AI 导师吴恩达在其最新一期的 The Batch Newsletter 中,将目光投向了来自蚂蚁集团的最新开源模型 Ling-1T。
吴恩达 The Batch Newsletter 首页截图
他敏锐地指出:Ling-1T 作为一个非推理(non-reasoning)模型,其性能却直逼业界顶尖的闭源模型,这背后隐藏着一个关键的技术转向。
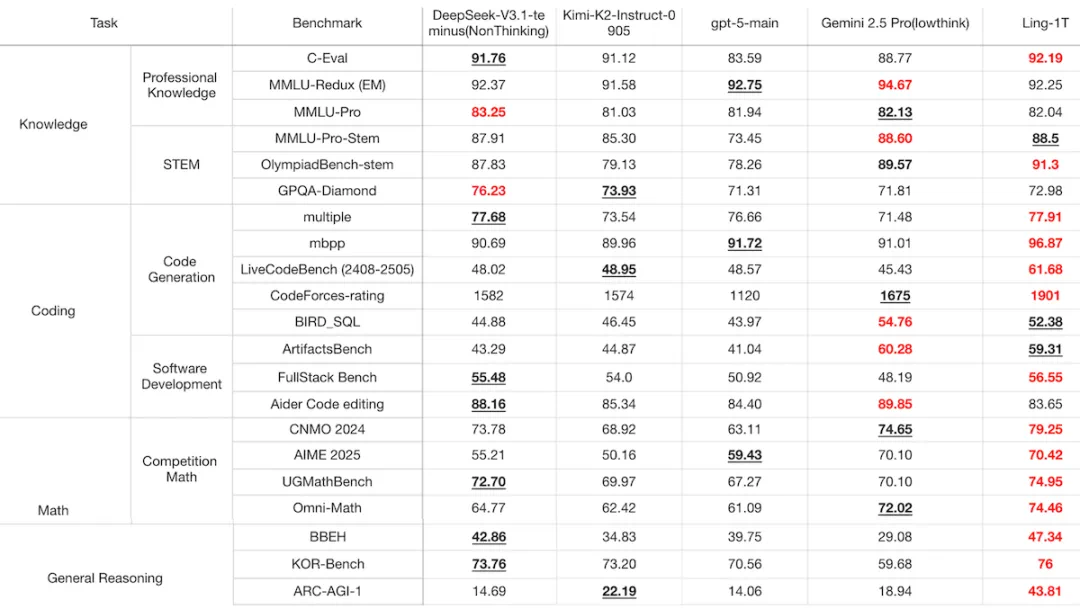
Ling-1T(最右列)与几款具有代表性的旗舰模型的比较,包括大参数量的开源模型(DeepSeek-V3.1-Terminus、Kimi-K2-Instruct-0905)与闭源 API(GPT-5-main、Gemini-2.5-Pro)。此图也被吴恩达 Newsletter 引用。
吴恩达提到,Ling-1T 在预训练阶段就强化了思维链(CoT) ,这种做法「正在模糊推理与非推理模型之间的界限」。这引出了一个业界都在关心的问题:Ling-1T 卓越的推理能力究竟从何而来?
事实上,Ling-1T 的成功还并非孤例。近两个月,蚂蚁集团以前所未有的速度和力度密集开源了 Ling-mini-2.0、Ling-flash-2.0、万亿参数的 Ling-1T(参阅报道《更大,还能更快,更准!蚂蚁开源万亿参数语言模型 Ling-1T,刷新多项 SOTA》),乃至其后的 Ring 系列推理模型(参阅《蚂蚁 Ring-1T 正式登场,万亿参数思考模型,数学能力对标 IMO 银牌》)。这一系列动作的背后,都指向了一套统一的「秘密武器」。
现在,通过一份长达 58 页的硬核技术报告《Ling 2.0 Technical Report》,蚂蚁集团百灵团队(Ling Team)揭示了这个答案。

报告标题:Every Activation Boosted: Scaling General Reasoner to 1 Trillion Open Language Foundation
报告地址:https://arxiv.org/abs/2510.22115
代码地址:https://github.com/inclusionAI/Ling-V2
模型地址:https://huggingface.co/collections/inclusionAI/ling-v2
这份报告不仅是 Ling 系列的模型说明书,更是一份详尽的模型配方和技术蓝图。该报告系统性阐述了蚂蚁究竟是如何构建一个如此强大、统一且可扩展的模型基础,进而如何实现从 16B 到 1T 参数规模的、面向推理的(Reasoning-Oriented)模型训练。
其核心设计哲学可以凝练为一句话:Every Activation Boosted,即确保每一次激活都在扎实地提升模型的推理能力。
我们或许要问,在当前 AI 领域「模型大爆炸」、性能强大的新模型层出不穷的背景下,仅仅发布又一个模型的训练细节,意义何在?
