作者 | yannic
XNet-DNN 是微信高性能计算团队自主研发的一款全平台神经网络推理引擎。我们在 XNet 的 RCI 基础设施之上构建了全平台的 GPU LLM 推理能力。目前能够在:
Apple/NVIDIA/AMD/Intel/Qualcomm/MTK/Huawei 等主流硬件厂商的 GPU 上实现非常优秀的推理性能,能够支持在 Windows/Linux/MacOS/ios/Android/HarmonyOS 等操作系统上部署。本文深入解析该引擎的核心技术架构,以及在异构计算环境下的性能优化策略。通过与主流 LLM 推理框架(llama.cpp, 英伟达 TRT-LLM,苹果 MLX-LM 等)全面比较,XNet-DNN 在推理效率、内存占用以及包体大小等关键性能指标上均显著超越现有解决方案。

一、GPU 的跨平台统一:XNet-DNN 高效推理实践
大模型技术的规模化应用正呈现爆发式增长态势,持续驱动人工智能技术体系革新。在此背景下,XNet-DNN 推理引擎基于自主研发的 RCI(Render and Compute Interface)跨平台框架构建了跨平台的 GPU LLM 推理能力。该引擎目前已实现对 NVIDIA、AMD、Apple、Intel、Qualcomm、联发科、华为等主流硬件平台的全面支持。在推理效率、内存占用以及包体积等关键性能指标上均显著超越现有解决方案,为各业务线部署高效的 LLM 推理服务提供了强有力的支持。我们曾系统阐述过移动端 CPU 部署大模型的技术路径。本文作为该技术路线的延续,重点聚焦 GPU 加速场景下的 LLM 推理优化,从 RCI 框架的系统级优化到核心算子的极致调优,系统阐述实现大模型 GPU 推理极致性能的技术路径。本文末章给出了详实的对比实验数据,包括 QwQ-32B 模型的本地部署性能指标。
1. GPU 发展与现状
自 NVIDIA 于 1999 年发布首代图形处理器 GeForce 256 至 2024 年 Blackwell 架构问世,GPU 技术经历了 26 年技术演进。晶体管集成度从 68M 提升至 104B,单精度浮点算力增幅达 5400 倍,内存带宽扩展幅度超 95 倍。这种持续四分之一个世纪的技术迭代,使 GPU 完成从图形加速单元向人工智能核心计算架构的转变。值得关注的是,在 Blackwell 架构突破 14 PFLOPS 算力峰值的产业热点背后,以 Apple M 系列的 GPU、高通的 Adreno GPU、Arm 的 Mali GPU 为代表的移动 GPU 正推动计算范式发生结构性转变——人工智能加速架构不断向边缘侧大规模渗透。这些广泛分布的边缘计算设备,其架构差异性、能效约束性及内存局限性等特征,使模型部署面临多维度的挑战。
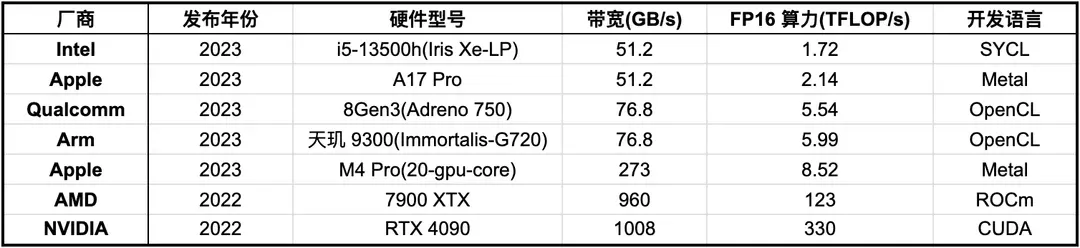
表1. GPU 硬件信息
表 1 展示了 GPU 生态的现状:
- 硬件性能差异巨大: 带宽差异达 26 倍; 峰值算力差距达 71 倍
- 硬件架构分化: NVIDIA 的 TensorCore 与 Adreno 的可编程着色器的计算架构分化; HBM3 与 LPDDR5X 的存储架构分化
- 编程生态碎片化: CUDA (NVIDIA)、Metal (Apple)、ROCm (AMD), OpenCL 等编程框架并存; 现代 GPU 特性支持情况各不相同
- 部署需求分化: 云端需支持千亿、万亿参数大模型的分布式计算; 移动端需要在 10 W 功耗下实现数十亿参数模型的实时推理
2. LLM GPU 推理现状
表 2 展示了目前 LLM 推理的现状,各框架部署能力各有千秋,很难找到一款高效的,支持全平台部署且适应实际业务场景的推理框架。
在此背景下,我们利用 RCI 完善的现代 GPU 特性支持,以及高效的编程框架,开发了全平台的 GPU LLM 推理引擎。同时,基于硬件性能上限,对核心算子进行极致优化,在各端都取得了非常优秀的推理表现。下文将从系统优化及算子优化两个维度阐述 XNet-DNN 是如何构建高性能的跨平台 GPU LLM 推理引擎的。

