
大家好,我是肆〇柒。在本文我们要一起了解的是来自阿里巴巴通义实验室(Tongyi Lab, Alibaba Group)的前沿研究成果——WebWeaver框架。这篇论文直面AI Open-ended深度研究(OEDR)的核心挑战,不是简单堆砌算力,而是从人类认知过程汲取灵感,构建了一个能让AI像博士生一样思考、探索、写作的智能系统。它究竟如何让AI摆脱“机械执行”,走向“有机探索”?下面让我们一探究竟。本文是通义 Deepresearch 发布的系列研究之一。
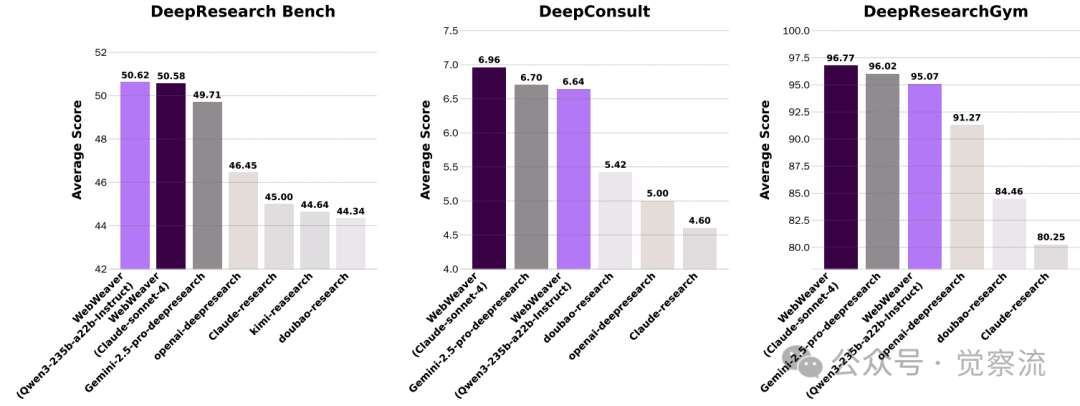
不同深度研究智能体在 DeepResearch Bench、DeepConsult 和 DeepResearchGym 上的表现(DeepResearch Bench 结果取自官方排行榜)。而本文中的 WebWeaver 达到了业界最佳水平
OEDR的挑战与WebWeaver的答案
核心问题:如何让AI系统处理那些没有标准答案、需要从海量信息中合成洞见的复杂问题?
在人工智能发展的新阶段,Open-ended深度研究(Open-Ended Deep Research, OEDR)成为关键挑战。这类任务要求AI智能体必须从网络规模的信息中合成有洞察力的报告,而非简单解答有明确答案的问题。当前OEDR系统面临双重困境:静态研究流程将规划与证据获取脱节,创建了一条"对新发现视而不见"的刚性研究路径;一次性生成范式容易遭受"中间丢失"(loss in the middle)和幻觉等长上下文失败问题。
WebWeaver提供了一个创新性解决方案:它通过模仿人类研究者"动态规划"和"分而治之"的认知过程,重构了OEDR的解决范式。在WebWeaver框架中,大纲不是研究的起点,而是一个"活文档",随着证据的积累不断进化;写作不是一次性任务,而是基于记忆的分层合成过程。这一设计使WebWeaver在多项基准测试中确立了新的SOTA地位,为解决OEDR挑战提供了新思路。
Planner与Writer的认知分工
核心问题:如何设计一个能真正"有机"探索的AI研究系统,而非执行机械流程的机器人?
