每当你在知乎、Reddit 等平台上刷到别人晒出的会议投稿分数时,是否也会暗自感叹:“怎么大家的分数都这么高?”在学术圈中,优秀的作品总能迎来高光时刻——作者乐于分享,围观者也乐于点赞。相较之下,那些被拒稿、分数偏低的“失败案例”,常常悄然隐没于网络暗角。于是,我们在学术社区里看到的讨论,往往带着一层“光鲜滤镜”,即上行偏差(upward bias),让我们误以为高分才是常态。
德州农工大学和康奈尔大学的研究团队基于知乎和 Reddit 上关于 ICLR、ACL、EMNLP 等多个顶会的讨论帖定量地验证了这一观点:在线讨论平台上作者分享的审稿分数,并不能代表全局,它们普遍高于真实分布。更有趣的是,研究者发现这一现象的背后,并不只是幸存者偏差在作祟,而是至少有三类作者共同推动了这种上行偏差的形成:
1.Survivors(“幸存者”):也就是那些论文被录用的作者。他们更倾向于分享成功、展示成绩;而被拒的作者则往往选择沉默。这种录用帖子与拒稿帖子比例的失调,使得线上样本整体呈现出明显的高分偏向。
2.Complainers(“抱怨者”):在被拒稿的作者中,那些得分较高却依然未被录用的人,更倾向于发帖质疑审稿意见或流程、表达不满;而“低分被拒”的作者则往往选择沉默。这种对“高分被拒”样本的偏好,使线上讨论的分数分布进一步被推高。
3.Borderliners(“边缘者”):在尚未公布录取结果的阶段(例如 rebuttal 期间),那些分数处于“可能被录取、也可能被拒”边缘区间的作者往往更焦虑,也更渴望获取信息。他们常在论坛发帖求问:“我这个分数有希望吗?” 由于绝大多数顶会的录取率远低于 50%,录取线附近的分数本身就高于总体中位数,因此这类作者的活跃发帖也进一步加剧了上行偏差。
•论文标题:Survivors, Complainers, and Borderliners: Upward Bias in Online Discussions of Academic Conference Reviews
•论文链接:https://arxiv.org/abs/2509.16831

“上行偏差”广泛存在
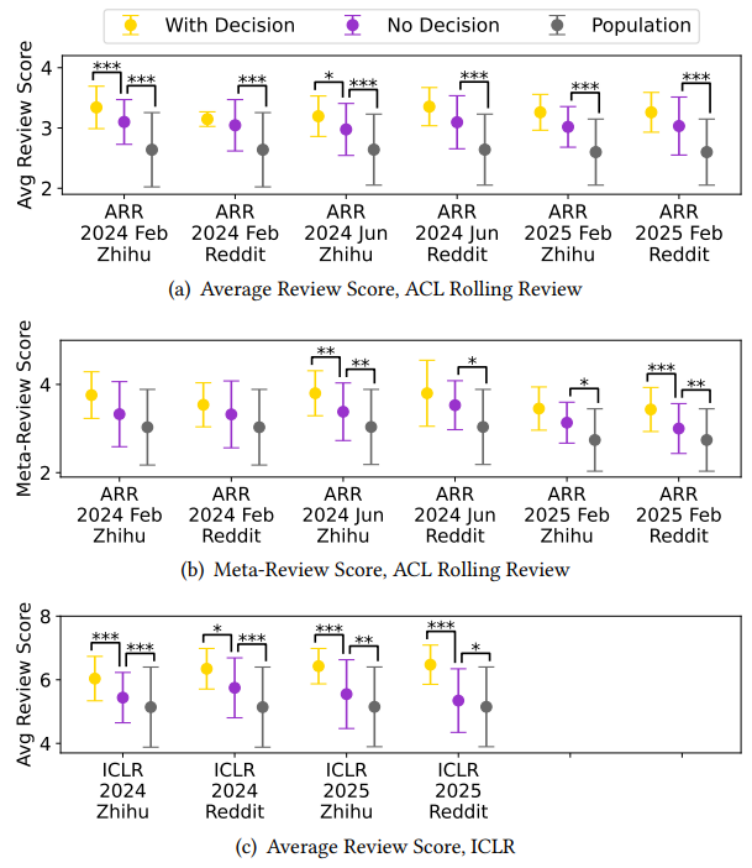