表2. 现有方案
二、突破 GPU 生态瓶颈:RCI 的系统优化之道
1. RCI 计算架构概览
GPU 开发领域当前面临显著的生态碎片化挑战,主要体现在以下三个技术层面:
- 首先,在驱动层存在多套编程标准。主流图形 API 包括跨平台的 OpenGL/Vulkan、Windows平台的 Direct3D、苹果生态的 Metal,以及面向通用计算的 CUDA/OpenCL。这些 API 在功能特性、执行模型和内存管理机制方面存在显著差异。
- 其次,kernel 编程语言也分化严重包括 GLSL、HLSL、MSL、CUDA C、OpenCL C 等,这些语言在语法规范、编译工具链和运行时支持方面缺乏统一标准。
- 最后,硬件指令集层面也存在明显分化。不同厂商 GPU 在计算单元设计、存储层级结构和特殊功能单元等方面采用不同的技术方案,例如 NVIDIA 在硬件上增加矩阵计算单元 (TensorCore),开发者可以使用对应的矩阵计算指令获得更高的矩阵计算算力, Apple 及 Arm 仅在软件层面支持矩阵计算指令(硬件没有添加矩阵计算单元),Qualcomm 不支持矩阵计算指令;另外,例如 shared memory 的支持在移动端 GPU 上普遍较差。这些差异导致开发者需针对特定硬件进行深度优化。
以上现状显著增加了 GPU 应用开发的复杂度,其情形类似于 CPU 领域早期需直接面向 x86、ARM 等不同指令集架构进行底层开发的困境。值得关注的是,在 CPU 领域已形成统一的高级语言编程体系(如 C++、Java 等),而 GPU 领域尚未出现具有同等普适性的高级工具。
针对这一技术瓶颈,RCI 框架构建了跨平台的 GPU 高级编程范式。
RCI 在 API 设计层面以接近原生 API 为宗旨,可以有效降低学习成本,同时要求运行时相对于原生 API 达到零开销。架构设计上充分考虑各 GPU 架构编程的最佳实践,保证开发者采用预计算,预编译状态与管线等方式提高 GPU 在渲染、计算等场景中的管线吞吐。RCI 的 Command Tape 机制就很好的诠释了这一特点,它能够以最高效的方式提交命令,节省 GPU 启动、驱动以及设备执行的开销,有效提高了管线吞吐,下文我们将详细介绍。
RCI 在 kernel 开发层面,借助自研的反编译器(其中 CL/CUDA/ROCm 反编译是业内首创)实现了高级语言到原生 kernel 语法的转换,避免了大量的重复开发工作,同时有效降低了包体积。为了实现高性能与通用性的平衡,RCI 支持开发者嵌入手工优化的原生 kernel 代码(MSL/CUDA C/OpenCL C)或者汇编代码(PTX/SASS/GCN),以实现特定硬件上的最佳性能。
值得强调的是,RCI 架构与 CPU 高级编程语言设计理念存在显著共性:在基础功能层,两者均采用高级抽象语言(C++ / RCI)保障开发效率与可移植性;在关键性能路径,则通过底层指令集(汇编/Native kernel)实现硬件级深度优化。二者均采用"通用框架+底层优化"的混合编程模型,有效平衡了通用性与高性能之间的矛盾,既提升了应用的跨平台开发效率,又能利用平台特性保持其高性能。图 1 展示了 RCI 计算部分的核心架构。
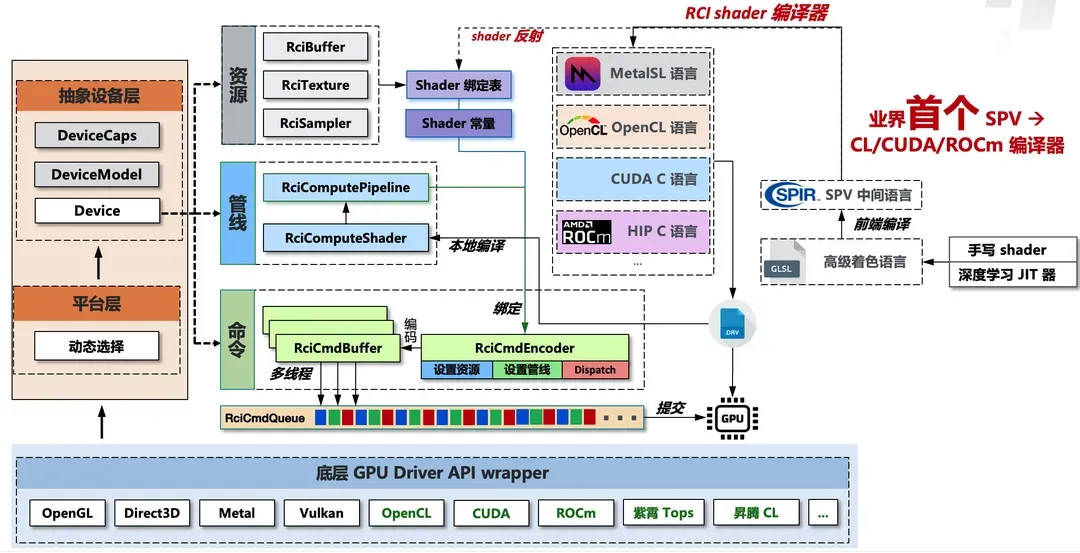
图1. RCI 计算架构概览
RCI 作为复杂系统设计领域的突破性创新框架,上文论述所揭示的仅是冰山一角。我们将在后续的文章中详细向大家展示 RCI 的全貌,以及其在系统优化中卓越的表现。
2. RCI 开发优势
从项目生态来看, llama.cpp 社区拥有近千名贡献者,其中代码贡献量超万行的核心开发者近 30 位,其硬件适配能力主要依赖厂商团队的直接投入,例如 Intel 和 Qualcomm 分别主导了 SYCL 与 OpenCL 后端开发,阿里巴巴等机构也参与其模型生态支持。然而,XNet-DNN 仅投入很少的开发资源实现了更广泛的 GPU 硬件覆盖与更优的推理性能,图 2 展示了 XNet-DNN 与开源项目 llama.cpp 的代码规模及开发者效率对比。