事实上,这个问题的答案或许正好体现了蚂蚁集团这份 Ling 2.0 技术报告的远见。它并非仅仅展示「我们做出了什么」,而是试图系统性地回答一个更深层的问题:在通往更强大 AI 的道路上,尤其当算力成本成为核心制约时,我们如何才能构建一套可持续、可规模化、并且是以提升关键推理能力为核心的高效范式?
这份长达 58 页的报告正是蚂蚁针对这一挑战交出的答卷,它从模型架构、预训练、后训练和基础设施四个层面,系统性地表明:Ling 2.0 是一个为推理而生的整体工程。它不是零散技术的堆砌,而是四大支柱协同作用的产物。
支柱一:架构与 Scaling Law 万亿模型的设计图
在万亿参数时代,设计模型就像是在「戴着镣铐跳舞」,其中有着高计算成本、长训练周期以及难以预测的稳定性等各种问题问题。蚂蚁的答案是极致稀疏的架构与极致精准的预测。
Ling 2.0 系列(从 16B 到 1T)全部采用统一的「高稀疏、细粒度」 MoE 架构:其总专家数多达 256 个,但每次前向传播仅激活 8 个专家和 1 个共享专家,激活率低至惊人的 3.5%!
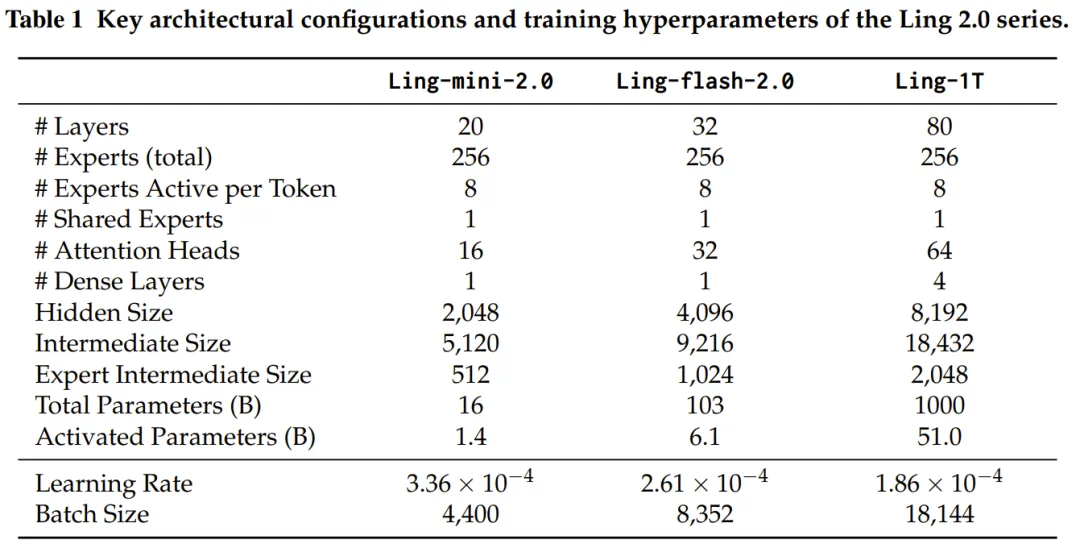
Ling 2.0 系列模型的关键架构配置和训练超参数
这带来了什么?报告证实,Ling 模型实现了相较于同等性能的密集 (Dense) 模型近 7 倍的计算效率杠杆。
然而,更核心的秘密武器是 Ling Scaling Laws。
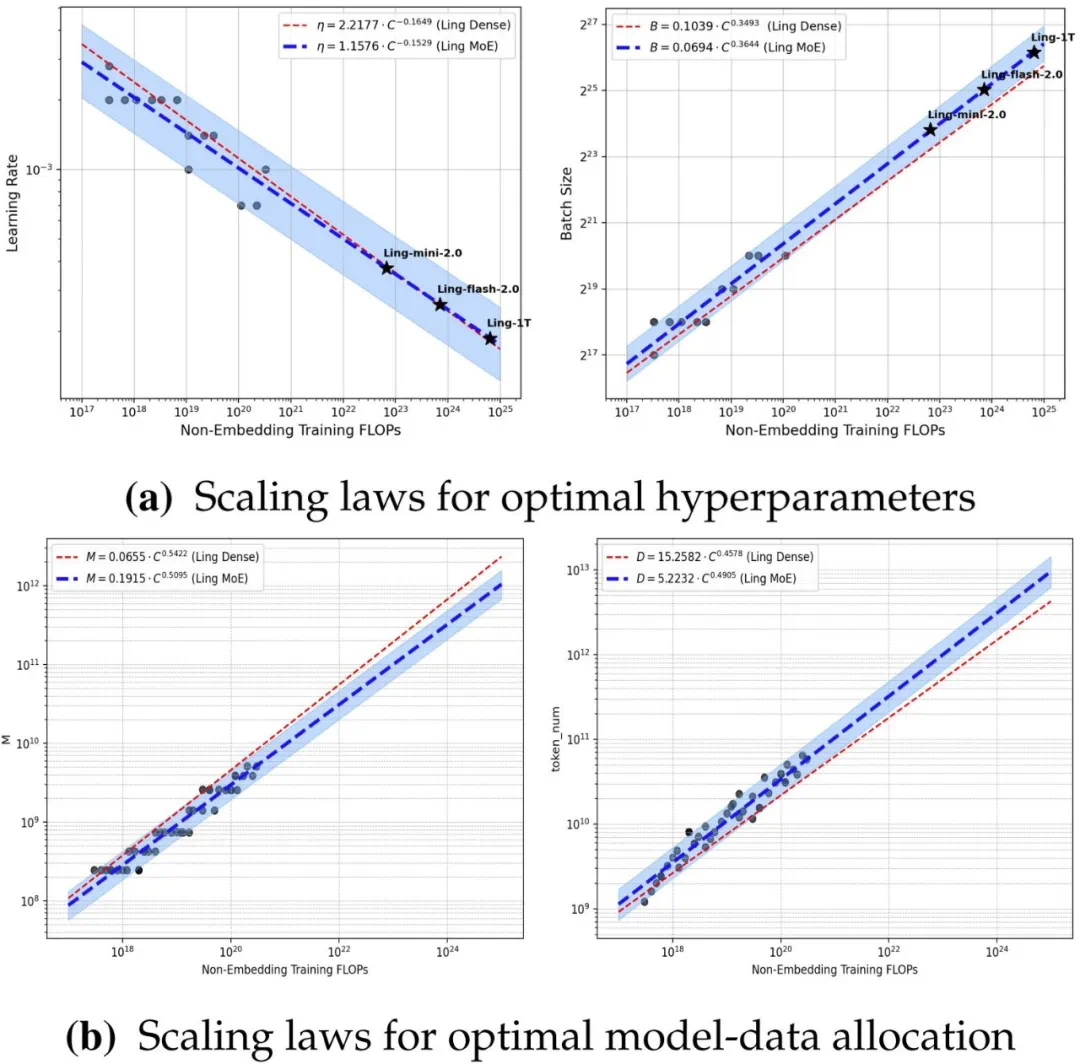
最优超参数与最优模型 - 数据分配的 Scaling Law。蓝线和红线分别表示在相同训练条件下拟合得到的 MoE 模型与密集模型的深度学习。
这不仅是一个公式,更是蚂蚁建立的一套「AI 风洞」实验系统。它能通过极低成本(不到 1%)的小规模模型实验,高保真地预测和外推万亿参数模型在超过 1e25 FLOPs 的巨大计算量下的性能和最优超参数。
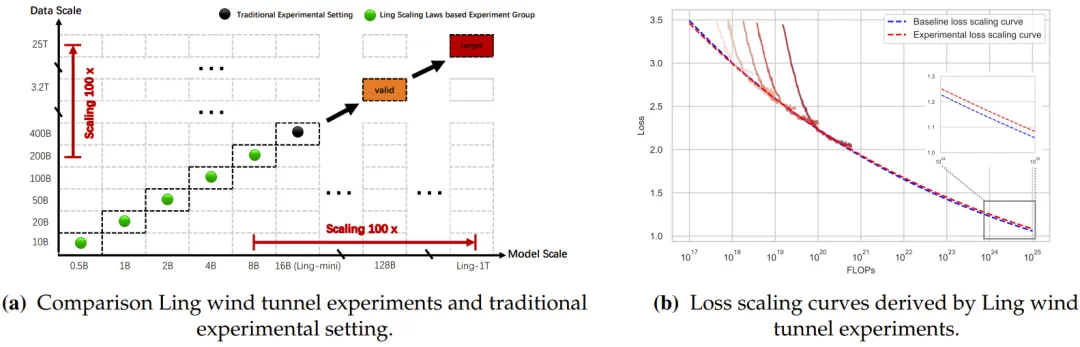