研究者从知乎和 Reddit 这两个平台上关于 ACL 2024, EMNLP 2024, ACL 2025, ICLR 2024, ICLR 2025 五次顶会的讨论帖中收集了 1,261 篇投稿作者分享的审稿分数(以下简称样本)。将之与官方公布的该次会议所有投稿的得分(以下简称总体)分布进行了对比分析。结果显示,在所有被分析的会议中,线上讨论帖中的样本分布普遍高于总体分布。并且这一“上行偏差”的存在是跨会议、跨年份、跨平台、并且统计上显著的。换言之,作者们在网络上分享的论文分数,整体上被推高了一个档次。线上世界展现出的学术生态,比现实中的要光鲜得多。换句话说,当你看到“我的论文拿了4个strong accept被录用”的帖子,千万不要把它当作常态。
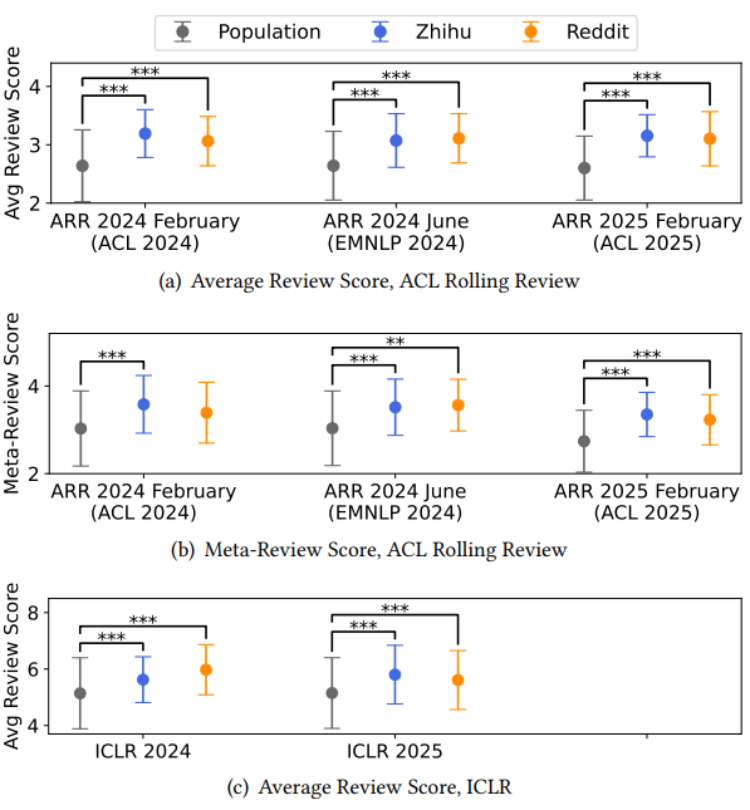
是谁在推动“上行偏差”?
为了理解上行偏差,研究者进一步拆解了背后的动因,发现至少有三种类型的作者在发挥作用。
幸存者(Survivors)
幸存者偏差是直观上最容易想到的原因之一。事实上,分享自己会议投稿的帖子可以分为三类:汇报了投稿被接收、汇报了投稿被拒绝、没有汇报结果(例如仍在 rebuttal 中,还不知道结果)。基于前两类,我们可以计算出样本录取率,并将之与总体录取率进行比较。研究者发现在绝大多数会议中,线上讨论帖中样本录取率都远高于总体录取率。例如在 ACL、EMNLP、ICLR 的知乎和 Reddit 数据中,样本录取率分别是总体录取率的 2.06 倍和 1.87 倍!
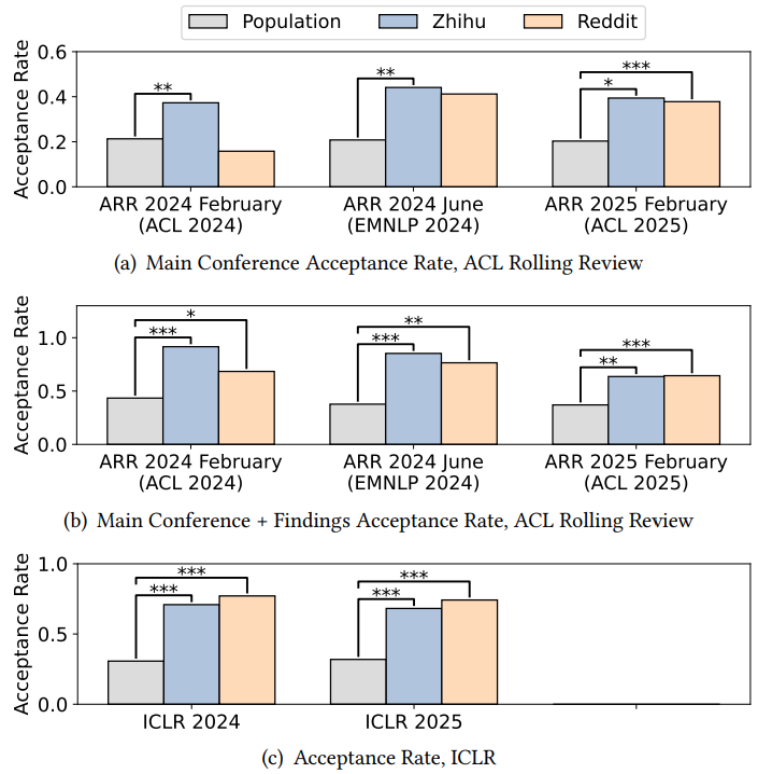
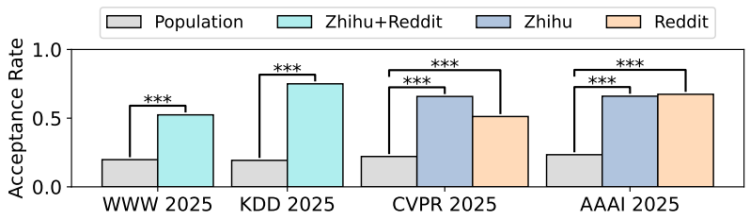
与所有投稿的分数分布(这类数据通常难以获取,只有如 ACL Rolling Review 和 ICLR 等少数会议会公开)不同,各大会议的录取率在 proceedings 中相对容易查到。基于此,研究者进一步比较了 WWW、KDD、CVPR、AAAI 等会议的官方录取率与在线讨论样本中的录取率,结果同样揭示出显著的幸存者偏差:在这些会议的线上讨论中论文被录取的比例是现实中的 2.98 倍!
抱怨者(Complainers)
