过去十年,人工智能的突破几乎都发生在“去身化”的语境中。无论是自然语言处理的GPT 系列,还是计算机视觉的 ViT、SAM,它们大多存在于数据与算力的虚拟空间里,擅长处理符号、文本和图像,却与真实世界的物理交互保持着距离。这样的 AI 可以写诗、画画、回答问题,却无法真正走进现实,理解环境、操纵物体、与人类并肩完成任务。
具身人工智能(Embodied AI)的出现,正是对这一局限的回应。它强调智能体必须“有身有感”,不仅能理解语言和符号,还要能感知环境、做出决策,并通过行动改变世界。换句话说,具身智能是让 AI 从“纸面上的聪明”走向“现实中的能干”。
9 月25 日,arXiv 发表由清华大学与复旦大学学者联合撰写的综述论文《Embodied AI: From LLMs to World Models》,正是对这一领域的系统性梳理。作者们聚焦于三类核心技术:大语言模型(LLMs)、多模态大模型(MLLMs)以及世界模型(World Models),并探讨它们在具身智能中的作用与互补关系。文章不仅总结了过去几十年的发展脉络,还提出了未来研究的关键方向,试图为通用人工智能(AGI)的落地描绘一条清晰的路径。
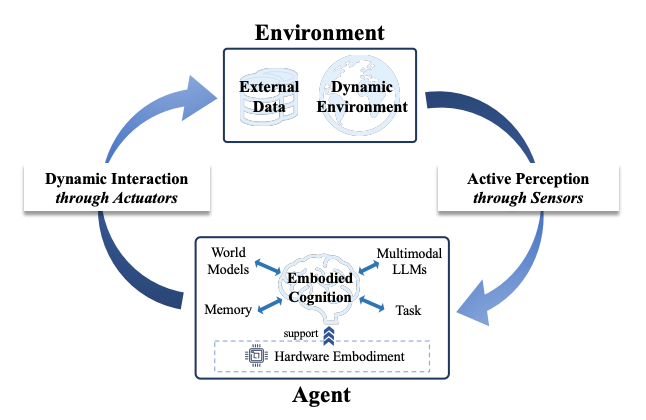 图1:体现AI的概念。
图1:体现AI的概念。
研究团队本身也颇具分量。第一作者Tongtong Feng与通讯作者Wenwu Zhu均来自清华大学计算机科学与技术系,同时隶属于北京信息科学与技术国家研究中心;Xin Wang是 IEEE 会员,长期从事多媒体与跨模态智能研究;Yu-Gang Jiang则是复旦大学可信具身智能研究院的领军学者,IEEE 会员在计算机视觉与多媒体领域有广泛影响力。可以说,这是一支兼具理论深度与应用视野的顶尖团队。
1.具身人工智能的理论根基与发展脉络
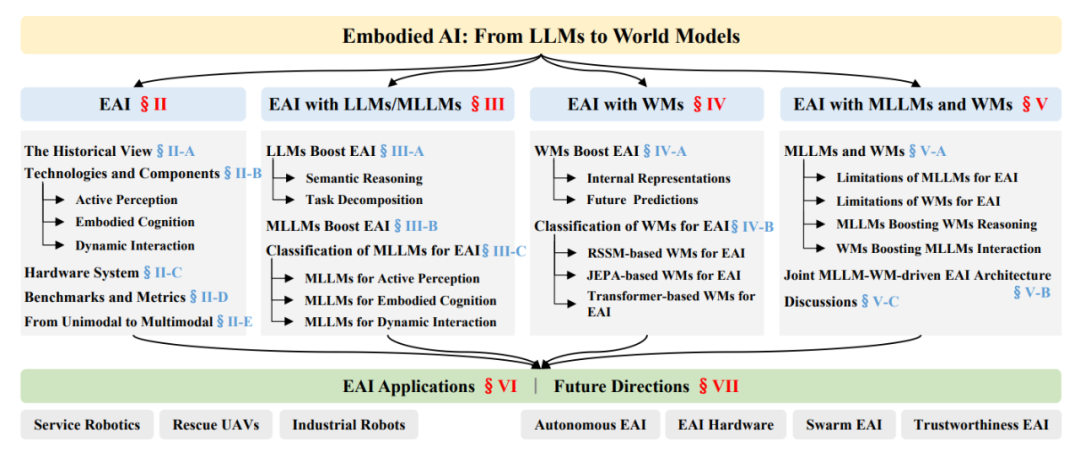 图片
图片
图2:本文全面介绍了实体化人工智能(EAI)的基础知识以及基于LLM/MLLM和WMs的EAI的最新进展。MLLM支持上下文任务推理,但忽略了物理约束,而WMs擅长物理感知仿真,但缺乏高级语义。基于上述进展,本文提出了一种联合MLLM WM驱动的EAI架构。