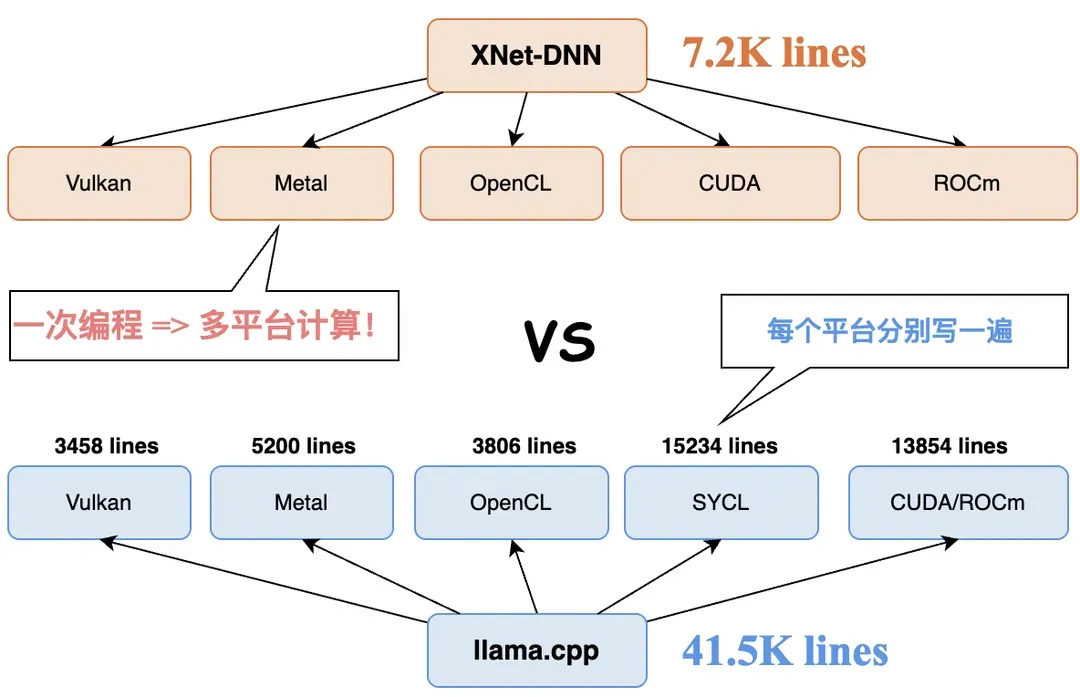
图2. XNet LLM(GPU) 与 LLama.cpp 代码量对比
我们能够以更少的人力完成更优秀的更全面的工作,其关键在于 RCI 架构设计的双重创新:
(1) 跨平台特性降低开发冗余
借助 RCI 的跨平台特性,框架实现仅需一套逻辑,有效降低框架代码量。kernel 部分,非核心计算逻辑(如内存布局转换)可借助 RCI 编写通用实现,无需针对各平台重复开发。大幅减少开发工作量,也有效降低了包体积。表 3 展示了 XNet-DNN 的包体积与其他主流推理框架的对比。对于移动端等包体积敏感场景,XNet-DNN 有巨大优势。

表3 包体积对比
(2) 差异化策略平衡性能与效率
RCI kernel 支持两种开发模式:采用高级语言编写跨平台通用 kernel,或使用原生语言(如 Metal Shading Language/CUDA C/PTX/SASS/GCN)编写硬件专用 kernel。对于硬件特性差异显著的核心算子(如矩阵计算),采用专用 kernel 实现极致性能;共性操作则通过通用 kernel 提升开发效率,实现了开发工作量与应用高性能之间的有效平衡。
凭借 RCI 优秀的框架设计,使我们得以聚焦核心算子的深度优化,最终以极小的人力规模完成对 Apple、NVIDIA、AMD、Intel、Qualcomm、Mali、 Maleoon 等主流 GPU 的覆盖并取得超越业界的性能,人效比远高于传统开发方式。
3. RCI Command Tape 特性
GPU 的执行需要宿主机 CPU 参与大量工作。CPU 作为主处理器负责逻辑调度和命令序列构建,通过总线向 GPU 设备提交结构化的命令队列。这种提交过程涉及指令预编译、资源绑定、内存屏障同步以及上下文状态的维护。以上是 CPU 提交 GPU 命令的核心机制。
在推理任务中,典型的执行流程是由多个 kernel 组成一个队列,每个计算帧执行相同的队列。在传统 GPU 执行机制下,每个计算帧都需要驱动层对队列中所有 kernel 执行完整的指令预编译和资源绑定流程,硬件指令缓冲区需要反复构建。这一过程 CPU 重复执行大量的相同任务,造成 CPU 负载及功耗显著增加,一些场景下计算管线的端到端延迟甚至受限于 CPU 性能。
RCI 的 Command Tape 技术有效解决了这一瓶颈。 该技术提供了一种跨平台的命令预录制机制,预先录制命令队列,指令预编译和资源绑定等操作只在预录制时执行一次,后续计算帧的处理,只需要提交预录制命令队列即可,有效降低 CPU 负载和功耗,也能够更好的提高 GPU 管线的吞吐。该技术实现了与 Metal 的 Indirect Command Buffer、NVIDIA CUDA Graphs 以及 Adreno Recordable Queue 等效的能力。
如图 4 展示了在轻量级模型的推理任务中,decode 过程使用 CommandTape 技术所带来的性能提升。。
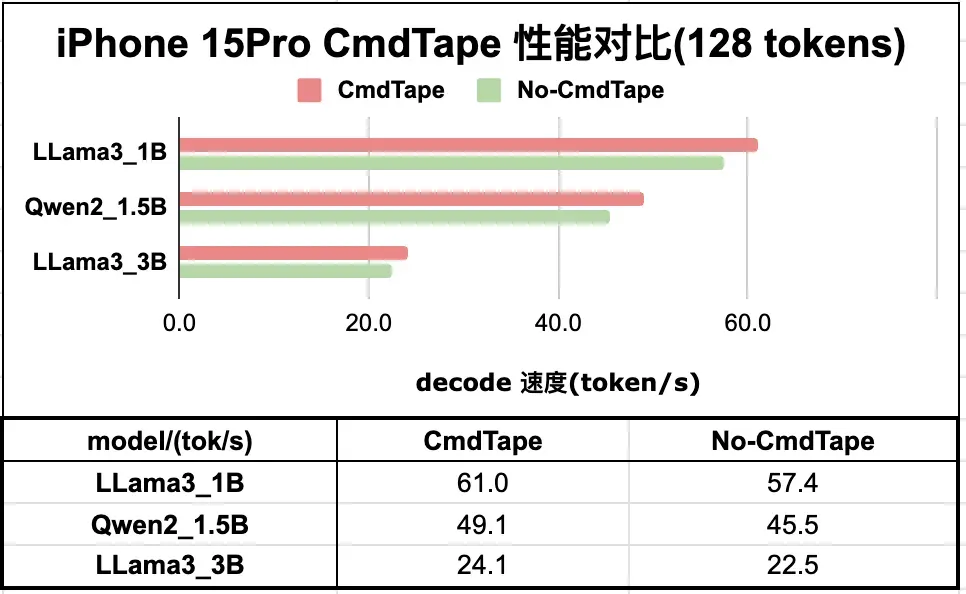
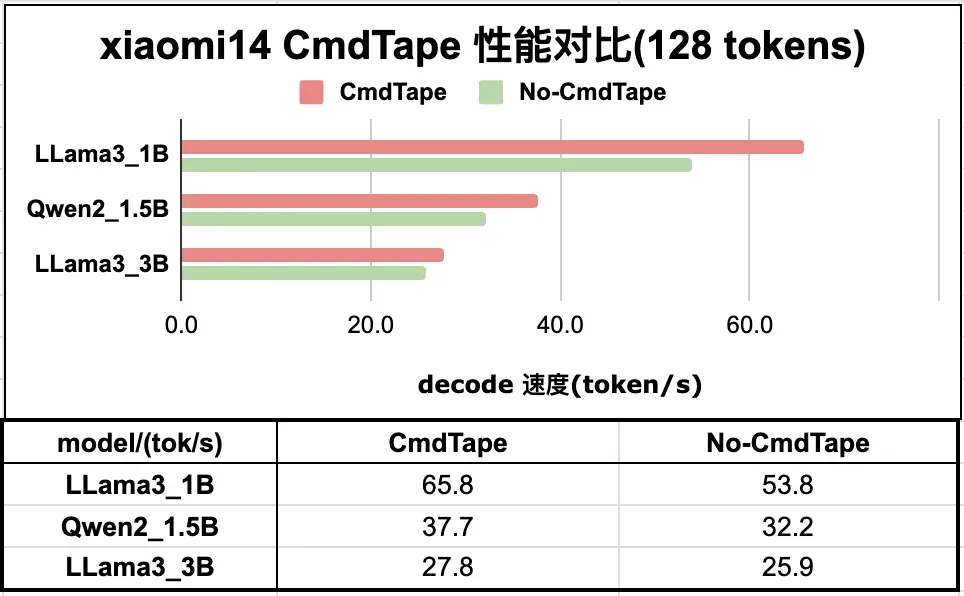
图4. Command Tape 在 iPhone (上) 及 Android (下) 设备的加速效果
三、榨取硬件潜能:核心算子的极致优化实践