幸存者效应揭示了录用帖子与拒稿帖子之间比例的失调。那么,在被录用的作者群体中,有没有一部分人比另一部分人更愿意分享成功呢?同样地,在被拒稿的作者群体中,有没有谁更可能选择发声呢?研究者进一步分析了作者分享的被录用与被拒稿论文的平均审稿分数在其对应总体分布中的位置。他们以 ICLR 会议为例,绘制了被录用论文和被拒稿论文的总体累积分布函数(CDF),分别用蓝色和红色表示,并在图中标出了知乎和 Reddit 上作者报告的平均分数均值(黑色和灰色虚线),以直观展示线上报告分数在总体分布中的分位位置。
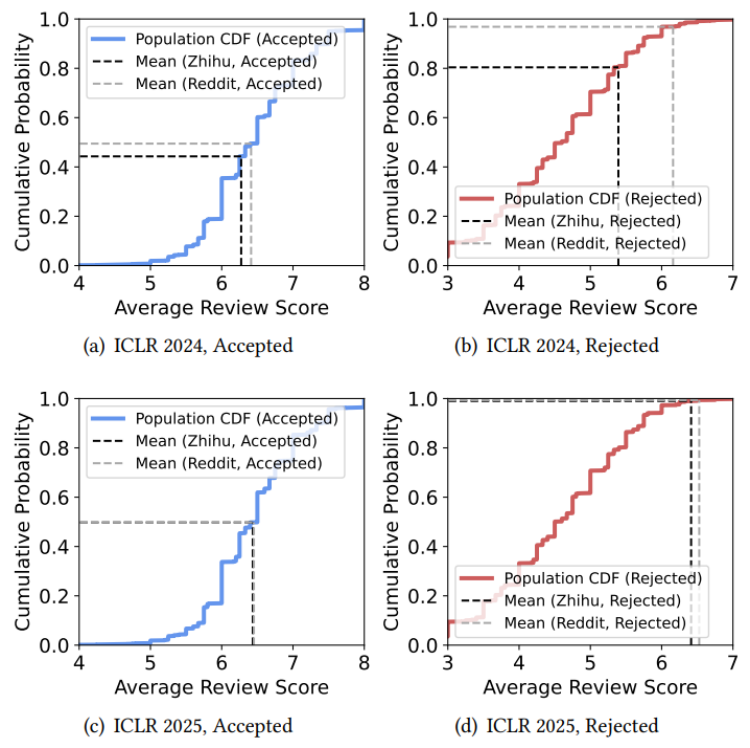
结果显示,被录用论文的作者分享的平均分数均值大致落在所有被录用论文总体分布的中位数附近。这意味着,在被录用论文中,“超高分,有机会获奖”的论文与“低分飘过,将将过线”的论文的作者参与线上讨论的概率大体相当。然而,被拒稿论文的情况则截然不同。线上讨论中被拒稿论文的平均分数明显高于所有被拒稿论文的平均水平。在 ICLR 2024 和 ICLR 2025 中,知乎和 Reddit 上被拒稿论文的平均分数均值位于被拒稿论文总体分布的前 0.6%-19.6% 分位!值得注意的是,Reddit 上 ICLR 2025 的相关讨论中,作者分享的被拒稿论文平均分甚至达到了 6.527,超过了同期作者分享的被录用论文平均分 6.451!这表明,在被拒稿作者中,“高分被拒”的抱怨者更可能选择发声、表达不满;而“评委一致给低分,无悬念被拒”的作者们则更可能沉默不语。正是这种存在于被拒稿的作者群体内部的选择性发声加剧了上行偏差。
边缘者(Borderliners)
上面的讨论中只涉及了两类帖子:汇报了投稿被接收、汇报了投稿被拒绝。那么对于没有汇报结果的帖子,上行偏差是否仍然存在呢?研究者发现,即便只考虑没有汇报结果的帖子(即排除了幸存者和抱怨者效应),样本分布仍然显著高于总体分布。
为了探究为何未报告结果的帖子仍会表现出上行偏差,研究者将这些未报告结果的样本累积分布函数(CDF)与总体 CDF 进行了对比分析。
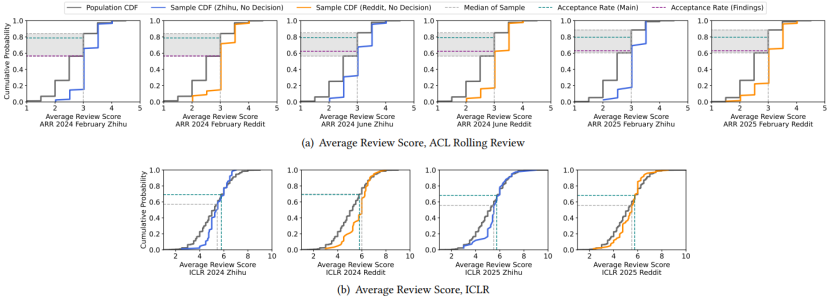