要理解具身智能的今天,必须回到它的思想源头。早在 1950 年,图灵就提出了“具身图灵测试”的设想:如果一台机器不仅能在对话中“冒充”人类,还能在物理世界中表现出与人类相当的感知与行动能力,那么它才算真正具备智能。这一设想在当时或许显得超前,但它为后来的研究埋下了伏笔。
到了 20 世纪 80 年代,认知科学家如Lakoff 和 Harnad 提出了“具身认知”的理论。他们认为,人的思维并非抽象的符号操作,而是深深扎根于身体经验与环境互动之中。换句话说,认知离不开感官与行动。AI 若要真正理解世界,也必须“具身”。
技术的发展路径大致可以分为三个阶段。20 世纪 80 到 90 年代,研究者们尝试通过行为控制与机器人架构来实现简单的具身智能,例如 Brooks 提出的分层控制架构。这一时期的系统往往依赖规则与有限的感知能力,功能单一。进入 2000 到 2010 年代,深度学习的兴起极大提升了感知与控制的能力,机器人能够识别更复杂的环境,并在一定程度上自主决策。然而,它们仍然缺乏通用性与跨任务的迁移能力。
真正的转折发生在 2020 年代。大语言模型(LLMs)展现了惊人的语义理解与推理能力,多模态大模型(MLLMs)则让 AI 能够同时处理语言、图像、视频等多源信息。而世界模型(World Models)的提出,则让智能体能够在内部模拟环境、预测未来,从而在不直接试错的情况下学习复杂行为。这三类技术的结合,为具身智能的突破提供了新的可能。
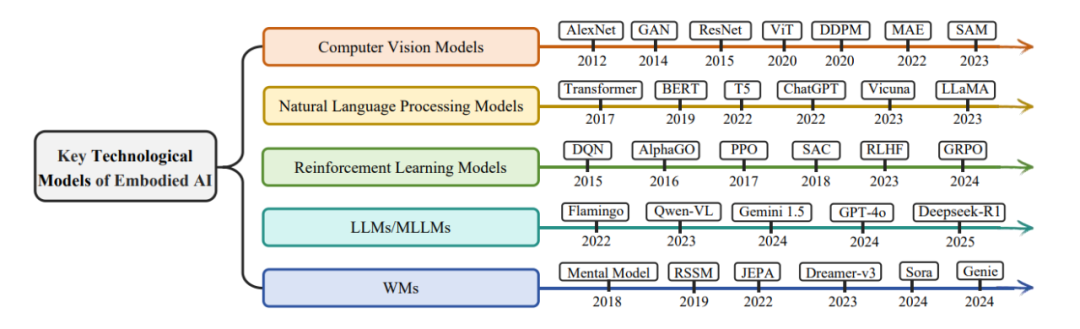 图片
图片
图3:具身人工智能的关键技术模型。计算机视觉(CV)模型、自然语言处理(NLP)模型、强化学习(RL)模型、LLM/MLLM和WMs的进步推动了具身人工智慧的进步。
具身智能的核心特征可以概括为三个方面。首先是主动感知,即智能体不再被动接收信息,而是能够主动探索环境、选择视角、构建场景理解。其次是具身认知,它要求智能体能够在任务驱动下进行规划,利用记忆进行反思,并在多模态信息中形成统一的理解。最后是动态交互,意味着智能体不仅能执行动作,还能与环境、其他智能体乃至人类进行复杂的协作与博弈。
2.具身智能的三大核心模块