所谓工欲善其事,必先利其器。凭借对各种计算硬件体系结构的深入理解和长期实战的经验总结。我们开发了一套微基准测试(Micro-benchmark)工具,它可以帮助我们准确获取硬件的算力峰值、各级存储结构的带宽以及延迟、指令吞吐、指令延迟以及一些硬件架构特点,这些信息大多数是硬件厂商不公开的,或者仅是理论数据。这些关键指标对于我们做性能优化非常关键,它可以帮助我们做数据排布,指令排布,实现最优的 pipeline 以获得最优的带宽利用率和算力利用率。同时,这套工具配合 Roofline 模型,可以快速准确的帮助我们定位到当前优化的瓶颈,以及当前优化距离最终目标还有多远。这套方法论让优化不再是玄学,所有的经验可总结,可借鉴,可复现,帮助我们能够有效的在不同的硬件上取得最优的性能。
1. 如何做算子优化
本节先简单介绍一下,如何通过硬件指标配合 Roofline 模型来指导优化。图 5 是根据 8 Gen2 的带宽和算力画出的 Roofline 模型。我们通过 Micro-benchmark 测出,GPU Memory 的带宽为 60 GB/s, shared memory 的带宽为 465 GB/s, FP16 算力为 4668.5 GFLOPs。纵轴是算力,单位为 GFLOP/s, 横轴为计算密度,单位是 FLOPs/Bytes。图中的紫色线条和蓝色线条代表算力随计算密度变化的趋势。紫色垂线表示,按照 shared memory 的带宽能力,要达到峰值算力,需要计算密度达到 10 及以上,蓝色垂线表示,按照显存带宽能力,要达到峰值带宽需要计算密度达到 77 及以上。以显存带宽衡量,当计算密度小于 77,该算子就属于带宽受限型算子,当计算密度大于 77, 该算子就属于算力受限型算子。
如果一个算子已经是算力受限型算子,那么说明已经优化到极致了,我们是无法突破算力天花板的。然而由于带宽更昂贵,绝大多数的情况,算子都会落在带宽受限区域,此时为了达到硬件峰值,优化方向有两个,其一是提高计算密度,其二是提高带宽。以矩阵乘法为例,增大矩阵分块,可以提高计算密度,这个过程中需要考虑寄存器数量限制,寄存器资源有限,过大的分块导致可能会导致 register spill,性能反而会大幅下降;提高带宽,则是通过使用 shared memory 以及提升 Cache 命中率,来降低访存延迟。除此之外,我们需要根据 Micro-benchmark 获取的计算及访存指令延迟数据,合理的排布访存指令和计算指令以达到相互掩盖延迟,实现软流水获得最优的吞吐。可见算子优化是一种平衡之道,在有限的资源中,探寻一种最优的平衡,访存指令与计算指令的平衡,寄存器占用与计算密度的平衡等等,为了实现这种微妙的平衡,准确的 Micro-benchmark 就显得尤为重要,Micro-benchmark 数据越精准,就越能接近极限平衡也就是达到最优性能,反之则只能南辕北辙。
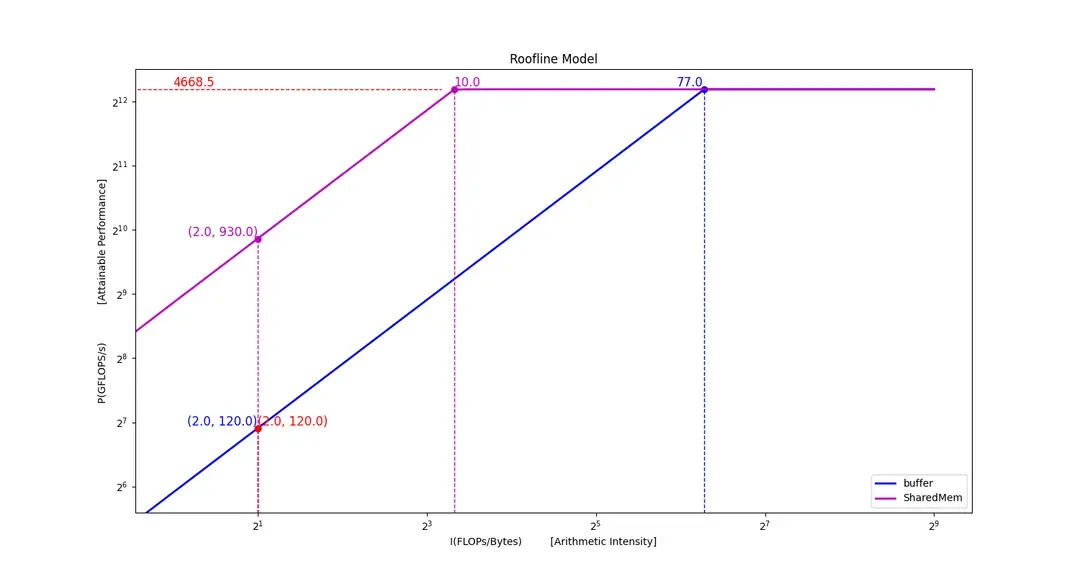
图5. Qualcomm 8 Gen2 Roofline
除了 Micro-benchmark 和 Roofline 之外,我们优化最重要的基础是计算机体系结构。只有深刻了解硬件的运行规则,才能凭借 Micro-benchmark 数据合理的分析瓶颈,配置资源;Roofline 则提供了一套评价机制,帮助我们衡量当前优化水准。
2. GEMM/GEMV 的优化
大语言模型的推理分为两个阶段,prefill 和 decode; 前者是对用户 prompt 的处理阶段,也就是 kv-cache 填充阶段,后者是 token 生成阶段。Decode 过程是迭代过程,每轮迭代生成一个 token,prefill 阶段可以进行批处理,一次运行填充多组 kv-cache。所以大语言模型的 prefill 和 decode 是两种不同类型的计算过程,prefill 阶段的核心计算是矩阵乘法(GEMM),decode 阶段的核心计算是矩阵向量乘(GEMV)。
