近日,微软研究院的一个团队发布了一个名为 Agent Lightning 的框架,它使任何人工智能(AI)智能体都能通过强化学习进行训练。
 图片
图片
这个框架的核心突破在于,它实现了智能体执行与强化学习(RL)训练过程的完全解耦。
这一设计允许开发者将该框架无缝集成到他们现有的智能体中,并且几乎不需要修改任何代码。
这意味着,无论智能体是使用LangChain、AutoGen等流行框架构建,还是从头开始编写,都能应用此训练方法。
1.训练与执行的彻底解耦
 图片
图片
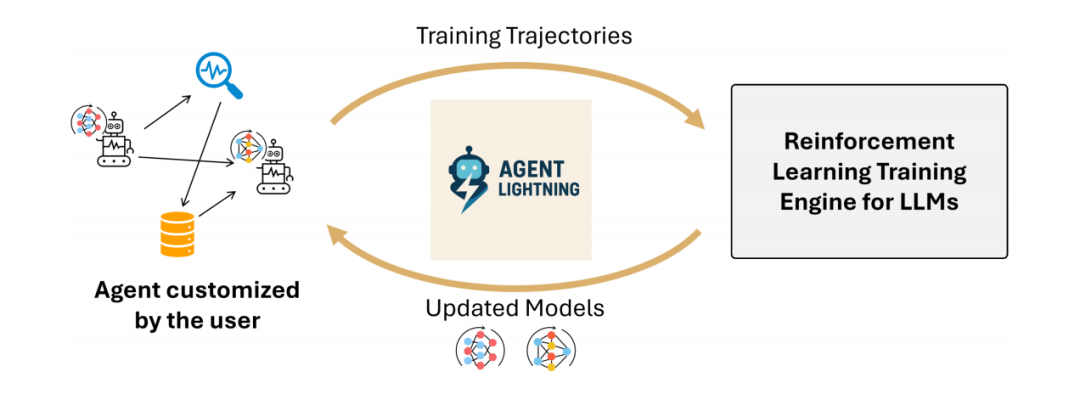
Overview of Agent Lightning
当前训练AI智能体的方法,通常将训练系统与智能体的内部逻辑紧密耦合在一起。
这种紧密耦合的方式,要求开发者必须在训练系统内部重建或大幅改造他们的智能体,过程费时费力且容易出错。
为了打破这一瓶颈,Agent Lightning 提出了一种创新的“训练-智能体解聚合” (TA Disaggregation) 架构。
 图片
图片
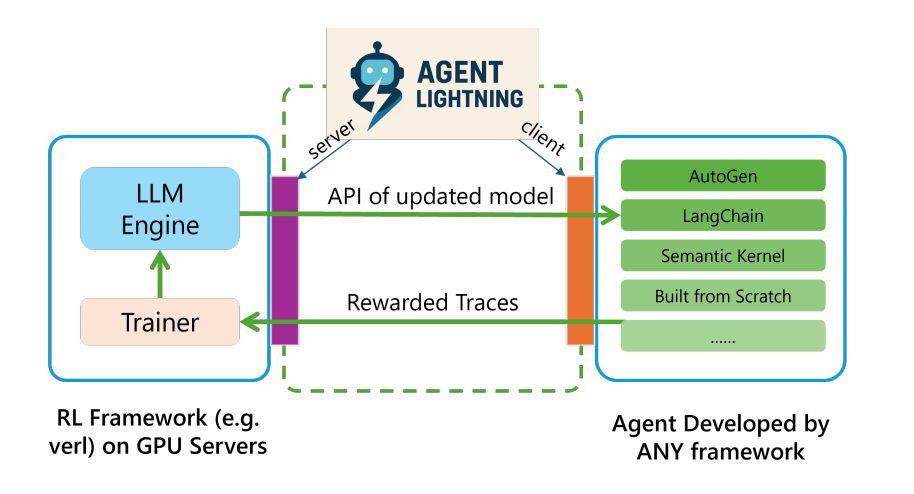
图注:Training-Agent Disaggregation architecture
这个架构将系统清晰地划分为两个核心组件:Lightning服务器和 Lightning 客户端。
Lightning服务器作为强化学习训练系统的控制器,负责管理整个训练流程和模型参数的更新。
Lightning客户端则作为智能体的运行时环境,独立负责运行智能体的具体应用逻辑和数据收集。
服务器通过一个类似OpenAI的API接口,向客户端提供更新后的模型访问权限。
客户端的智能体在执行任务时调用此API,就像使用任何标准的LLM服务一样,完全无需感知背后复杂的训练过程。
