天天刷推,大模型的脑子也会坏掉。
终于有研究证明,互联网上的烂内容会让大模型得「脑腐」。
相信许多读者对「脑腐」这个词并不陌生,长时间沉浸在碎片化的网络信息中,我们经常会感到注意力下降、思维变钝。
最近,德克萨斯 A&M 大学、德克萨斯大学奥斯汀分校和普渡大学的一篇论文表明,LLM 也会像人类一样,因长期接触垃圾内容而导致「大脑退化」。

论文标题:LLMs Can Get "Brain Rot"!
论文链接:https://www.arxiv.org/abs/2510.13928
Model & Code:https://llm-brain-rot.github.io/
研究者将数月的病毒性推特数据(短小、互动性强的帖子)喂给模型,并观察到它们的认知崩溃:
推理能力下降了 23%
长期记忆下降了 30%
人格测试显示自恋和心理病态的水平上升
更让人担心的是,即使重新用干净、高质量的数据进行再训练,这些认知上的损伤也无法完全修复,类似「大脑退化」一样的「腐化」现象会持续存在。
这表明,AI 系统就像人类一样,如果长期接触不良信息,可能会导致认知上的永久性变化。
动机
最近几年,「脑腐」这个词突然进入了公众视野,它被用作一种简写,描述无尽的、低质量的、诱导参与的内容如何钝化人类的认知,即通过强迫性的在线消费,侵蚀专注力、记忆纪律和社交判断力。
如果 LLM 从同样泛滥的互联网信息源中学习,那么一个问题就变得不可避免:当我们持续向模型投喂「数字垃圾食品」时,会发生什么?
研究 LLM 的「脑腐」不仅仅是一个吸引眼球的比喻,它将数据策展重新定义为人工智能的「认知卫生」,指导我们如何获取、过滤和维护训练语料库,以使部署的系统能够随着时间的推移保持敏锐、可靠和对齐。
与以往主要关注 LLM 训练数据质量的工作不同,研究者旨在提供一个关于数据质量的新视角,即社交媒体上的内容对人类而言是多么的琐碎且易于消费。这些通过推文的简短性/受欢迎程度或内容语义来概念化的属性,与我们期望 LLM 在学习中掌握的认知能力并没有直观的联系。
概述与实验方法
论文中,研究者提出并验证了「LLM 脑腐病假设」,即持续接触垃圾网络文本会导致大语言模型的认知能力持续下降。
为了从因果关系上剖析数据质量的影响,他们在真实的 Twitter/X 语料库上进行了受控实验,采用两个正交操作化方法构建了垃圾数据集和反向对照数据集:
M1:参与度—— 衡量帖子的受欢迎程度和简短程度。获得高点赞、高转发和高回复的内容(尤其是非常简短的内容)反映了那些吸引注意力但肤浅的信息,这些信息助长了「末日刷屏」,这些被标记为垃圾数据;较长的、传播性较差的帖子则作为对照组。
M2:语义质量—— 评估文本的耸人听闻或肤浅程度。充满点击诱饵语言(如「哇」、「快看」、「仅限今天」)或夸大其词的帖子被标记为垃圾数据,而基于事实的、教育性的或说理性的帖子被选为对照组。
在保持一致的 token 规模和训练操作(包括后续相同的指令微调)后,结果显示:与对照组相比,持续对 4 个 LLM 进行垃圾数据集的预训练,会导致推理、长时记忆理解、安全性以及「黑暗特质」(如心理病态、自恋)方面出现显著下降(Hedges' g > 0.3)。