从计算密度(Arithmetic Intensity)分析,GEMV 的理论上界为 2 FLOPs/Byte,GEMM 的计算密度则受分块策略影响,其上限由寄存器容量等硬件资源决定。因此二者的优化方向也大不相同。GEMV 的计算密度固定,属于纯带宽型算子,优化中需要关注带宽以及 GPU 的 occupancy, 在带宽方面需要满足最基础的访存合并,同时为了更优的 occupancy,一般需要数据重排,以满足 GPU 的访问模式。作为带宽型算子,最优实现是算子耗时与最大带宽情况下的数据读写耗时相当,也就是说,访存延迟完全掩盖了计算延迟。我们知道,GPU 是通过大量 warp 并行执行,通过访存和计算的相互掩盖以保证硬件单元的持续繁忙,那么在 GEMV 的优化中除了考虑数据排布的最优,还需要考虑 GPU occupancy,常见的方案如 split k 等,下文介绍的 shuffle 指令就可以避免数据交互,有效加速 K 方向的 reduce 计算。GEMM 的优化则更加复杂,前文已经对 GEMM 优化的方向及核心要素有了详细介绍,这里就不再展开。深度优化本身也是对基础优化技巧和理论的的深度实践,所以本节接下来会从硬件层级结构,如何提高GPU 并行度和带宽优化等方面来向大家介绍一些基础的优化技巧。
(1) 硬件层次结构
GPU 的体系结构具有双重层次特征:存储层次(Global Memory → L1/L2 Cache → Shared Memory → Register)与计算层次(Grid → Block → Warp → Thread),另外现代 GPU 普遍集成矩阵计算单元(如 NVIDIA TensorCore)。所以 GPU 的优化也需要按层次展开:
① Warp 级别:矩阵计算单元以 warp 为执行粒度,数据从 Shared Memory 加载至寄存器供计算单元使用。此层级的优化目标包括:
- 设计合理的 warp 级矩阵分块策略,提升计算密度,需注意寄存器的合理使用
- 消除 Shared Memory 的 bank 冲突(例如通过数据交错存储)
- 增加指令数量,满足计算单元吞吐;
② Block 级别:数据流动路径为 Global Memory → Shared Memory。优化重点包括:
- 根据 Shared Memory 容量和 warp 资源占用,划分 block 内 warp 数量
- 平衡计算与访存任务,最大化 warp 算力利用率
- 注意保证 GPU 合理的 warp 并行度,避免并行度不足导致性能退化
③ Grid 级别:通过数据重排提升 Global Memory 访问效率,同时优化 block 调度顺序以提高 L2 Cache 命中率,最终实现全局性能最优。
(2) 提高并行度
GPU 的高吞吐依赖大规模 warp 并发执行。当单个 warp 因资源占用过高(寄存器/ SM 资源)导致 SM 上并发 warp 数下降时,将产生 ALU 闲置。如图 6 所示,warp 数量从 1 增至 3 可有效掩盖访存延迟,并尽可能保持算力单元的繁忙。但 2 个 warp 时 ALU 仍存在空闲周期。另外,例如指令依赖也会导致可调度 warp 数量下降造成资源闲置,所以在优化中需要很好关注 profiler 工具提供的相关参数,避免出现这种情况。除了以上优化层面造成资源闲置外,还有一些算法或者计算数据层面造成的 warp 并行度低的情况,例如矩阵计算中小 M、N 大 K 的情况,如果不仔细处理就会导致并行度低。这些 case 也都有一些成熟的方案来解决,例如 split K 算法,并行的 reduce,都是为了处理这些情况。
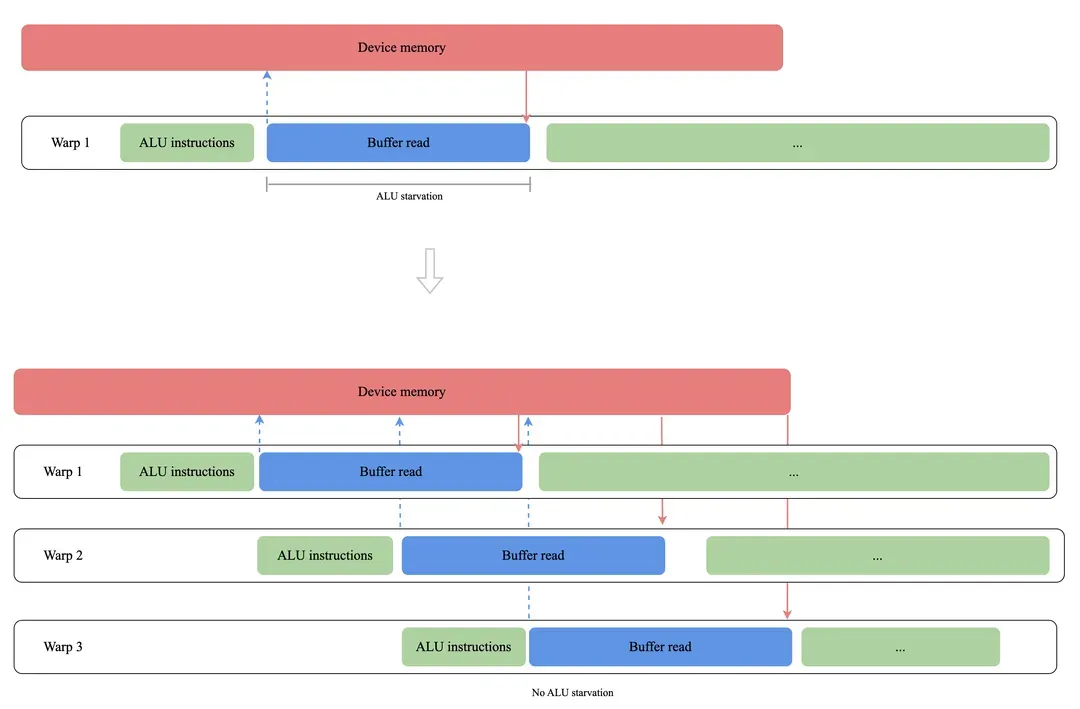
图6. 提高 GPU Occupancy
除了以上的方法外,这里介绍两种,硬件机制层面的方案,其一是 Apple/Arm GPU上采用 subgroup matrix 技术,它提供的软件矩阵乘指令(类比 TensorCore),不增加硬件计算单元,但是可以降低寄存器占用,从而提升 warp 并行度。其二是 Apple 针对 M3/A17 芯片的 Dynamic Caching 技术,它运行时动态分配寄存器 / Cache 资源(图 7),减少静态分配造成的资源碎片,提升 SM 并发 warp 数量。这两种方案都以较小的成本,进一步压榨硬件性能,相比于一些厂商不考虑软件的算力利用率,大幅度堆计算单元要高明的多。
