当前,人工智能领域正经历一场由「模型微调」向「上下文工程」的范式转变。
通过在输入中引入更明确的指令和更丰富详实的知识,「上下文工程」既无需投入高昂的训练成本,亦不依赖开源模型权重参数,同时能够为用户和开发者提供更强的可解释性,正逐渐成为构建高性能、可扩展且具备自我改进能力的 AI 系统的核心范式。
正因如此,「微调已死」成为了AI领域近期广泛认可的热门话题。
斯坦福新论文:微调已死,自主上下文当立
这其中最具有代表性的是提词适应与优化算法。该类方法(如Alpha Evolve和GEPA)通过不断迭代优化,得到一个最优提示词实际使用。
然而,单一提示词的表达能力有限,往往难以全面严谨地表述复杂任务的所有需求。
对于这一缺陷,多提示词的相互协作是一个很自然的解决方案——单个提示词可能无法处理特定输入,但其他提示词可以弥补这一方面的性能损失。
如果能基于多个提示词生成的回答提取他们所达成的「共识」,AI系统就更有可能输出正确答案。
基于这一思想,西湖大学MAPLE实验室齐国君教授团队提出了基于「共识机制」的提示词组进化算法C-Evolve。
与既往仅优化单一提示词不同,C-Evolve旨在通过进化算法生成一组提示词。该组提示词在对输入信息进行独立处理后,通过提取所有输出结果的共识,以实现最优任务性能。
为实现这一目标,团队创新性地提出了「共识表决得分」这一进化指标,用于评估单个提示词在成组工作时的性能潜力,同时采用海岛算法提升组内个体的多样性。
通过多提示词共识机制所带来的增益,C-Evolve能够突破单一系统提示词的性能局限,显著提升系统整体性能。

具体下面来看。
共识机制
一个AI系统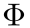 由一系列LLM调用模块组成。
由一系列LLM调用模块组成。
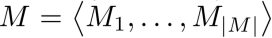
每个模块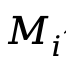 包含系统提示词
包含系统提示词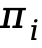 。
。
为了优化这些提示词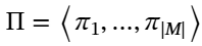 ,使任务
,使任务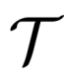 上的性能指标
上的性能指标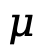 最大化,团队定义如下优化问题:
最大化,团队定义如下优化问题:
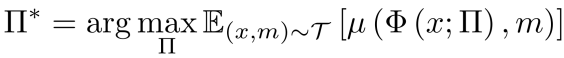
其中x代表任务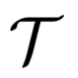 的一条实例数据输入,m代表评测所需的其他标注。
的一条实例数据输入,m代表评测所需的其他标注。
共识机制由一组独立、同功能的提示词共同完成。
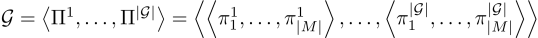
给定任务输入x,每个个体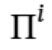 首先分别处理得到结果。
首先分别处理得到结果。
然后,基于所有个体输出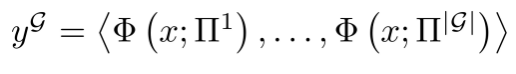 ,团队利用一个共识提取器
,团队利用一个共识提取器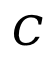 从中提取最终结果:
从中提取最终结果:
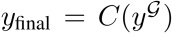
对于数学计算、客观选择等封闭回答类问题,团队采用多数表决输出高频一致答案。
而对于开放式提问,团队用LLM表决:通过大语言模型筛选出最具代表性的输出结果,确保其能够充分反映群体反馈中的主流意见。
寻找在共识机制下最优的一组提示词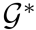 的优化问题如下:
的优化问题如下:
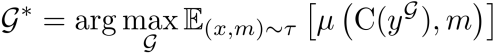
基于海岛的多提示词进化算法
为了获得一组性能最佳的提示词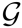 ,团队采用了基于海岛的进化算法:在
,团队采用了基于海岛的进化算法:在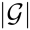 个相互独立的海岛内并行迭代种群。
个相互独立的海岛内并行迭代种群。
整个进化过程包含两个阶段:
1、基于个体独立性能的预热阶段;
2、基于跨海岛分组协作表现的共识进化阶段。
两阶段均使用评估指标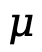 和度量数据集
和度量数据集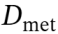 进行性能评估,同时另设反馈数据集
进行性能评估,同时另设反馈数据集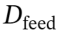 ,用于生成每个个体的详细执行记录,作为额外的反馈信息辅助进化。
,用于生成每个个体的详细执行记录,作为额外的反馈信息辅助进化。