WebWeaver的核心创新在于其双智能体架构,该架构精确映射了人类研究者的认知工作流程。如下图所示,框架由Planner(规划者)和Writer(写作者)两个智能体组成,它们各司其职又紧密协作,共同完成复杂的OEDR任务。
Planner负责探索性研究阶段,通过动态循环不断优化研究方向。在这个过程中,Planner不是一次性制定完整计划,而是根据获取的新证据持续调整研究路径。当Planner认为研究已足够全面时,它会生成一个详细的、与证据强绑定的研究大纲,作为Writer工作的基础。
Writer则负责报告撰写阶段,执行基于记忆的分层合成过程。与传统方法将所有证据一次性输入LLM的做法不同,Writer采用"分而治之"的策略,逐节撰写报告,每次只关注与当前部分相关的证据。
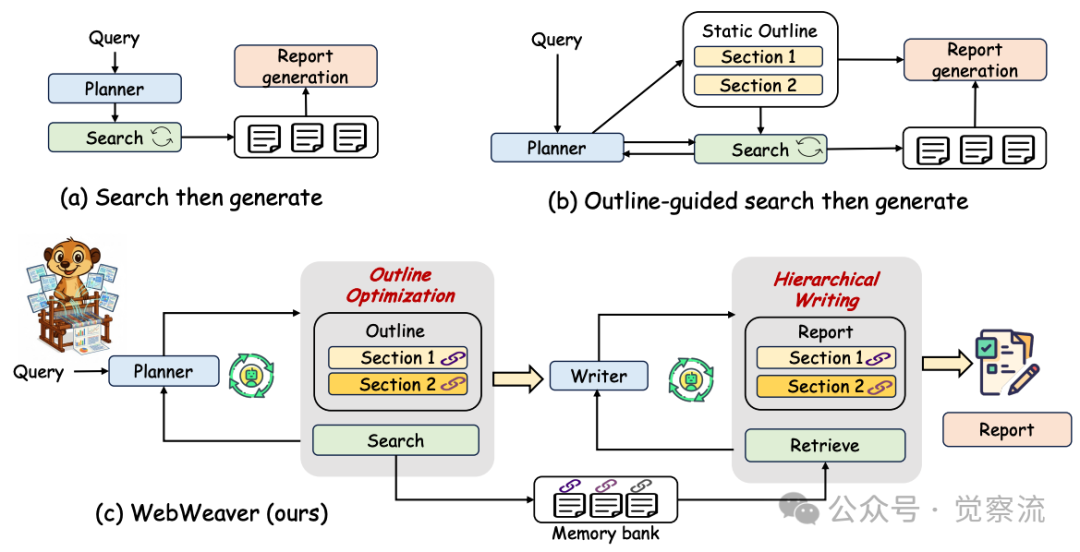
WebWeaver与传统研究范式的对比
这种双智能体架构与现有范式有着本质区别。如上图(a)所示,传统"搜索后生成"范式先收集信息再直接生成报告,容易导致信息过载和幻觉;上图(b)的"大纲引导搜索"范式先生成静态大纲再进行针对性搜索,限制了研究的深度和广度。相比之下,上图(c)展示的WebWeaver不仅实现了大纲与搜索策略的共同进化,还通过分层写作确保了报告的质量。
WebWeaver的设计哲学源于对人类认知过程的深刻理解:人类专家不会在开始前就固定全部计划,而是允许大纲成为一个"活文档"。WebWeaver正是对这一原则的算法实现,它通过动态循环支持真正的探索,通过分层写作保障深度合成。
基于新发现的持续优化
核心问题:如何避免研究被初始计划所束缚,真正实现"有机"探索?