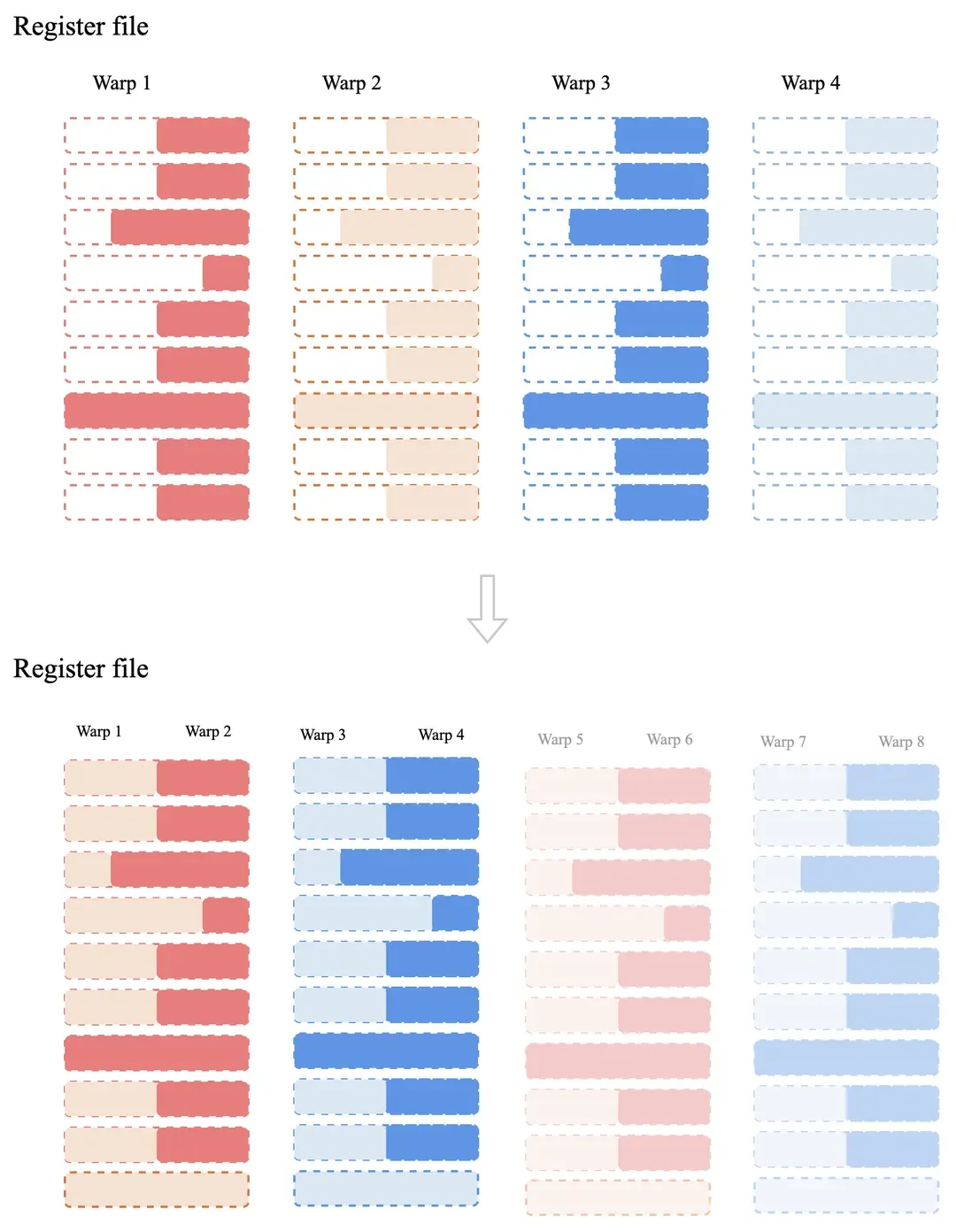
图7. 寄存器动态分配示意图
(3) 带宽优化
带宽优化需贯穿存储层级各环节(Global Memory → Shared Memory → Register),核心方法包括:
① Shared memory 带宽优化
- Bank冲突规避:通过数据重排、交错访问消除冲突
- 直存指令优化:使用 ld.global 指令直接加载数据至 Shared Memory,规避寄存器中转
② 数据通路加速
- Shuffle 指令:利用寄存器间数据交换加速 Reduce 操作
- 双缓冲预取:实现 GEMM 计算与数据加载的流水线重叠
③ 合并访问优化
- 合并访问:确保 warp 内线程访问连续对齐内存块
- Thread Block Swizzle:通过 Z 型映射调整 block调度顺序(如图 8 所示),让数据拥有更好的局部性,提升 L2 Cache 命中率
- 硬件 Cache 策略:在高通平台优先使用 Texture,因为 Adreno GPU 只有 Texture read 可以使用 L1 cache,所以使用 Texture 可以提高数据访问效率。除此之外,Texture2D 数据结构的 cache 是块状的,因此在数据访问模式设计中,与 buffer 就有所不同,需要按照块状设计数据的局部性。
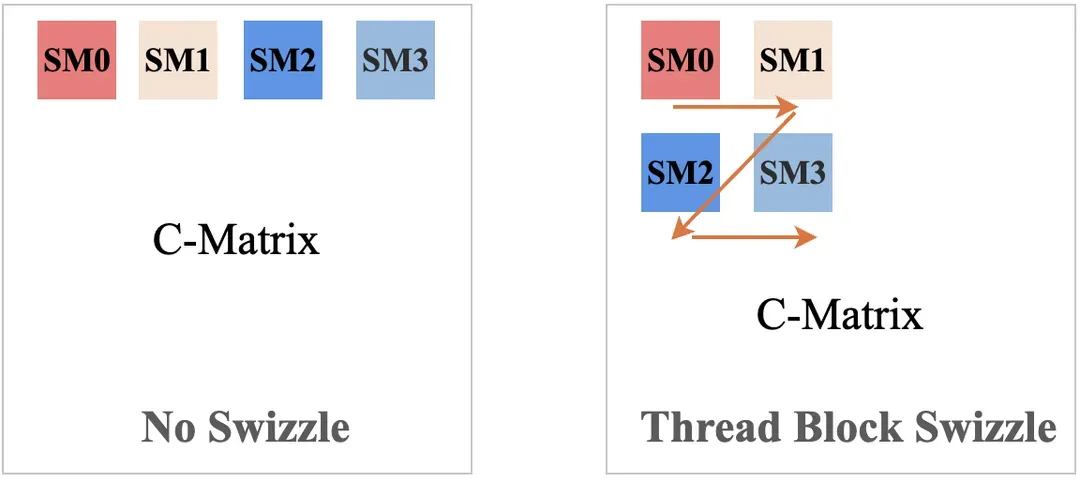
图8. Thread Block Swizzle 示意图
(4) 其他优化手段
要对 GPU 进行极限优化,硬件逆向和指令逆向是不可或缺的手段。通过逆向可以获取更多硬件信息,可以帮助我们在指令重排,数据排布等方面提供更多的参考和指导。尽管主流 GPU 厂商(Apple/NVIDIA/AMD/Intel/Qualcomm/Arm/Mali/Maleoon 等)均提供基础开发文档,但涉及性能敏感的核心机制如指令流水线设计、缓存替换策略、寄存器动态分配算法等关键细节仍处于保密状态。通过系统化的逆向工程,我们可以深度掌握指令延迟特性,微指令调度策略,指令吞吐等硬件信息。另外通过一些重要专利,也可以对硬件实现的细节有一定的了解,帮助我们制定更优的优化策略。
3. FlashAttention-2
当前基于 Transformer 架构的 LLM 面临显著挑战:随着输入序列长度的增加,其核心组件 self-attention 模块的时间与空间复杂度呈二次方增长。为突破这一瓶颈,斯坦福大学与纽约州立大学布法罗分校 Tri Dao 团队提出的 FlashAttention 算法,通过创新的内存高效计算策略,在保持计算精度的前提下显著提升了注意力机制的运算速度并降低了内存占用。
FlashAttention 的底层实现基于 NVIDIA 研究人员 Maxim Milakov 和 Natalia Gimelshein 于 2018 年提出的 Online Softmax 分块计算技术。由于 FlashAttention-1 在工程实践中存在循环顺序优化不足的性能缺陷,FlashAttention-2 通过以下三大改进实现了突破性优化:
(1) 矩阵计算单元优化
通过改进 rescale 操作减少非矩阵乘法运算(non-matmul FLOPs)。鉴于现代 GPU 中矩阵计算单元的吞吐效率显著高于通用浮点计算单元,这种优化策略能有效提升整体计算效率。
(2) block 级别优化
将 block 划分维度从原有的 batch_size 和 num_heads 扩展至包含 seq_len 方向的三维划分。具体实现通过将 Q 矩阵置于外循环,使并行计算单元能在序列长度维度展开,显著提升小批量场景下的 GPU 资源利用率。
(3) warp 级优化