Ling 风洞实验设计示意图 (a) 及示例分析 (b)
Ling 2.0 的所有关键架构决策都是在这套定律的指导下完成的,例如「为何是激活 8 个专家?」(报告中被验证为最优范围)。
这种强大的预测能力是蚂蚁敢于启动 Ling-1T 训练并确保其稳定和高效的工程底气。同时,Ling 2.0 架构还原生集成了 MTP(Multi-Token Prediction),从底层设计上强化了数学与代码这两大关键推理能力。
值得一提的是,这个统一架构不仅被用于 Ling 系列模型,也是 Ring-1T 等推理模型的骨架。正如 Ling 团队最新发布的 Ring-linear 混合线性架构报告(arXiv:2510.19338)所示,即便是探索线性注意力(Linear Attention),其 MoE 结构的设计和扩展依然严格遵循 Ling Scaling Laws 的指导。
支柱二:预训练与中训练 为推理预激活
如果说架构是骨架,那么预训练就是为模型注入灵魂。Ling 2.0 的灵魂从一开始就为推理而生。
基于 20T tokens 的海量预训练数据,Ling 2.0 贯彻了「推理优先」的原则。
其报告披露,其 Ling Math 和 Ling Code 高质量推理数据集在预训练过程中占比从 32% 逐步提升到了 46%。这可以让模型在形成世界知识的初期就建立起强大的逻辑和结构化思维。
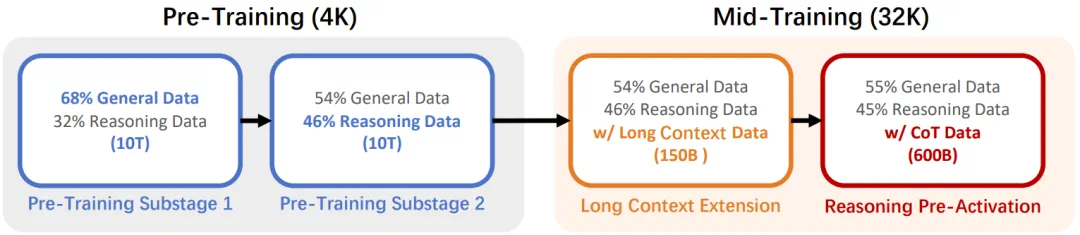
Ling 2.0 的预训练与中训练阶段。其中采用了多阶段训练策略,将上下文窗口从 4K 逐步扩展至 128K,并在训练早期就引入推理与链式思维(CoT)数据,这样可以提前激活模型的推理能力。
而其后的中训练 (Mid-Training) 阶段更是 Ling 2.0 区别于常规模型的点睛之笔。这个创新也正是吴恩达所关注的一大焦点,他指出:

Ling-1T 的整体表现优于强大的 Kimi K2,并显著缩小了开源模型与闭源非推理模型之间的差距。其成功的关键因素似乎在于超大规模的参数量以及在思维链上的预训练。由于在预训练阶段对思维链进行了高度强化,Ling-1T 在生成回答时往往会自发地先形成一条思维链,但这一过程却并非独立的推理阶段。这样的训练方式模糊了推理型模型与非推理型模型之间的界限。
具体来说,在预训练和 SFT 之间,Ling 团队创新性地引入了大量高质量思维链数据。这一步操作,相当于在模型 SFT 前就提前将其强大的推理潜能激活 (Pre-Activation),从而可为其后续的对齐训练提供更高的性能上限和更稳定的思维基础。
此外,Ling 团队还引入了他们之前提出的 WSM(Warmup-Stable-Merge)调度器这一训练技术。它抛弃了难以把握时机的传统学习率衰减(LR decay),转而在训练中保持学习率稳定,最后通过检查点合并(Checkpoint Merging)来实现模型收敛。这种设计不仅更灵活,还为下游任务带来了 1-2% 的平均性能提升。

WSM 预训练管线的伪代码,来自蚂蚁 Ling 团队与人大高瓴人工智能学院合作论文 arXiv:2507.17634
支柱三:后训练对齐 行业首创的句子级 RL
当一个模型已被「预激活」了推理能力,传统的后训练方法已不足以驾驭它。Ling 2.0 在对齐阶段的算法革新,尤其是强化学习(RL)层面,展现了惊人的创造力。
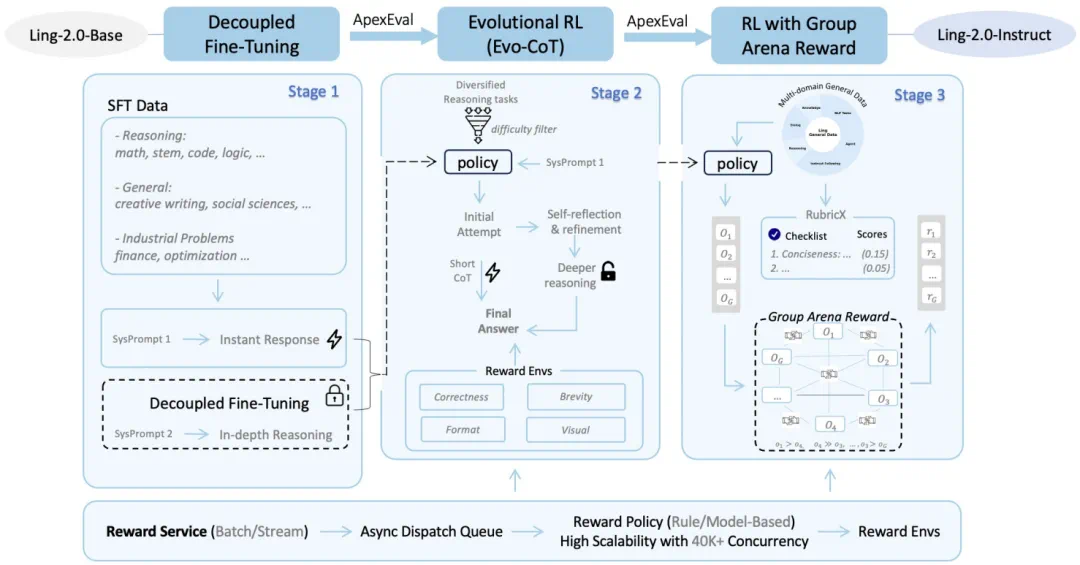
Ling 2.0 系列模型的后训练流程
首先,在 SFT 阶段,Ling 团队采用 DFT(Decoupled Fine-Tuning)策略,通过设计两种不同的系统提示词(如 detailed think on 与 detailed think off),让模型在同一套权重下,学会了「即时响应」和「深度推理」两种可控模式。

而接下来的 RL 训练,其核心目标就是将「深度推理」这一模式的潜力压榨到极致。随后,Evo-CoT(演进式思维链)RL 训练开始接管,持续优化模型的深度推理模式。这使得 Ling 这样的非推理模型也能根据问题的复杂度动态地扩展其推理深度和成本。

Evo-CoT 的数学描述