研究团队把具身人工智能拆解为三个紧密相连的核心模块:主动感知、具身认知与动态交互。它们共同构成了一个智能体在现实世界中“看、想、做”的完整闭环。
主动感知:从被动接收走向主动探索
如果说传统的计算机视觉更像是“睁眼看世界”,那么具身智能中的主动感知则是“带着目的去看”。这意味着智能体不再只是被动地接收图像或传感器数据,而是会主动选择观察角度、移动位置,甚至通过探索来获取更有价值的信息。
在技术路径上,SLAM(同步定位与建图)是最基础的能力,它让机器人能够在陌生环境中一边移动一边绘制地图。经典的 ORB-SLAM 就是这一领域的代表。
而随着场景复杂度的提升,研究者们开始引入 3D 场景理解方法,例如 Clip2Scene,可以将视觉输入转化为结构化的三维语义场景。更进一步,主动探索方法如 Active Neural SLAM 则让智能体具备了“好奇心”,能够在未知环境中自主寻找信息增量最大的路径。
趋势已经非常明确:从最初的几何建模,到语义理解,再到如今的多模态跨模态感知,主动感知正逐渐让智能体具备类似人类的探索与理解能力。
具身认知:让智能体学会“思考”
感知之后,智能体必须能够理解任务、制定计划,并在执行过程中不断调整。这就是具身认知的核心。它不仅仅是“看懂”,更是“想明白”。
在技术路径上,任务驱动的规划是最直观的方式,例如 LLM-Planner 借助大语言模型来分解复杂任务,生成可执行的行动序列。记忆驱动的反思机制则让智能体能够像人类一样“吸取教训”,Reflexion 就是一个典型案例,它通过回顾失败经验来改进未来的决策。
而多模态基础模型如 SayCan、EmbodiedGPT,则尝试将语言、视觉与动作统一到一个模型中,让智能体能够在跨模态信息中形成整体认知。
然而,这一模块也面临着不小的挑战。长时序推理仍然是难点,智能体往往在需要数十步甚至上百步推理的任务中表现不稳定。跨模态对齐问题也尚未完全解决,不同模态的信息如何在统一空间中高效融合,仍是研究热点。更重要的是,可迁移性不足,智能体在一个环境中学到的能力,往往难以无缝迁移到另一个环境。
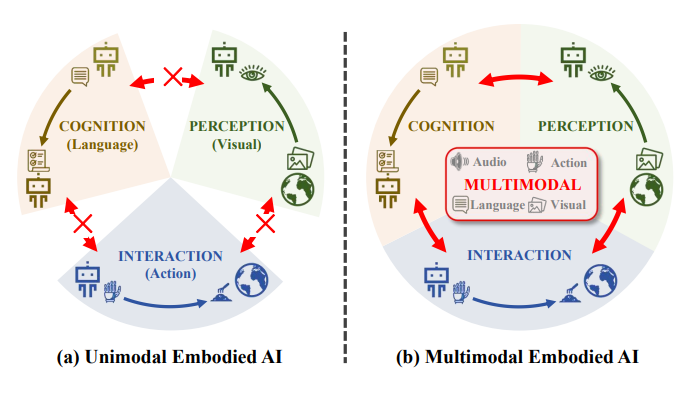 图片
图片
