 这样的大语言模型想象成一个刚刚进入你团队的、超级博学的实习生。他阅读了互联网上几乎所有的公开文本(万亿级别的单词),知识渊博得可怕。
•Zero-Shot:你直接对他说:“帮我做个用户反馈情感分析。” 因为他读过无数类似的文章和代码,他能“猜到”你大概是想让他输出“积极/消极”这样的标签。对于常见的、定义明确的任务,他能做得不错。
•One-Shot / Few-Shot:你把他叫到身边,跟他说:“我们团队做事有自己的规矩。你看,像‘卡顿’这种反馈,我们标记为‘消极’;像‘功能还行’这种,我们标记为‘中性’。现在,你来处理一下这个‘太棒了’的反馈。”
在这个过程中,实习生并没有重新学习编程语言,他的大脑结构和知识储备没有改变。但是,你给出的这几个例子为他提供了解决当前特定任务的“临时参考”,他通过这些例子,瞬间理解了:
1.任务目标:哦,原来是要做分类。
2.输出格式:原来要输出“XX:YY”这样的格式。
3.边界情况:原来“不好看但功能还行”这种模棱两可的算“中性”。
这些例子激活了他大脑中早已存在的、关于“分类”、“情感”的知识,并将其组合起来,以一种更精确、更符合我们期望的方式完成任务。
从更技术的角度来说,这得益于 LLM 的核心架构——Transformer。Transformer 的自注意力机制(Self-Attention)非常擅长在给定的上下文(也就是你的整个 Prompt)中寻找词与词之间的关联。
当我们提供 Few-Shot 样本时,模型在处理我们真正要问的那个问题(“这新功能真是太棒了”)时,会同时“注意”到我们前面给出的例子,它会分析例子中的输入与输出之间的模式,然后将这个识别出的模式应用到新问题上。
这就像我们在 Java 中调用某个第三方工具时,我们不会去修改它的源码(冻结的权重),我们只是通过传入不同的参数(Prompt)来调用它不同的能力,并组合这些能力来解决问题。