而 Ling 2.0 在 RL 上的核心创举是 LPO(Linguistic-unit Policy Optimization)算法。这是一个堪称行业首创的思路:当前的 RL 算法(如 GRPO 或 GSPO)通常在 token 级别或序列(sequence)级别进行优化。Ling 团队认为,对于推理任务而言,这两种粒度要么过于破碎(难以承载语义),要么过于粗糙(奖励信号模糊)。
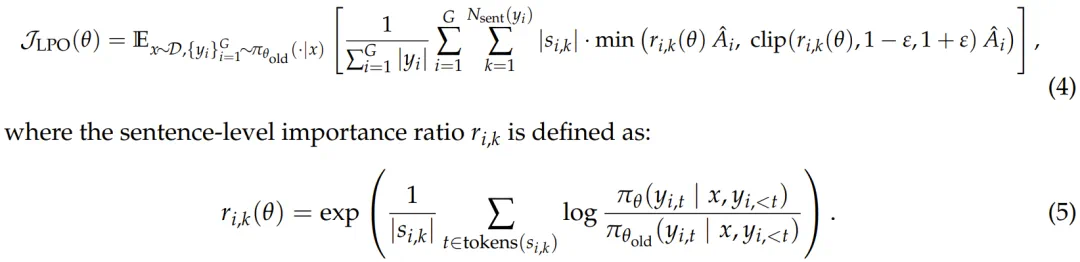
LPO 的目标函数
为此,LPO 首次将语言单元(Linguistic-unit,即句子)作为 RL 策略更新的基础动作单元。
这一创举价值巨大。一个「句子」恰好是承载一个完整逻辑步骤或语义信息的自然边界。通过在句子粒度上对齐奖励信号,Ling 2.0 实现了极高的训练稳定性和泛化性。报告显示,仅此一项优化,就在复杂推理任务上带来了约 10% 的显著性能提升。
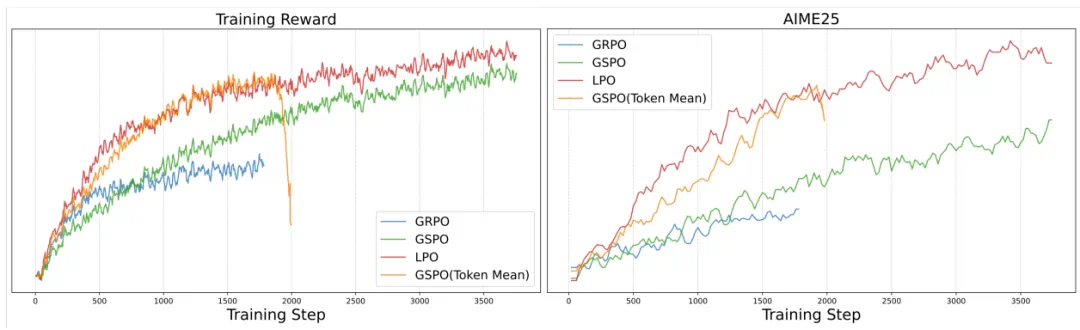
Ling 2.0 模型在强化学习训练中使用 LPO 的奖励曲线。左图:在训练数据上的奖励变化,相较于 GRPO、GSPO 以及 GSPO(Token Mean)基线,LPO 表现出更平滑的增长与更高的稳定性,没有出现明显的平台期或崩溃。右图:在 AIME 2025 测试集上的奖励曲线,展示了由于采用句子级策略更新而带来的更快收敛速度与更好的泛化能力。
当然,强大的 RL 算法也需要精准的裁判。在处理创意写作、对话等开放性主观任务时,Ling 2.0 引入了 GAR(Group Arena Reward)机制。不同于给单个答案打绝对分,GAR 采用循环赛式的相对比较:它将同一策略生成的多个答案放入竞技场 (Arena) 中进行两两对比,以相对排名代替绝对分数。这种机制能有效降低主观评估中的噪声和方差,为模型在开放域的对齐提供了更可靠的奖励信号。
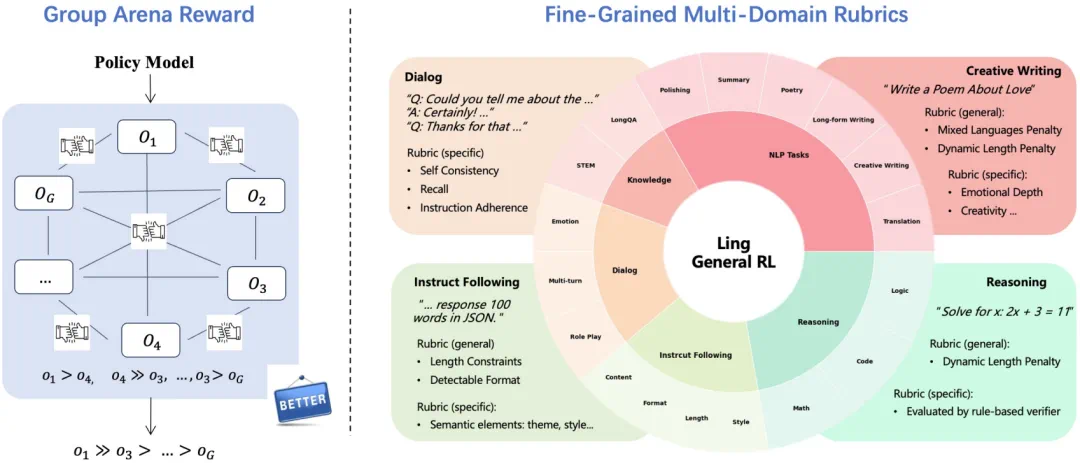