如图 9 所示,通过重构 Q/K/V 矩阵的循环访问顺序:将 Q 矩阵划分到 4 个 warp 同步访问 K/V 矩阵,避免原方案中反复读写 shared memory 及 warp 同步带来的性能损耗。这种改进使中间结果无需暂存于共享内存,同时降低线程束间的通信开销。
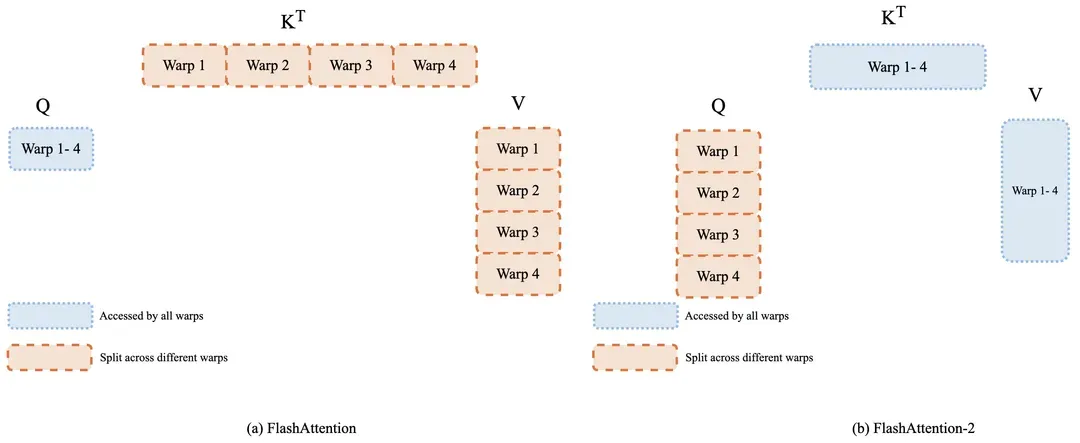
图9. FlashAttention-2 warp 划分
在 XNet-DNN 框架中实现的 FlashAttention-2 算法已成功应用于长上下文业务场景,实测显示其能有效提升计算速度达 3 到 8 倍。需要说明的是,虽然后续发布的 FlashAttention-3 针对 Hopper 架构进行了特定优化,但因其硬件适配范围受限,当前 XNet-LLM(GPU) 引擎暂未集成该版本, 但是同样的,我们也针对 Apple GPU 等其他 GPU 实现了定制优化的 FlashAttention 算法。
四、性能实测:XNet-DNN 多平台性能图谱
本次测试主流 LLM 推理引擎为llama.cpp(SHD-1: 916c83bf), MLX(version: 0.24.2),MLX-LM(version:0.22.4), MLX-Swift(version:0.21.2), mlc-llm(SHD-1: 9d798acc), TRT-LLM(version 0.16.0)。
测试平台包括 Apple 的 M1 Pro 和 iPhone 15Pro 两款设备。NVIDIA 的 RTX 3060 显卡。Qualcomm 的 8Gen3 芯片以及 Intel ultra7 155H 的集成显卡。我们测试模型如无特殊说明,均为 4bit 量化版本。
1. Apple GPU LLM 性能对比
本小节主要展示 XNet-DNN 在 Apple GPU 平台的性能,测试设备包含 M1 Pro 和 iPhone 15 Pro。M1 Pro 上,prefill 性能我们领先最优 LLM 推理引擎 14% - 22% 不等;decode 性能领先最优 LLM 推理引擎 6% - 14% 不等。iPhone 15 Pro 上,prefill 性能我们领先最优 LLM 推理引擎 7% - 35%;decode 性能领先最优 LLM 推理引擎 5% - 12%。
(1) M1 Pro GPU 性能对比
图 10 和 图 11 分别展示了 XNet-DNN 在 M1 Pro GPU 上与主流 LLM 推理引擎的 prefill 及 decode 性能对比。
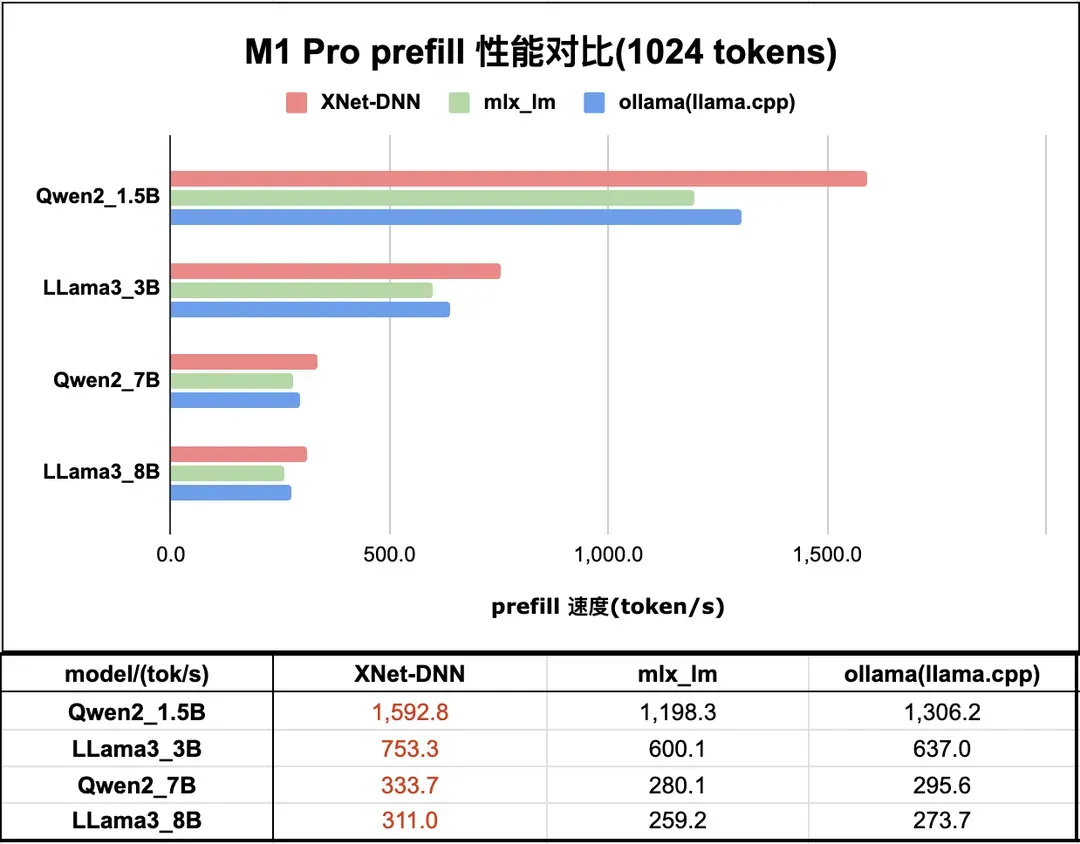
图10. M1 Pro LLM 推理 prefill 性能测试
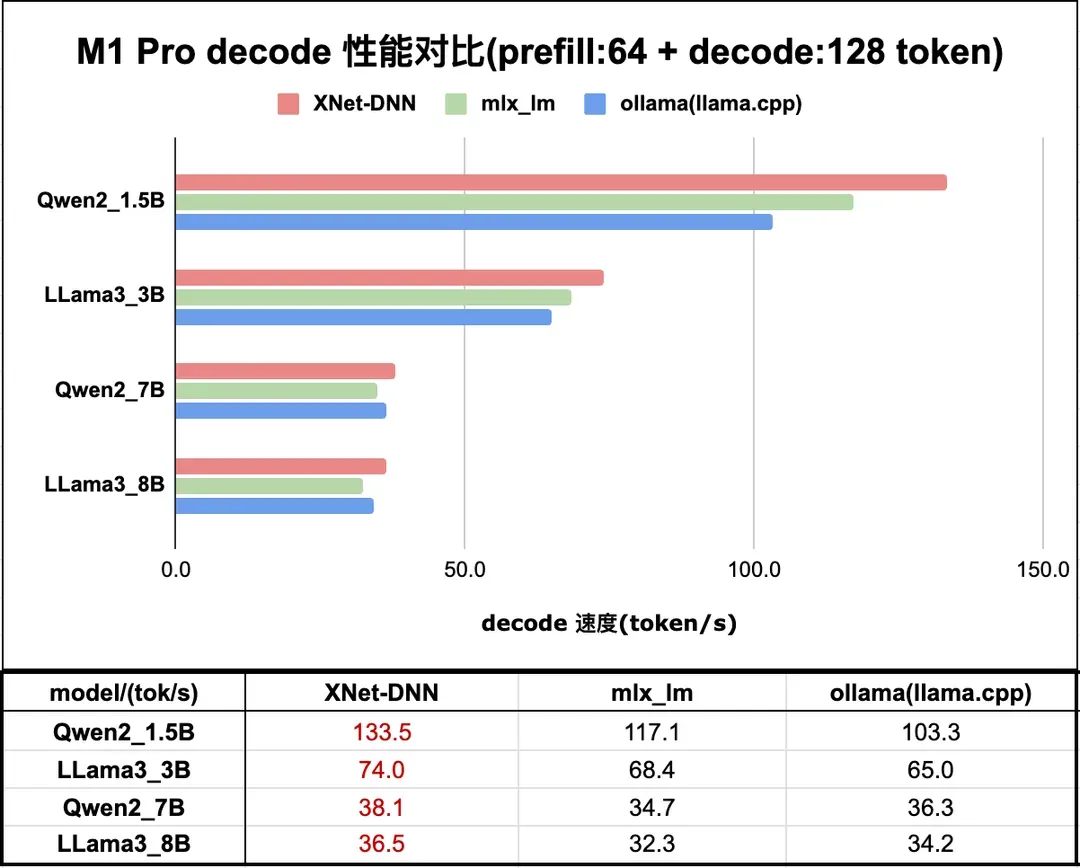
图11. M1 Pro LLM 推理 decode 性能测试
除了以上端上经典尺寸的模型测试,鉴于 M1 Pro 内存空间大的特性,我们也在 M1 Pro 上部署了最近很火的 QwQ-32B Q40 量化版本(4bit 量化版本需要 17G 左右的内存),获得了很好的体验。图 12 和 图 13 分别展示了与主流 LLM 推理引擎的性能对比。Prefill 计算相对于主流 LLM 推理引擎,我们拥有巨大优势。
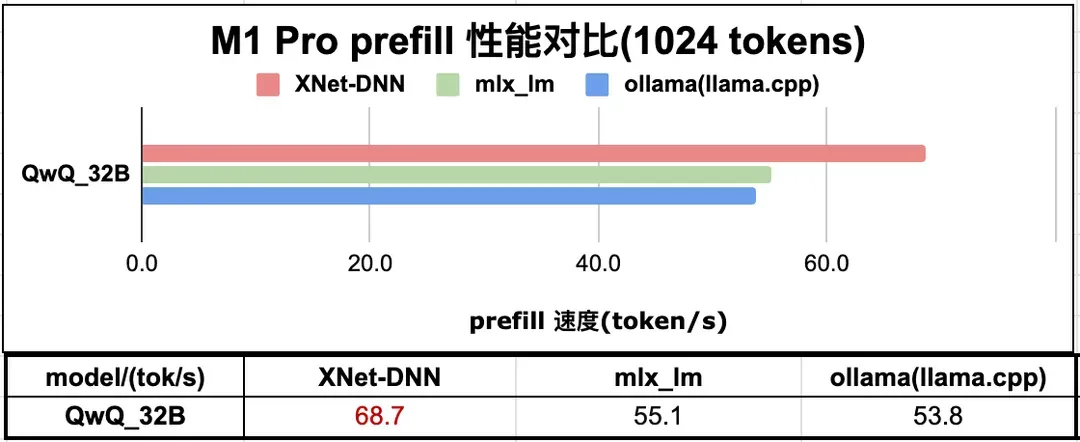
图12. M1 Pro LLM QwQ-32B 推理 prefill 性能测试

图13. M1 Pro LLM QwQ-32B 推理 decode 性能测试
(2) iPhone 15 Pro GPU 性能对比
图 14 和图 15 分别展示了 XNet-DNN 在 iPhone 15 Pro GPU 上与 LLM 推理引擎的 prefill 和 decode 性能对比。
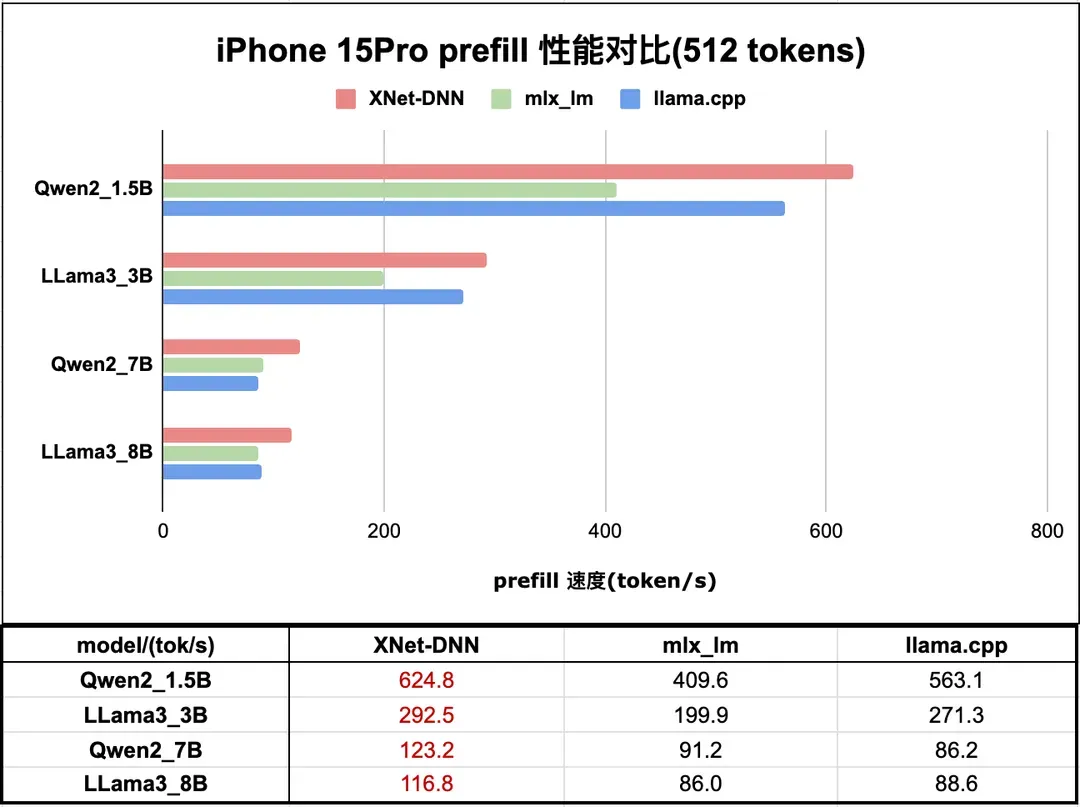
图14. iPhone 15Pro LLM 推理 prefill 性能测试
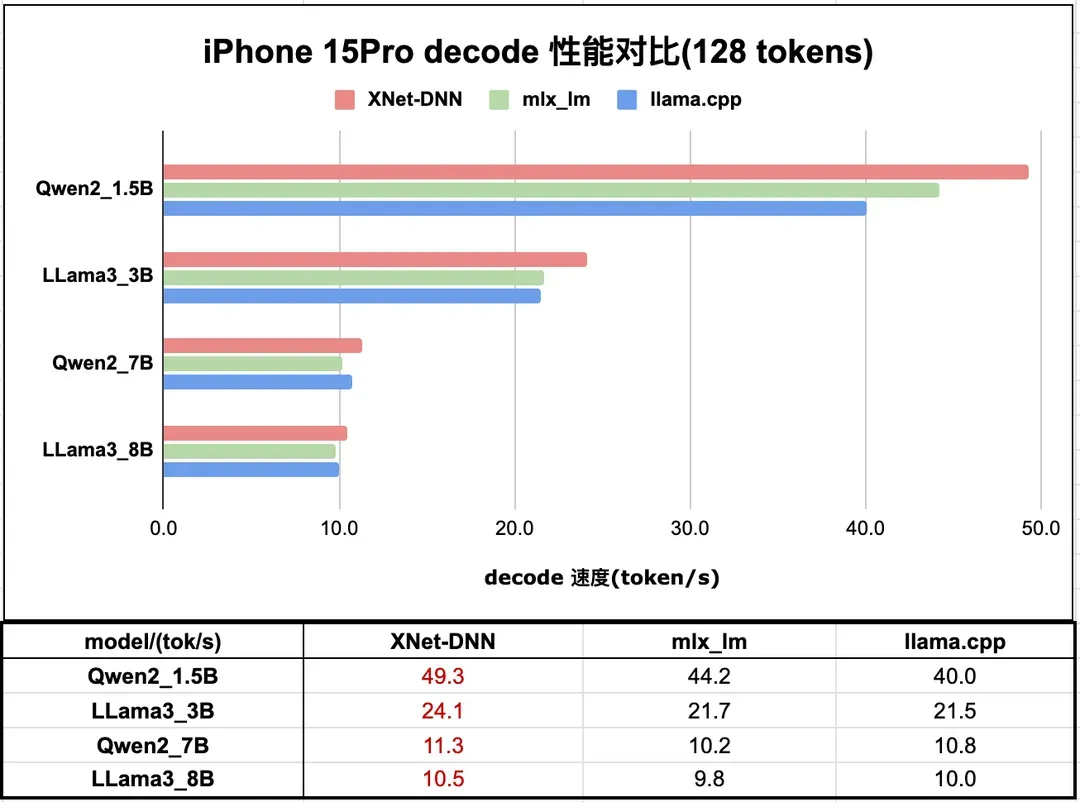