总结一下
•简单通用任务 -> Zero-Shot
•复杂/特定格式任务 -> Few-Shot
•介于两者之间 -> One-Shot
以上就是本文的主要内容,希望能让你对大模型底层有更多了解,都看到这了,别忘了点赞、分享、关注哦,谢谢你的鼓励,是我持续创作的动力。
如果你对大模型底层感兴趣,如果你想要在未来的AI时代能有一席之地,如果你想通过AI来使自己翻身拼一把,如果你想要提高自己的竞争力,想要升职,想要加薪,想要跳槽,想要被公司看重,想要有一个更好的职业生涯,仅仅只会用AI是完全不够的,而是得懂AI底层,掌握大模型底层,这样你才更有亮点,更加特殊,更加有价值,才是AI时代需要的程序员人才。
我最近新出了一个《零基础手写大模型》的课程,这个课非常能打,从零基础开始,到神经网络,到语言大模型,最终到多模态大模型,GPT、DeepSeek、Stable Diffusion等著名模型的底层实现通通会讲,理论+手写+实战,要多系统有多系统,要多全面有多全面,再加上我的讲课能力,通过带大家手写代码,让大家从晦涩的数学公式中脱离出来,通过代码掌握大模型底层,有理论讲解,有手写实现,有实战训练,简直是一个完美课程。
课程学完,你可以找算法工程师、大模型底层开发等高薪岗位,竞争压力小,你也可以选择继续做Java程序员成为Java+AI双架构师,让你比别人更有竞争力,对你找工作、面试跳槽都非常有帮助,非常值得一学。
以下是我从零开始手写的Stable Diffusion模型的效果展示,还不错吧:
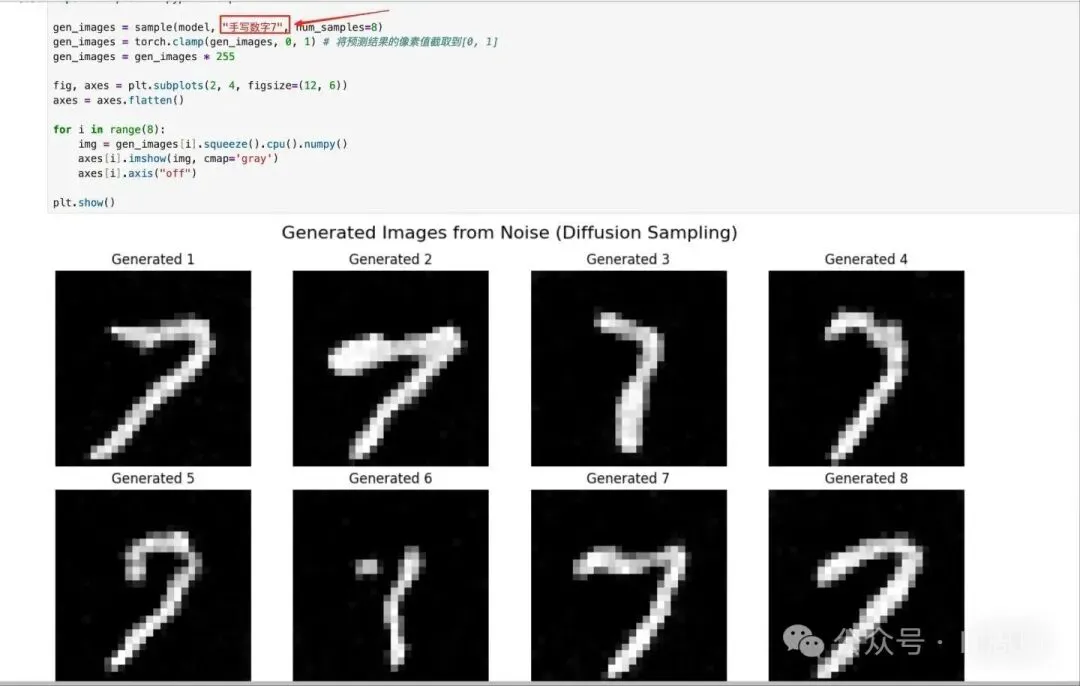 图片
图片
以下是我从零开始手写的GPT模型的效果展示,也还不错吧:
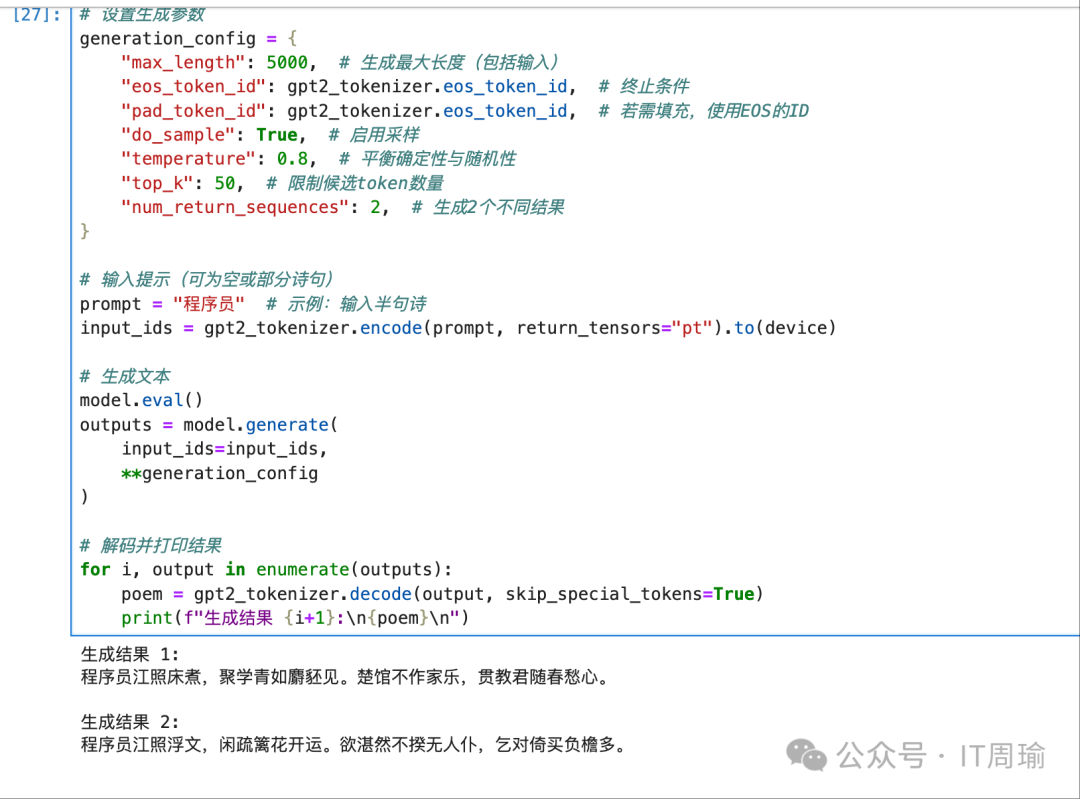 图片
图片