用于开放性主观任务的 GAR 机制
而支撑 LPO 和 GAR 运行的,则是一个强大的统一奖励模型系统(Reward Model System)。该系统可扩展性极强,能并发处理高达 40K 的异构奖励请求,无论是基于规则的、基于模型的、还是需要在沙箱环境中执行代码的复杂验证任务,从而可确保整个后训练流程的高效与稳定。
支柱四:基础设施 全栈 FP8 与 4C 工程学
万亿模型的训练终究是一场工程竞赛。Ling 2.0 报告分享了其支撑万亿参数稳定运行的基础设施,其中既有巨大的成功,也有坦诚的「教训」。
万亿规模的全链路 FP8 训练
Ling 2.0 系列的 Ling-1T 是目前已知最大规模的、完全使用 FP8 训练的开源模型。
这绝非易事。FP8 虽能大幅节省显存并提升计算速度,但其极低的精度会对万亿模型的稳定性构成致命威胁。Ling 团队通过细粒度逐块量化(fine-grained block-wise quantization)策略,结合 QKNorm 等新技术抑制训练中棘手的异常值(outlier)扩散,并辅以一个实时的 FP8 训练保障系统 (FP8 Training Safeguard System) 进行全时监控。
最终结果着实惊人:在 1T 模型和 900B 数据的规模上,FP8 训练达成了与 BF16 几乎一样的损失表现 (差距 ≤ 0.25%),同时模型算力利用率(MFU)提升了 15%,也即 FP8 可带来 15% 的端到端训练加速。这基本宣告了 FP8 在万亿模型训练上的可行性与经济性。
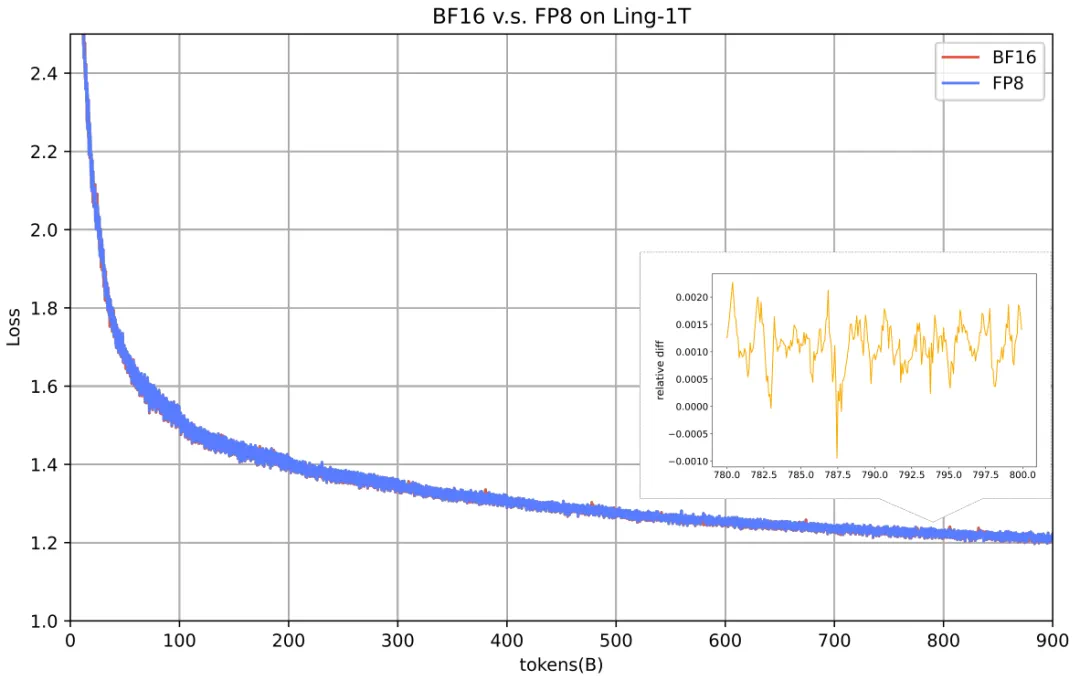
基于 Ling-1T 测得的 FP8 与 BF16 训练损失对比
异构架构的管线设计
Ling 2.0 的设计并非是均匀的层堆叠,它混合了 Dense(密集层)、MoE(稀疏层)和 MTP(多 token 预测) 等计算特性截然不同的模块,是一个典型的异构架构。
在管线并行(PP)训练中,这就好比一条装配线上有的工位快、有的工位慢,极易产生管线气泡(pipeline bubble),进而导致 GPU 集体「摸鱼」。
