今天凌晨,微软在官网开源了Phi-4家族的最新版本Phi-4-mini-flash-reasoning。
mini-flash版延续了Phi-4家族参数小性能强的特点,是专门针对那些受算力、内存和延迟限制场景设计的,单个GPU可运行,适合笔记本、平板电脑等边缘设备。
与前一个版本相比,mini-flash使用了微软自研的创新架构SambaY,推理效率暴涨了10倍,延迟平均降低了2—3倍,整体推理性能实现了大幅度提升。尤其是高级数学推理能力,非常适合教育、科研领域。
开源地址:https://huggingface.co/microsoft/Phi-4-mini-flash-reasoning
英伟达API:https://build.nvidia.com/microsoft
创新SambaY架构
SambaY架构是一种创新的解码器混合架构,由微软、斯坦福大学联合研发而成。其核心在于通过引入门控存储单元实现跨层的高效记忆共享,从而在提升解码效率、保持线性预填充时间复杂度的同时,增强长上下文性能,且无需显式的位置编码。
该架构以Samba模型作为自解码器,在交叉解码器中应用GMU来替代一半的交叉注意力层,以此共享自解码器中最后一个SSM层的内部表示。
GMU的设计灵感来源于门控线性单元、门控注意力单元和SSMs中广泛存在的门控机制,接收当前层的输入表示和前一层的记忆状态作为输入,通过可学习的投影和门控机制生成输出。
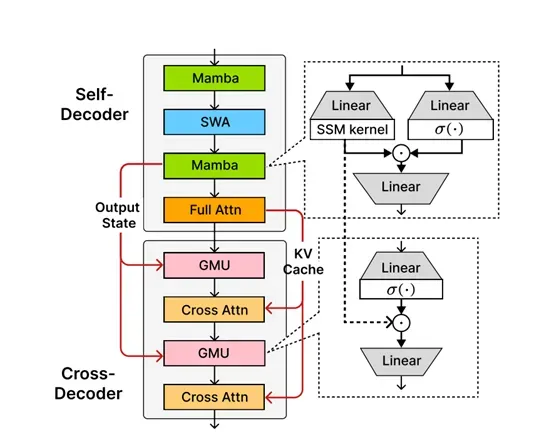
从形式上看,GMU的输出由前一层的记忆状态与当前层输入经过SiLU激活函数后的结果进行元素级乘法,再通过可学习的权重矩阵得到,这种机制能让当前层输入基于每个记忆通道的查询上下文,对前一层的标记混合进行动态的细粒度重新校准。
模型方面,SambaY的自解码器包含交错的Mamba层、滑动窗口注意力、SSM内核及线性层等组件。在预填充阶段,全注意力层只需计算KV缓存,与YOCO类似,保证了预填充阶段的线性计算复杂度。
交叉解码器中,GMU与交叉注意力层交错排列,共享自解码器中最后SSM层的表示。与YOCO相比,SambaY在预填充时除了缓存最后一个全注意力层的KV缓存外,还需额外缓存来自最后一个Mamba层的SSM内核输出状态,但其内存开销在大小上可忽略不计。
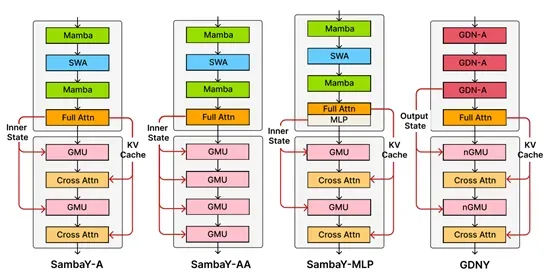
在解码阶段,这一架构将一半交叉注意力层的内存I/O复杂度从线性的O(dkv·N)降至常数O(dh)(其中N为序列长度,dkv为键值对维度,dh为SSM内部维度)。由于实际中dh/dkv的比值通常不超过128,当N远大于dh/dkv时,能带来显著的效率提升。
此外,SambaY在训练中,权重矩阵采用LeCun均匀初始化,输入与输出嵌入矩阵绑定并通过正态分布初始化,同时结合RMSNorm提升训练稳定性。其增强变体SambaY+DA通过引入Differential Attention进一步提升了推理效率。
SambaY测试数据
为了测试SambaY架构的性能,微软全面评估了SambaY在不同场景下的性能,包括长文本生成、推理任务以及长上下文检索能力。
在长文本生成任务中,SambaY架构的效率提升非常显著。传统的Transformer模型在处理长文本时面临着巨大的计算和内存压力,尤其是在解码阶段。
而SambaY在处理2K长度的提示和32K长度的生成任务时,解码吞吐量比传统的Phi4-mini-Reasoning模型提高了10倍。
在高级数学推理能力Math500、AIME24/25和GPQA Diamond的测试中,SambaY的性能比Phi4-mini-Reasoning也实现了大幅度提升,尤其是在AIME24/25任务中,SambaY不仅能够准确地解决复杂的数学问题,还能生成清晰、逻辑连贯的解题步骤。
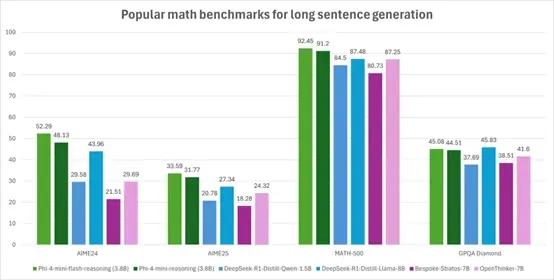
除了推理任务,微软使用了Phonebook和RULER等主流基准测试来评估SambaY在长上下文检索中的表现。这些任务要求模型能够从长文本中准确地检索出相关信息,这对于模型的长上下文理解和生成能力提出了很高的要求。
在Phonebook任务中,SambaY在32K长度的上下文中取得了78.13%的准确率,明显优于其他模型。SambaY在RULER任务中也表现优异,即使在较小的滑动窗口大小下,也能保持较高的检索准确率。
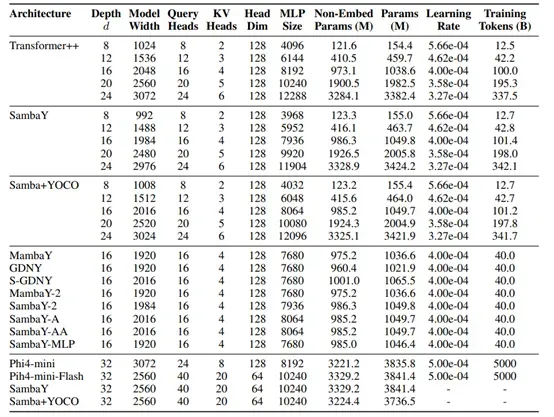
为了进一步验证SambaY的可扩展性,微软进行了大规模预训练实验。使用了3.8B参数的Phi4-mini-Flash模型,并在5T tokens的数据集上进行了预训练。尽管在训练过程中遇到了一些挑战,如损失发散等,但通过引入标签平滑和注意力dropout等技术,模型最终成功收敛,并在MMLU、MBPP等知识密集型任务中取得了显著的性能提升。