图4:单峰体现人工智能和多模态体现人工智能。(a)单峰方法侧重于体现人工智能的特定模块。它们受到每种模态提供的信息范围狭窄以及跨模块模态之间固有差距的限制。(b)多模态嵌入式人工智能方法打破了这些限制,实现了模块的相互增强。
动态交互:从单体控制到人机共生
最后,具身智能必须能够与环境和其他主体进行交互。这不仅包括对物理动作的精准控制,还涉及与其他智能体的协作,甚至与人类的自然互动。
在动作控制层面,谷歌的 RT-2 模型展示了如何将大模型的语义理解与机器人控制结合,让机器人能够执行复杂的自然语言指令。CogAgent 则进一步探索了跨模态的感知与控制一体化。
在行为交互方面,TrafficSim 等模拟平台让智能体能够在复杂交通环境中学习与其他车辆的博弈。更高层次的协作决策则由 AgentVerse、MetaGPT 等框架推动,它们尝试让多个智能体在共享目标下进行分工与合作。
趋势同样清晰:从最初的单体控制,到多智能体协作,再到未来的人机共生。具身智能的终极目标,不是让机器人单打独斗,而是让它们能够与人类并肩作战,成为真正的伙伴。
3.LLMs/MLLMs 与 World Models 的互补性
在具身人工智能的讨论中,大语言模型(LLMs)、多模态大模型(MLLMs)与世界模型(World Models, WMs)常常被视为两条平行的发展路径。前者擅长语义与推理,后者则强调物理与预测。综述论文的一个核心贡献,就是揭示了二者之间的互补关系,并提出联合架构的必要性。
LLMs/MLLMs 的优势与局限
大语言模型的崛起,让 AI 在语义层面展现出前所未有的能力。它们能够进行复杂的语义推理,理解上下文关系,并将复杂任务分解为可执行的步骤。在多模态扩展之后,MLLMs 更是具备了跨模态理解的能力,能够同时处理语言、图像、视频等信息,从而在具身智能中承担“任务大脑”的角色。
然而,LLMs 与 MLLMs 的局限也十分明显。它们缺乏对物理世界的真实约束,往往只能在符号空间中进行推理,难以保证生成的计划在现实中可行。同时,它们在实时适应性上存在不足,面对动态环境时,响应速度与稳定性都难以满足具身智能的需求。换句话说,它们很聪明,但不够“接地气”。
World Models 的优势与局限