为此,Ling 团队设计了异构细粒度管线(Heterogeneous fine-grained pipeline)调度策略。该策略允许将 MTP 这样的复杂模块拆分,并支持在不同的管线并行阶段灵活分配不同数量的 Transformer 层,最终实现更均衡的负载分配。这种算法 - 系统协同设计成功将端到端训练吞吐量提升了 40% 以上。

5 个流水线并行阶段(PP rank)的 1F1B 与异构流水线调度对比示例。与基线方法 1F1B 相比,新方法可显著减少流水线气泡,从而大幅降低整体训练成本。
Ling 2.0 融合的创新还不止于此,Ling 团队还优化了包括节点内 DeepEP 通信、一系列融合算子、更快的专家层重计算以及高效的分布式检查点存储等诸多工程细节。更多详情请参阅原论文。
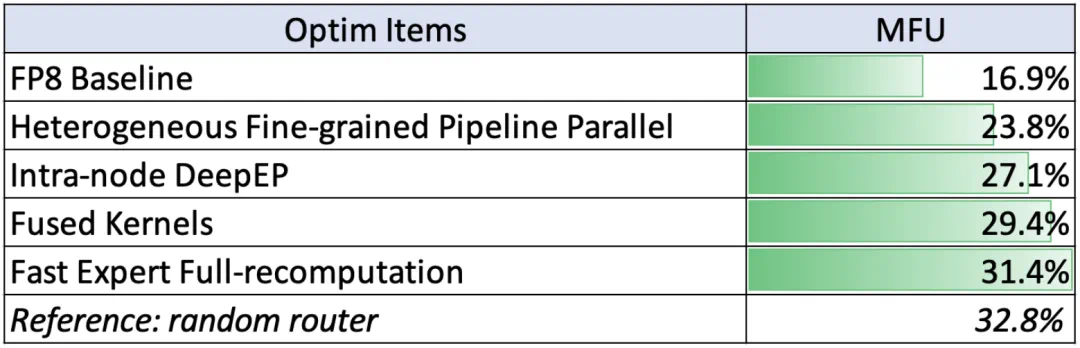
Ling 团队为 Ling-1T 在预训练阶段使用的各类优化任务概览
一个苦涩的教训
最后,Ling 2.0 技术报告坦诚地分享了一个苦涩的教训。这部分内容也是报告中最具「真・开源」精神的一大亮点。
Ling 团队回顾了他们在训练万亿规模 MoE 模型时的一次重要尝试:实现计算与通信的重叠(Computation–Communication Overlapping),这是长期以来被视为提升分布式训练效率的关键方向。他们试图通过 DualPipe 或 DeepEP 的 A2A(All-to-All)重叠技术,将专家计算的耗时隐藏在通信延迟背后。
然而,该报告称,尽管付出了巨大努力,最终的端到端加速收效甚微。
为什么会失败?Ling 团队给出了深刻的诊断:这些重叠策略需要配置一个非常大的专家并行(EP)规模才能获益;但这种配置难以应对 MoE 模型的一个「阿喀琉斯之踵」,即浅层 MoE 层的路由不均问题。