这种分离设计使得训练框架变得“智能体无关”,它只专注于优化模型和管理硬件资源,不关心智能体的具体实现。
同时,智能体也变得“训练器无关”,开发者可以聚焦于智能体的业务逻辑,而不受限于训练基础设施的束缚。
为了实现无代码修改的数据捕获,客户端巧妙地运用了如OpenTelemetry等可观测性框架,自动检测和记录执行轨迹。
这种架构还天然支持数据并行,客户端可以同时在单个或多个节点上运行大量智能体实例,极大地提升了数据吞吐量和训练效率。
此外,客户端运行时还内置了全面的错误处理机制,确保单个智能体的崩溃不会中断整个长时间的训练流程。
它还提供了一种“自动中间奖励”(AIR)机制,能够基于系统监控信号为智能体的中间步骤分配奖励,有效缓解了稀疏奖励问题。
通过这种方式,Agent Lightning 成功地将计算密集的模型训练与逻辑灵活多样的智能体应用分离开来,为大规模训练真实世界的AI智能体铺平了道路。
2.统一数据接口与分层强化学习
 图片
图片
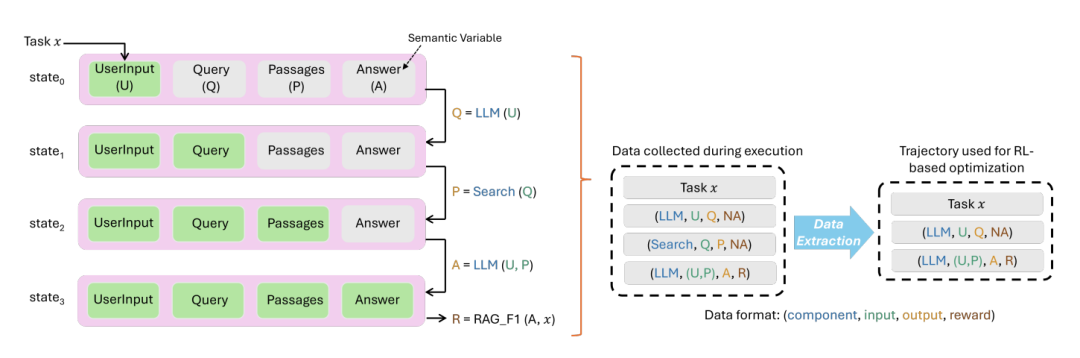
该图展示了 Agent Lightning 如何通过统一数据接口在执行过程中系统化地记录状态变化与轨迹,用于强化学习优化。
Agent Lightning 的理论基石,是将复杂的智能体执行过程抽象为一个马尔可夫决策过程(MDP)。
在这个模型中,智能体执行的某个瞬间快照被定义为“状态”,它包含了描述执行状况所需的一组变量。
策略大语言模型(LLM)生成的输出则被视为“动作”,这个动作会驱动智能体转换到下一个状态。
智能体完成任务后获得的结果,被量化为“奖励”信号,用于评估动作的质量。
基于MDP的建模,Agent Lightning 提出了一个统一的数据接口,该接口能适用于从任何AI智能体收集的数据。
这个接口将智能体的执行轨迹,无论其内部逻辑多么复杂,都统一表示为一系列(状态,动作,奖励)的转换序列。