可以发现,未报告结果的作者的审稿分数往往集中在录取线附近。以 ACL Rolling Review(即 ACL 和 EMNLP)为例,未报告结果的样本中,审稿分数的中位数和众数均为 3.0。在总体分布中,这一分数段恰好覆盖会议录取率所对应的分位数。ICLR 的情况也类似,未报告结果的样本 CDF 在低分区域低于总体 CDF,但在高分区域高于总体 CDF,说明样本更多集中在中间分数区间。在收到审稿分数与最终录取通知之间,录取线附近的作者(即“边缘者”)常常面临显著的不确定性,因此会主动利用知乎、Reddit 等在线讨论平台进行信息搜寻,希望通过他人经验和建议,更准确地评估自己论文的录取机会。而分数非常高或非常低的作者,由于结果较为确定,参与讨论的动力较小。因为绝大多数顶会的录取率远低于 50%,边缘分数区间通常高于总体中位数,因此“边缘者”的活跃发帖也进一步加剧了上行偏差。
我们该如何理性看待大家的晒分帖?
这项研究告诉我们,有三类作者合力,让我们在线上讨论中看到的审稿分数,比真实平均水平好看许多。同时,这也给学术圈里的在线平台“信息消费者”们带来了几条提醒:
•不要迷信样本平均值:线上晒分帖是作者自我选择的样本,上行偏差普遍存在,不足以代表会议的整体水平,尤其不要让它们误导了你的 rebuttal 策略。
•要多看官方统计:像 ICLR、ACL Rolling Review (ACL, EMNLP, NAACL) 等会议,会公开整体分数分布,这才是判断标准的依据。同时,也应当呼吁更多会议的组织者们发布官方统计。
•更多线上讨论参与者将传递更准确的统计信息:如果你是作者,无论你的投稿获得了怎样的分数,是否都愿意在讨论平台分享?
如欲深入了解这项研究的具体方法及更多结论(例如如何利用线上讨论样本分布更准确地估算投稿在总体中的分位数),欢迎查阅原论文:
•论文链接:https://arxiv.org/abs/2509.16831
作者介绍
本文作者朱航霄是德州农工大学计算机系二年级博士生,已在 EMNLP、CHI 等顶会发表论文 3 篇;殷裔安是康奈尔大学信息科学系助理教授,已在 Science、Nature、Nature Human Behaviour、Nature Communications 等顶刊发表论文 7 篇,曾入选 Forbes 30 Under 30 科学榜单;张彧是德州农工大学计算机系助理教授,已在 KDD、WWW、SIGIR、ACL、EMNLP、NAACL 等顶会发表论文20余篇,曾获 ACM SIGKDD 博士论文奖亚军。