换言之,在模型的浅层,路由策略分配给不同专家的 Token 数量很不均衡。这会导致在采用大 EP 规模时,某些 GPU 上的某些管线阶段会因为承载了「热门」专家而内存溢出(OOM),系统被迫采用一种妥协的、非最优的管线划分策略,而这种妥协最终会吞没计算 - 通信重叠带来的所有理论收益。
这虽是个「失败」的结论,但却价值千金,因为它深刻地揭示了:在万亿参数规模下,任何试图忽视硬件和系统异构性(如路由不均)的纯算法优化,都可能在工程落地时彻底失效。真正的效率提升,必须建立在算法与系统的协同优化之上。
这一坦诚的失败分析为整个 AI 社区提供了宝贵的避坑指南,其价值不亚于一项成功的技术。它也引出了蚂蚁的 4C 工程哲学(Correct, Consistent, Complete, Co-Design),即必须在算法设计之初就与系统工程协同,才能构建出稳定、高效、可复现的万亿参数大模型。
不止于模型 这是一份构建万亿基座的开源 SOP
从万亿模型的设计蓝图 Ling Scaling Law 到行业首创的 LPO 句子级强化学习算法,再到全栈 FP8 的万亿训练实践,Ling 2.0 技术报告的透明度和深度,充分体现了蚂蚁集团在 AI 浪潮中真・开源的诚意与技术自信。
Ling 2.0 的发布,其价值已远超模型本身。它不再只是一个单一的模型系列,而是蚂蚁集团提供给开源社区的一套完整的、经过验证的、可从百亿扩展至万亿的 AI 基础模型 SOP(标准作业流程)。
在 AI 军备竞赛日益导向闭源和算力壁垒的当下,这样一份透明、详尽的「万亿模型作业流程」显得尤为可贵。它为社区展示了另一条 Scaling 路线:即通往 AGI 的道路不仅可以依靠无限的算力堆砌,更可以通过极致的工程(如 FP8)、精准的预测(如 Scaling Law)和创新的算法(如 LPO)来实现。
正如报告所展示的,Ling 2.0 只是一个强大的基座,其真正的潜力才刚刚开始释放:无论是已经大放异彩的 Ring 系列推理模型,还是探索极致效率的混合线性架构。
这份报告为整个社区探索更高效、更强大、更通用的智能体奠定了坚实的基础,也让我们看到了蚂蚁集团在 Scaling Law 时代下,坚定地走向开放与协作的技术决心。