这种设计巧妙地忽略了智能体内部繁琐多变的具体实现逻辑,只关注策略LLM的输入和输出,从而极大简化了数据建模。
为了利用这些收集到的数据来优化LLM,研究团队进一步设计了一种名为 LightningRL 的分层强化学习算法。
LightningRL 的核心在于一个信用分配模块,它首先将整个任务最终获得的总奖励,分配给过程中的每一次LLM调用(即每一个动作)。
然后,这些分配到单次动作的奖励,会被用于指导现有的单轮次强化学习算法(如GRPO、PPO等)来更新模型参数。
这种分层优化的方法,完美兼容了现有的高效RL算法,使其可以直接应用于更复杂的多轮交互场景中。
与以往将多轮交互拼接成一个长序列并使用掩码(masking)进行训练的方法相比,LightningRL 的设计优势显著。
它避免了设计复杂且容易出错的掩码策略,因为数据被天然地分解为独立的转换单元,无需拼接。
同时,这种方式也缓解了因多轮对话累积上下文,导致输入序列过长而超出模型限制或增加计算负担的问题。
LightningRL 的数据组织方式还支持灵活的上下文构建,模型的输入可以根据需要动态生成,例如包含历史摘要或特定的角色指令。
总而言之,通过MDP建模、统一数据接口和LightningRL算法,Agent Lightning 为在模块化和动态化的智能体系统中进行有效的策略优化奠定了坚实的基础。
3.跨场景应用的稳定提升
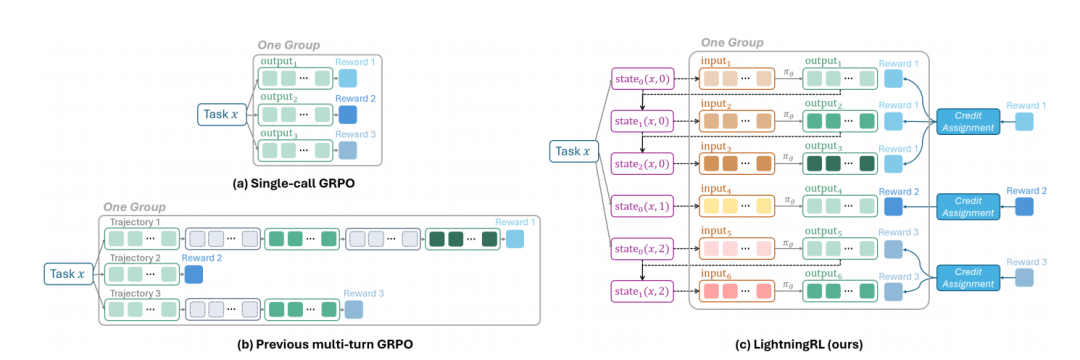
该图对比了单次调用 GRPO、多轮 GRPO 与 LightningRL,突出 LightningRL 通过将轨迹分解为转换并分组估计优势,实现更精细的优化。
为了验证框架的真实效能,研究团队在三个具有代表性且实现方式各不相同的任务上进行了测试。
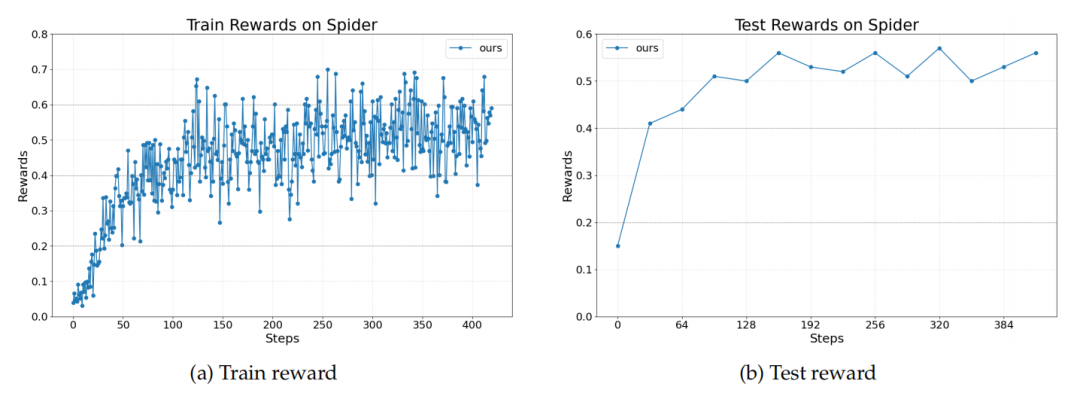