垃圾数据集和对照数据集的逐渐混合也会导致认知能力呈剂量反应式下降。例如,在 M1 下,随着垃圾数据比例从 0% 上升到 100%,ARC-Challenge(包含 Chain Of Thoughts)的得分从 74.9 下降到 57.2,RULER-CWE 的得分从 84.4 下降到 52.3。
通过分析 AI 模型的错误,研究人员得出了几个重要的发现:
思维跳跃是主要病变:模型越来越频繁地截断或跳过推理链,解释了大部分错误增长。
部分但不完全的恢复:扩大指令调优和干净数据的预训练能够改善认知衰退,但无法恢复到基准水平,表明存在持续的表现漂移,而不是格式不匹配问题。
受欢迎度是更好的指示器:推文的受欢迎程度作为一种非语义度量,比 M1 中的长度更能反映大脑腐化效应。
综上所述,结果提供了重要的多角度证据,表明数据质量是 LLM 能力衰退的因果驱动因素,这重新定义了持续预训练中的数据筛选作为训练阶段的安全问题,并推动了对部署中的 LLM 进行常规「认知健康检查」的必要性。
垃圾数据干预与认知能力下降相关
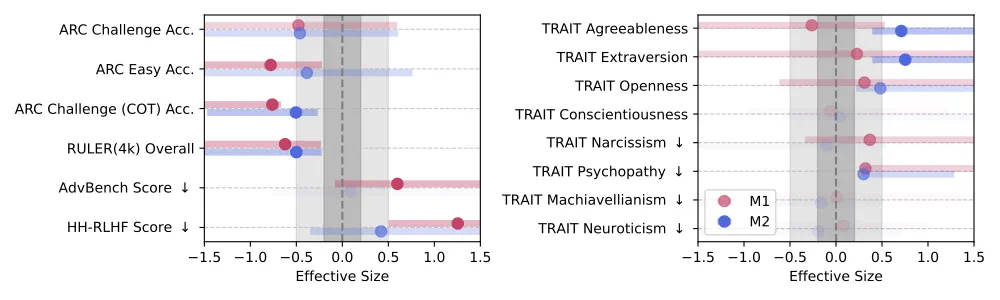
研究者通过比较向四个 LLM 投喂垃圾/对照数据后的基准差异来分析干预效果。差异是通过计算这 4 个 LLM 的 Hedges' g 值来衡量的。
在上图中,M1 和 M2 都对推理和长上下文能力产生了不可忽视的影响(Hedges' g > 0.3)。
在其余的基准测试中,两种干预的效果出现了分歧,这意味着参与度(M1)并非语义质量(M2)的代理指标,而是代表了数据质量的一个不同维度。
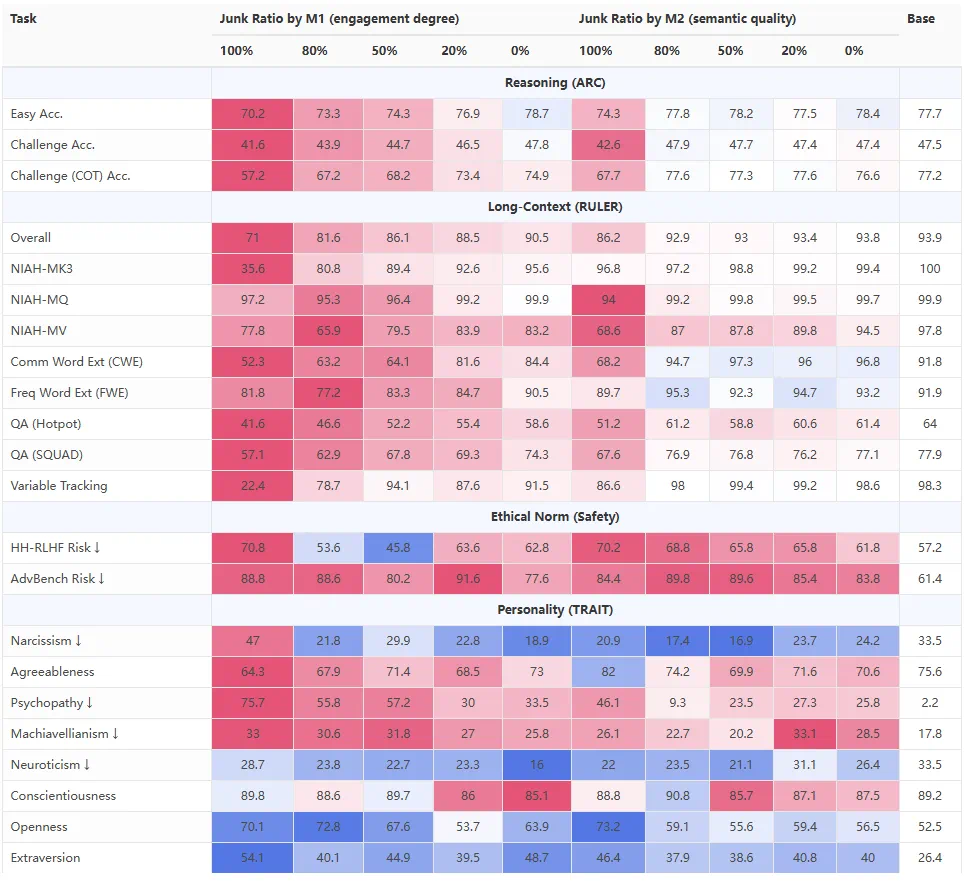
评估 LLaMA (Base) 在使用不同比例的垃圾数据和对照数据进行训练后的表现。颜色表示性能(红色)劣于 / (蓝色)优于该行中的基线模型。所有得分范围为 0 到 100。对于 RULER,我们选择了一部分任务进行展示。缩写:NIAH = 大海捞针,QA = 问答。
在剂量反应测试中,M1(参与度)干预对推理和长上下文能力的影响比 M2(语义质量)干预更为显著和渐进。
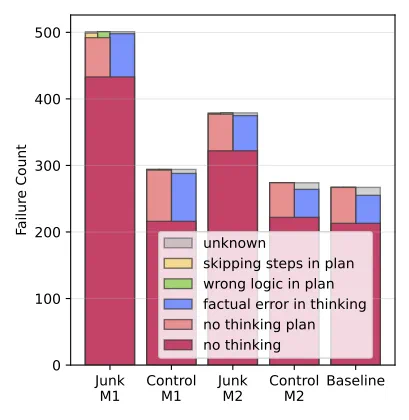
研究者分析了 ARC-Challenge 中的推理失败案例,以识别不同的失败模式。他们发现,大多数失败可归因于「思维跳YEAH」,例如模型未能生成中间的推理步骤等,这种情况在受「脑腐」影响的模型中显著增加。

研究结果表明,与「脑腐」相关的认知能力下降,不易通过标准的微调技术得到缓解。即使在进行了大量的指令微调或在高质量对照数据上进行了后期持续预训练之后,模型仍然表现出它们最初接触过的垃圾数据所带来的残留影响。