与 LLMs 相比,世界模型的优势在于它们能够在内部构建环境表征,进行未来预测,并保持与物理规律的一致性。通过在“心智模拟器”中不断试错,智能体可以在不直接消耗现实资源的情况下学习复杂行为。这种能力让 WMs 成为具身智能中不可或缺的“物理引擎”。
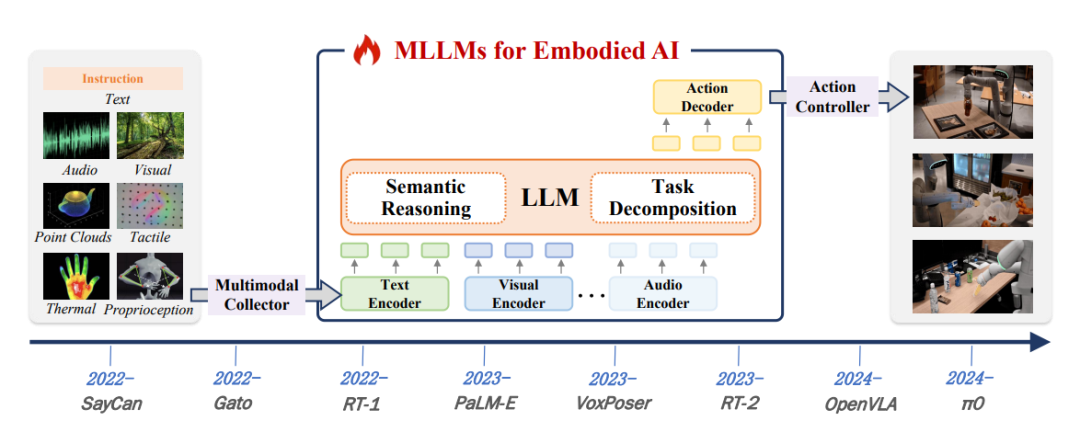 图片
图片
图5:嵌入式人工智能MLLM的发展路线图。该路线图突出了其概念和实践发展中的关键里程碑。
但世界模型也有短板。它们在语义推理方面远不如 LLMs,难以理解复杂的任务描述或跨模态信息。同时,WMs 的泛化能力有限,往往需要在特定环境中进行大量训练,才能在相似场景中表现良好。一旦环境发生较大变化,模型的适应性就会显著下降。
联合架构的必要性
正因如此,研究团队提出了一个清晰的方向:将 MLLMs 与 WMs 结合,构建下一代具身智能架构。在这种架构中,MLLMs 提供语义智能,负责理解任务、分解目标、进行跨模态推理;而 WMs 提供物理智能,负责预测环境变化、验证行动可行性、确保与物理规律一致。
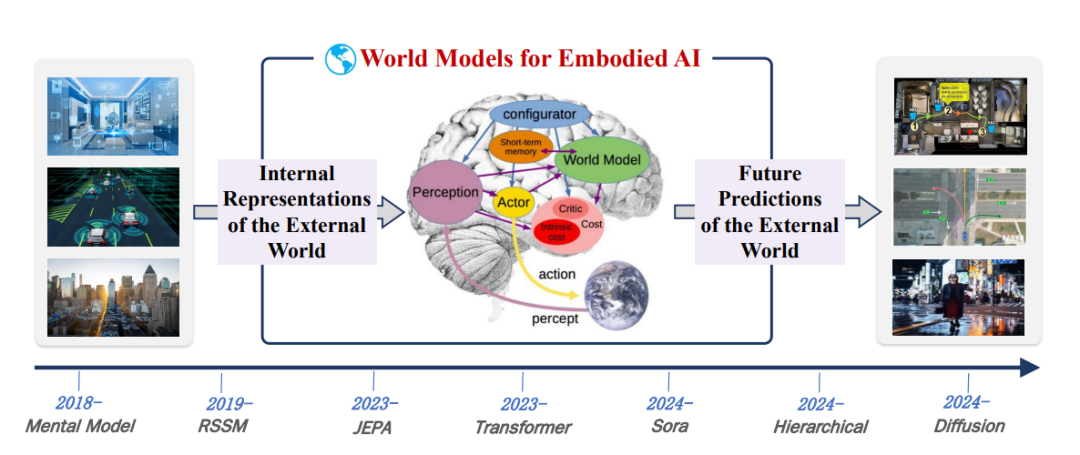 图片
图片
图6:嵌入式人工智能的WMs发展路线图。该路线图突出了其概念和实践发展中的关键里程碑。
这种结合意味着智能体既能“听懂人话”,又能“脚踏实地”。它既能理解人类的复杂指令,又能在物理世界中做出合理的行动。语义与物理的融合,正是具身智能迈向通用人工智能的关键一步。
4.典型案例与应用场景
研究团队特别提到EvoAgent 这一代表性案例。它被称为“自进化智能体”,因为它不仅能执行任务,还能在过程中不断自我优化。EvoAgent 的核心能力体现在三个方面:自规划、自反思与自控制。
自规划意味着它能够根据任务目标自主生成行动方案,而不是依赖外部指令逐步指导;自反思则让它在执行过程中不断总结经验,修正错误,提升下一次的表现;自控制则保证了它在复杂环境中能够保持稳定和灵活的行动。换句话说,EvoAgent 不仅是一个“执行者”,更是一个“学习者”和“思考者”。
这种能力的潜在应用场景非常广阔。在服务机器人领域,EvoAgent 可以让机器人从“机械执行”升级为“主动服务”,例如在家庭中根据环境和用户习惯自主调整行为。
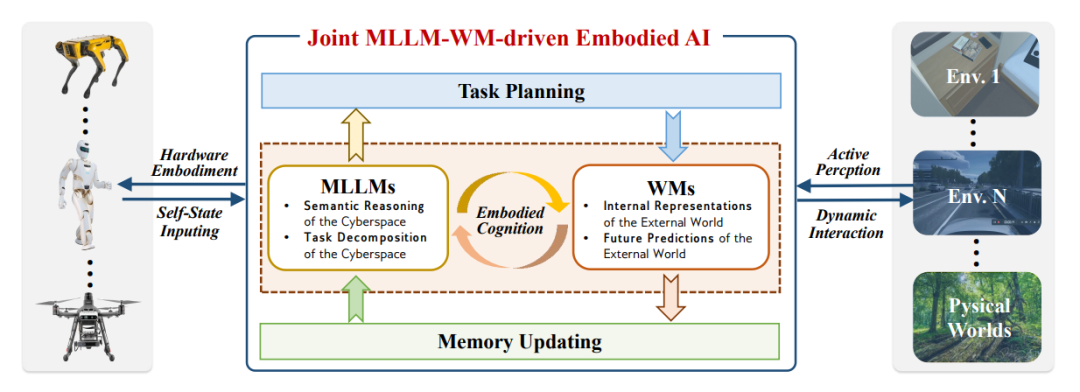 图片