第一个任务是使用LangChain框架构建的文本到SQL智能体。
 图片
图片
Text-to-SQL 任务的奖励曲线
该智能体需要在复杂的Spider数据集上,根据自然语言问题生成可执行的SQL查询并回答问题。
这个场景的特殊之处在于它是一个多智能体系统,由同一个LLM扮演SQL编写、检查和重写三个不同角色。
实验证明,Agent Lightning 不仅能够驱动整个系统性能提升,还能选择性地同时优化其中的两个智能体(编写和重写),展示了其在多智能体协同优化中的灵活性。
第二个任务是利用OpenAI Agents SDK实现的检索增强生成(RAG)智能体。
这个智能体需要通过从包含2100万份文档的整个维基百科中检索信息,来回答MuSiQue数据集中的多跳推理问题。
这项任务的挑战在于查询的开放性和巨大的信息检索空间,非常考验智能体制定有效检索策略和进行文本推理的能力。
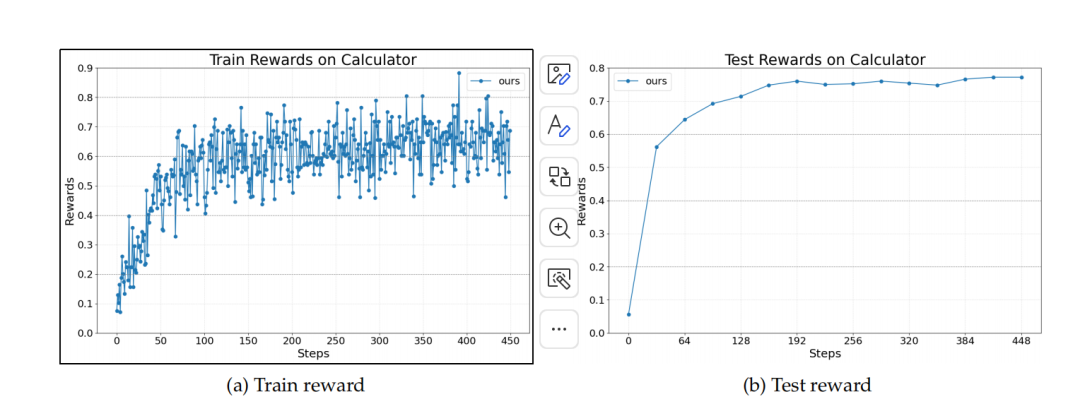
第三个任务则是通过AutoGen框架开发的数学问答智能体。
该智能体必须在Calc-X数据集上,学会如何以及何时调用计算器工具来解决数学问题。
 图片
图片
Reward curves for the Calculator task
这要求模型不仅要理解数学逻辑,还要能生成语法正确的工具调用指令,并将工具返回的结果正确地整合到最终的解题步骤中。
在所有这三个场景中,奖励曲线图都清晰地显示,经过Agent Lightning 的训练,模型的性能都获得了稳定且持续的提升。
这些跨越不同框架、不同任务、不同复杂度的成功案例,有力地证明了
Agent Lightning 作为一个通用优化框架的强大潜力,能够赋能AI智能体解决更加开放和动态的现实世界问题。
via https://github.com/microsoft/agent-lightning