图15. iPhone 15Pro LLM 推理 decode 性能测试
2. NVIDIA GPU LLM 性能对比
本小节展示 XNet-DNN 在 NVIDIA GPU 上的性能。测试设备是 RTX 3060。XNet-DNN Prefill 性能领先最优 LLM 推理引擎 32% - 55% 不等;Decode 性能领先最优 LLM 推理引擎 6% - 21% 不等。
图 16 和 图 17 分别展示了 XNet-DNN 在 RTX 3060 上与 主流 LLM 推理引擎的 prefill 和 decode 性能对比。
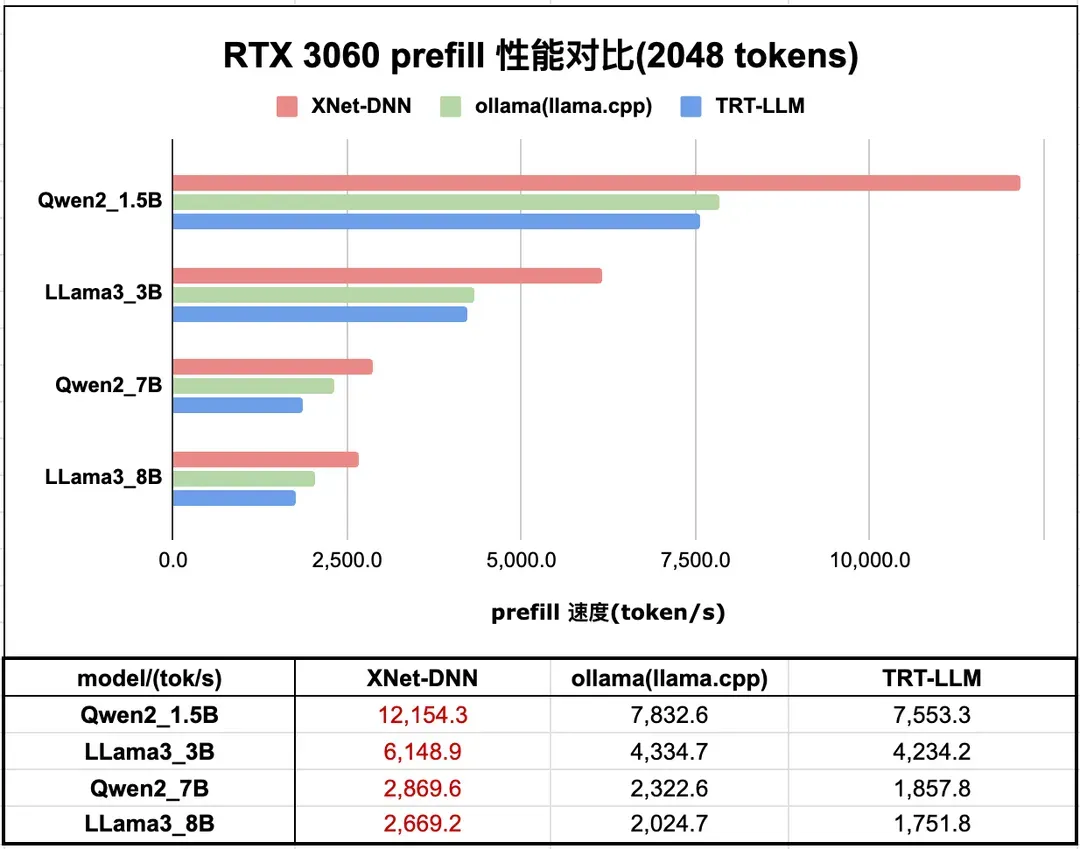
图16. RTX 3060 LLM 推理 prefill 性能测试
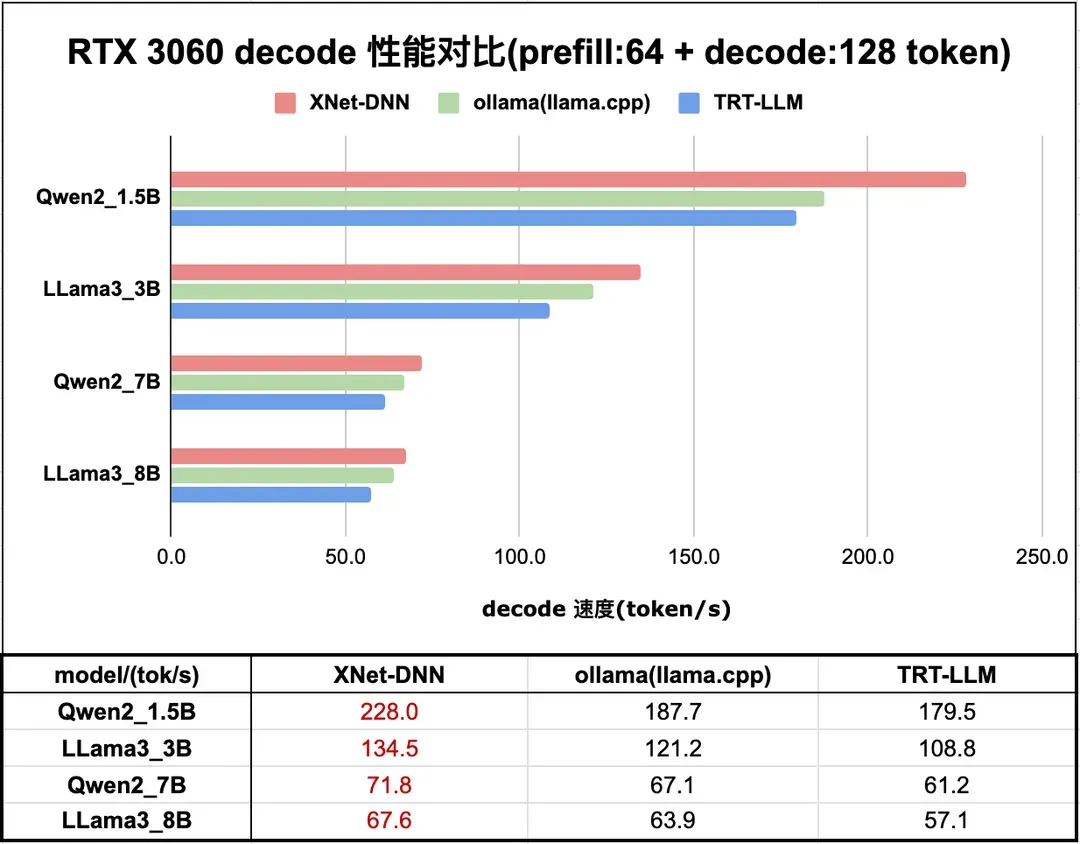
图17. RTX 3060 LLM 推理 decode 性能测试
3. Qualcomm/Intel GPU LLM 性能对比
本节对高通及英特尔集成显卡平台的大语言模型推理性能与行业 主流 LLM 推理引擎进行对比分析。需特别说明的是,除前述显卡系列外,XNet-DNN 还完整支持 Mali 架构 GPU 及华为 Maleoon GPU 等主流端侧 GPU。
当前行业对大模型推理的优化研究主要集中于 NVIDIA CUDA 架构及 Apple Metal 生态的高性能计算设备,此类平台凭借其突出的算力水平、较大的显存和显存带宽以及庞大的用户群体,成为算法落地的重要目标平台。
受此技术路径影响,现有 主流 LLM 推理引擎方案对 Intel/Qualcomm/Mali/Maleoon 等 GPU 的支持普遍存在显著局限性,部分实现方案为追求运算速度过度压缩计算精度,导致输出结果不可靠甚至存在系统性误差。
基于上述技术背景,本节选取具有代表性的移动端平台(高通骁龙 8Gen3 移动平台/Android 系统)及桌面端平台(英特尔 Ultra7 155H 处理器/集成显卡)进行 decode 性能数据展示。从测试数据看,XNet-DNN 在相关平台依然有绝对性能优势。欢迎有兴趣或者有业务落地需求的朋友共同探讨,共同推进端侧 AI 应用的技术探索与落地实践。图 18 和图 19 展示了 XNet-DNN 在 8Gen3 及 Ultra7 155H 与 主流 LLM 推理引擎的性能对比。
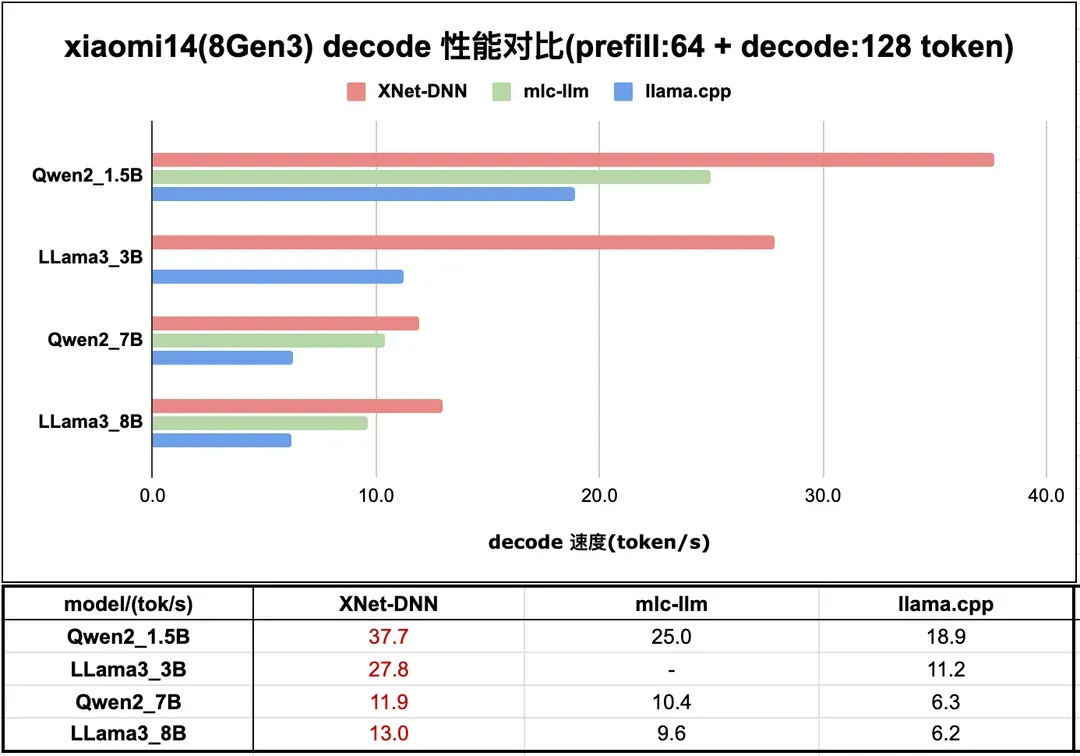
图18. 小米 14 (8Gen3) LLM 推理性能测试
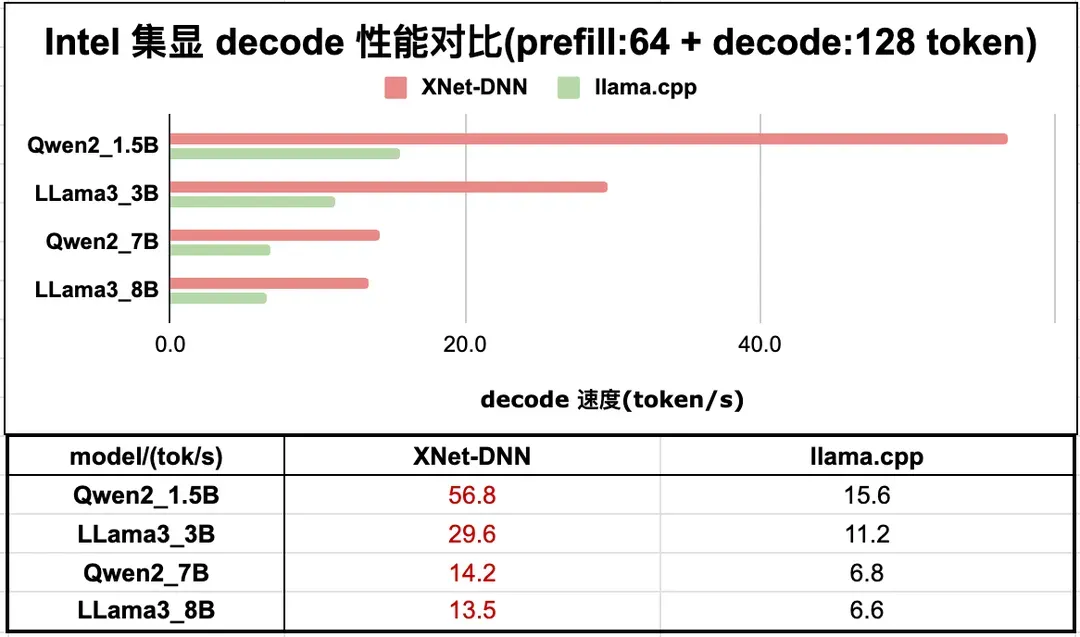
图19. Intel ultra7 155H 集显 LLM 推理性能测试
针对英特尔 Ultra7 155H 处理器的 Arc 架构集成显卡单元,XNet-DNN 推理引擎展现出 104%-265% 的性能优势。需说明, 主流 LLM 推理引擎 llama.cpp 在 Intel 平台采用 SYCL 异构编程框架实现推理加速,其技术实现由 Intel 工程师团队完成,属于该平台专业级解决方案。故本次测试仅选取 llama.cpp 作为核心对标方案进行评估。
五、总结展望
经过不断的开发迭代,以及在多个业务中的锤炼,目前 XNet-DNN 在推理性能、跨平台一致性、部署稳定性、包体积等方面优势已经非常明显。在未来的开发中我们将从以下几个方面进一步优化完善 XNet-DNN,以期获得更优的性能,持续保持领先,同时更好的更多的支持业务落地,持续赋能相关业务。
- 持续跟进大模型最新技术,保证相关技术能快速落地赋能业务
- 持续支持更多 GPU 平台,支持国产化
- 进一步探索性能优化方案,压榨硬件性能
- 完善业务场景中的各种 feature 支持
除了以上方向之外,当前大模型的部署包括软硬件生态以及模型等都在蓬勃发展中,我们也将持续跟踪最新发展情况,保持 XNet-DNN 在各个方面的持续领先。