预热阶段
在此阶段,团队将个体独立得分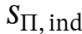 作为进化算法的适应度评分。
作为进化算法的适应度评分。
每轮迭代中,每个海岛首先依据岛内所有个体的适应度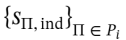 采样一个父个体。
采样一个父个体。
随后,将选中的父个体与其在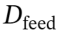 上采样数据得到的执行反馈、在
上采样数据得到的执行反馈、在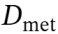 上测得的评估指标共同输入至LLM,进化生成新个体。
上测得的评估指标共同输入至LLM,进化生成新个体。
每个岛屿的个体数量上限为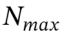 。
。
如超出,算法将淘汰在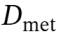 上表现最差的个体。
上表现最差的个体。
完整的预热阶段算法如下:

共识表决阶段
此阶段中,每个个体依据其组成提示组之后的性能作为进化的适应度。
如图所示,每个海岛均生成一个新个体后,C-Evolve算法会构建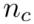 个提示组
个提示组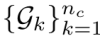 。
。
每个提示组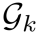 从各岛屿i中分别采样一个个体
从各岛屿i中分别采样一个个体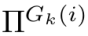 。
。
而后,团队基于共识机制测试这些组在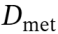 上的评估性能。
上的评估性能。
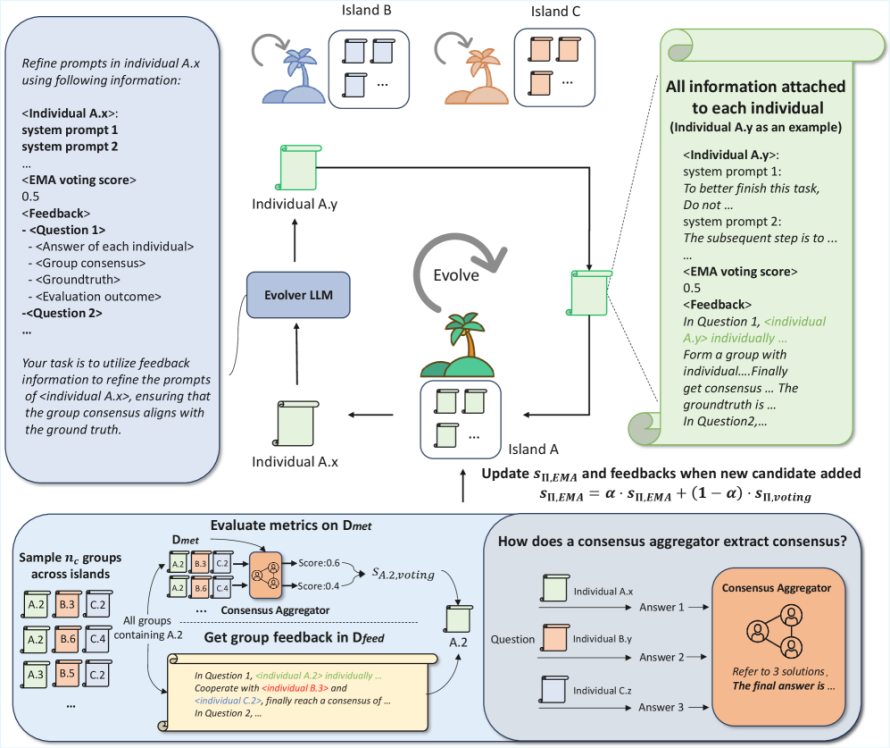
△基于共识机制的多提示词进化算法
基于组评估结果,团队很自然地想到可以以组为单位直接淘汰表现最差组的所有成员个体。
然而,不同组间存在个体重叠,这种激进的淘汰策略将同时影响其他表现较优的提示组。
为解决这一问题,团队定义了每个个体Π的共识表决得分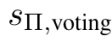 ,通过计算包含个体Π的所有提示词组的评估性能的平均值,团队能量化评估该个体有多大潜力参与构建一个好的提示词组:
,通过计算包含个体Π的所有提示词组的评估性能的平均值,团队能量化评估该个体有多大潜力参与构建一个好的提示词组:
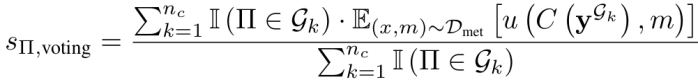
考虑到种群的动态变化,团队采用指数平滑后的得分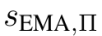 作为进化的适应度评分,更新公式为:
作为进化的适应度评分,更新公式为:
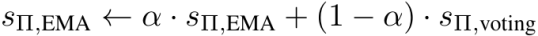
此处,团队特意避免直接计算个体参与的所有历史提示词组的平均性能。
这是因为早期采样的提示词组中的其他成员可能已被淘汰,这些过时结果无法真实反映个体在当前种群中的实际贡献。
因此,采用EMA方法赋予最新采样出的组更高权重,能有效抑制早期历史结果对个体评估的影响。

△共识表决阶段算法流程
提示词性能飙升
实验表明,C-Evolve同时适用于以Qwen3-8B为代表的开源模型和以GPT-4.1-mini为代表的闭源模型,并提升包括检索问答、数学推理、指令遵从在内的一系列任务性能。
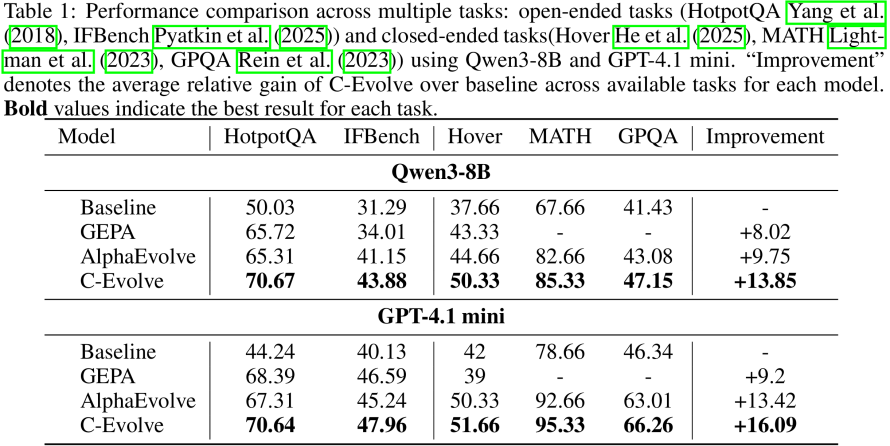
从IFBench任务上的系统提示词优化过程示意图可以看出,3个岛会分别演化出关注不同侧重点的提示词,最终组成性能最好的提示词组。
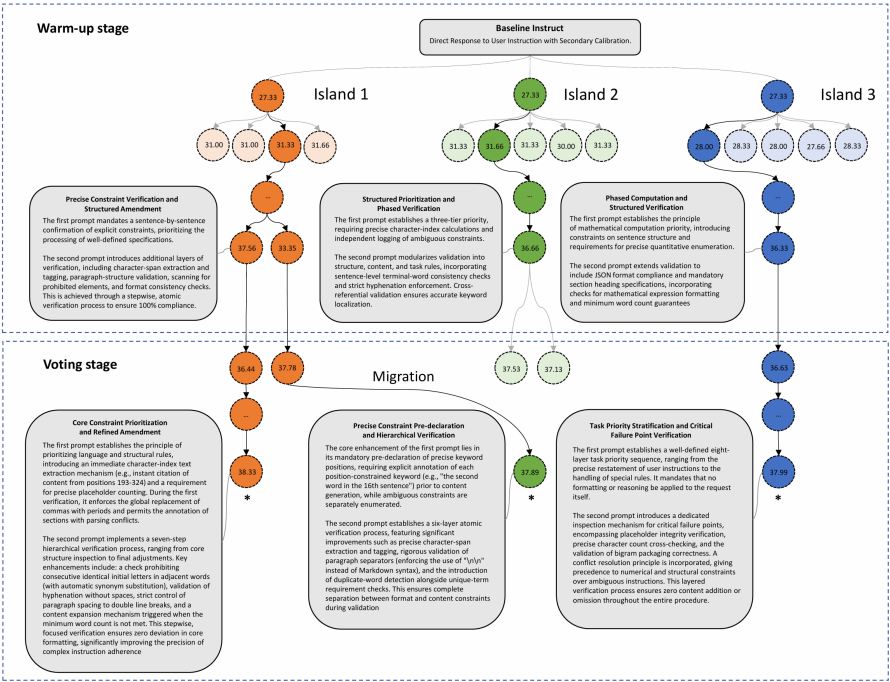
△IFBench任务提示词组进化过程可视化图
对训练过程中种群特征进行降维并可视化,也可以看出在共识表决进化阶段,不同种群会显著地朝着不同方向进化,这保证了组内的多样性和互补性。
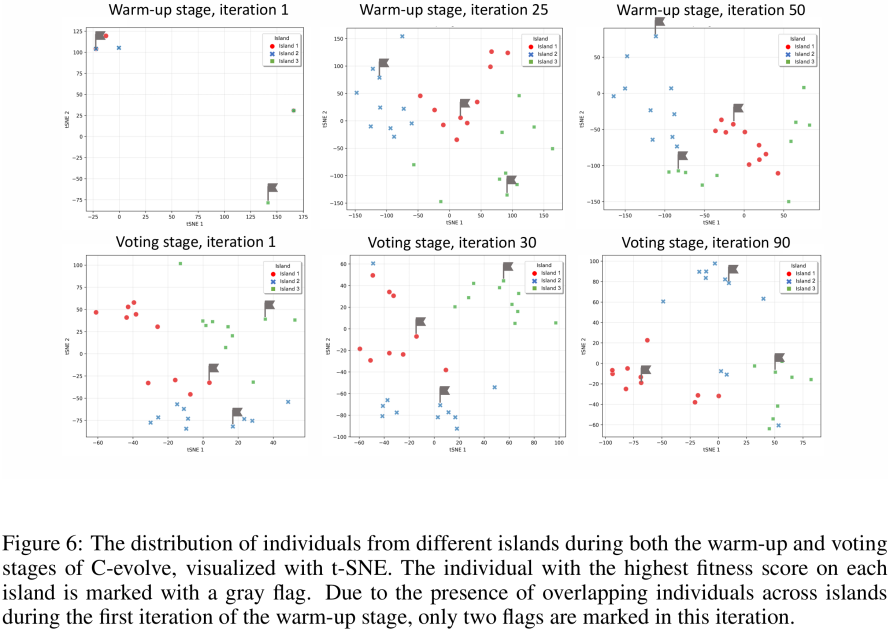
△C-Evolve进化过程中提示词种群分布
走向更高效的提示词优化
总而言之,这篇文章介绍了一种基于共识机制和进化算法的多提示词优化方法,C-Evolve。
通过系统性优化和融合多提示词的智能特征,该方法能够有效突破单一系统提示词的性能局限,无需参数微调即可实现算法效能的显著提升。
在上下文工程日益彰显其重要性的今天,如何通过更好地设计提示词,挖掘诸如Claude、GPT等成熟商业LLM的模型能力,是一个具有极高实际意义的课题。
「共识机制」为提示词优化提供了全新的思路,通过模拟生物进化与群体协作的动态过程,不仅提升了提示词的性能,还增强了模型在复杂任务中的适应能力,有望进一步释放大语言模型的潜力,推动智能系统向更高效、更自适应的方向发展。
论文地址:https://arxiv.org/abs/2509.23331