图片
图7:将AI与MLLM和WMs相结合。MLLMs可以通过为任务分解和长期推理注入语义知识来增强WMs,而WMs可以通过构建物理世界的内部表示和未来预测来辅助MLLMs,使联合MLLM-WM成为有前景的嵌入式系统架构。
在工业自动化中,它能够在生产线上动态优化流程,减少停机和浪费,提高效率。在无人机救援任务中,EvoAgent 的自反思与自控制能力尤为关键,它可以在灾害现场快速适应复杂环境,做出最优路径选择,甚至在通信受限的情况下独立完成任务。而在多智能体协作系统中,EvoAgent 的自进化特性让它能够与其他智能体形成默契,分工协作,完成单个智能体无法完成的复杂任务。
这些应用场景的共同点在于:环境复杂、任务动态、需求多变。传统的“预设规则”式 AI 在这些场景中往往力不从心,而具身智能体,尤其是像 EvoAgent 这样的自进化架构,正好填补了这一空白。
5.研究议程与挑战
尽管具身智能的蓝图令人振奋,但研究团队也清晰地指出了未来研究必须面对的挑战与方向。
首先是自主具身 AI。未来的智能体不能仅仅依赖人类提供的数据和指令,而是要具备自进化与自学习的能力。它们需要像生物一样,在与环境的长期互动中不断成长,形成真正的“经验智慧”。
其次是具身AI 硬件。再强大的算法也需要硬件支撑。具身智能的落地要求设备具备低功耗、高算力和边缘部署的能力。换句话说,未来的机器人和智能体不能总是依赖云端算力,而是要在本地就能完成复杂的感知与决策,这对芯片设计、传感器融合和能效优化提出了新的要求。
第三群体具身 AI。单个智能体的能力再强,也难以应对大规模、复杂的任务。未来的方向是群体智能与协作,让多个具身智能体能够像蜂群或蚁群一样,展现出超越个体的整体智慧。这不仅涉及算法设计,还涉及通信机制、协作协议和群体行为建模。
最后是可信赖性。随着具身智能逐渐走入现实世界,安全性、可解释性以及伦理与合规问题将成为绕不开的议题。一个能够自主学习和进化的智能体,如何保证它的行为符合人类价值观?如何避免潜在的安全风险?如何让它的决策过程透明可解释?这些问题的答案,将决定具身智能能否真正被社会接受。(END)
参考资料:https://arxiv.org/pdf/2509.20021