Planner的核心能力在于其动态研究循环,这是一个持续迭代的证据获取与大纲优化过程。Planner的动作空间包括search、outline optimization和terminate三种基本操作,通过这些操作构建了一个有机的研究流程。
Planner的动态研究循环包含三个核心阶段:
1. 思考决策阶段:Planner首先进入Think状态,评估是否需要搜索新信息。这一阶段的关键在于避免盲目搜索,确保每次查询都有明确目标。
2. 证据获取阶段:若需搜索,Planner生成精确查询并执行Search操作,系统返回URL及摘要。Planner随后筛选页面,生成摘要供后续规划,并提取详细证据存入记忆库。
3. 大纲优化阶段:基于新证据,Planner扩展或重构大纲节点,插入<citation>id_x</citation>标签链接至证据ID。这一循环持续进行,直至Planner认为大纲已足够全面,发出<terminate>信号。
这一动态大纲优化机制代表了研究范式的根本转变。首先,大纲不再是研究的起点,而是一个"活文档",随着研究的深入不断演进;其次,每个大纲节点都通过引文明确链接到记忆库中的具体证据,确保了报告的证据支撑;最重要的是,这种机制允许探索新发现,避免被初始计划所束缚,使研究能够真正"有机"发展。
Planner的Outline Optimization不是简单添加内容,而是"基于新证据扩展或重构大纲节点"的智能过程。当Planner发现新证据与现有大纲不符时,它会重新评估研究方向,甚至"restructure the entire outline"。这种能力使WebWeaver能"发现并整合初始计划中未预见的关键视角",而传统静态大纲方法则"fossilizes"研究过程,无法适应新发现。
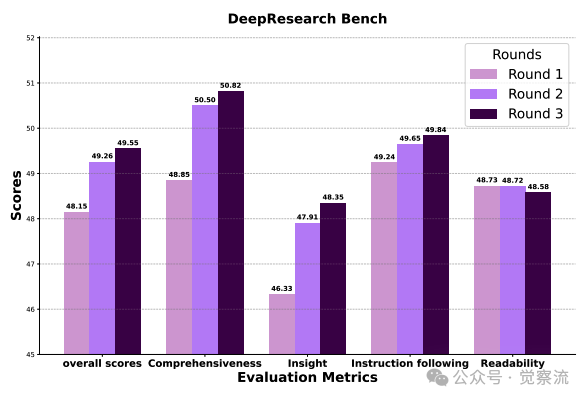
DeepResearch Bench上不同大纲优化轮次的端到-端评分
上图提供了动态优化价值的直接证据:随着优化轮次增加,Comprehensiveness从46.33稳步提升至49.65,Insight从46.33跃升至50.02。这种提升并非简单的信息堆砌,而是源于"更有效接地"的结构——Support指标从95.91显著提升至98.33,证明后期轮次的大纲建立了"计划部分与可用证据之间更强的映射关系"。
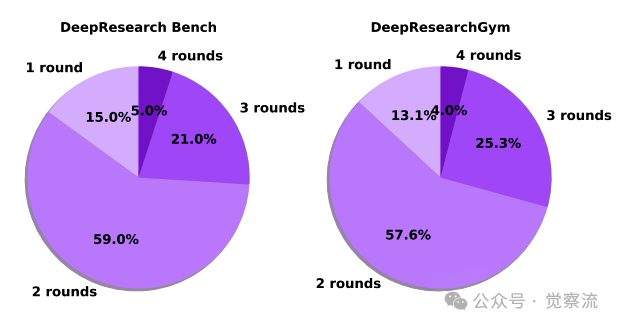
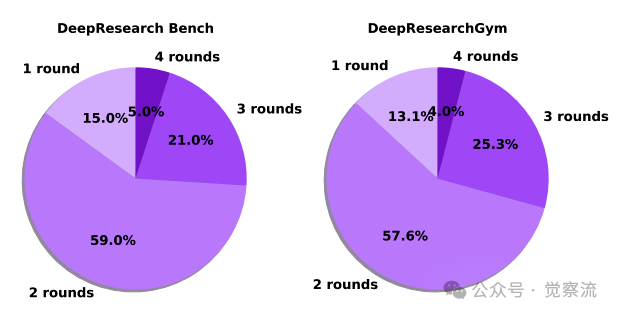
WebWeaver-SFT中大纲优化的轮次统计
上图显示,大多数案例在2~3轮内完成优化(54.4%+28.2%),证明该循环具有良好的实用性。如下表所示,WebWeaver-SFT平均执行14.67次搜索步骤和2.18轮大纲优化,保存106.65个网页,处理超过62,000个证据token。这些数据直观解释了为何动态研究循环必不可少——面对如此庞大的信息量,静态大纲方法必然导致"对新发现视而不见"。

WebWeaver-SFT的规划和写作统计数据
值得注意的是,这次优化是在精心打磨一份更优质、更连贯、也更有支撑的框架”。论文中说的清楚:关键不在于多写几段,而在于把提纲做细——支持度从95.91一路升到98.33就是最好的证明;框架一稳,论点就能死死咬住论据,严丝合缝。
如何避免"中间丢失"的写作艺术
核心问题:面对超过100ktoken的证据,如何生成连贯、准确的20k+token报告?
Writer的分层合成引擎通过"分而治之"的策略,有效解决了长上下文生成的核心挑战。如下图所示
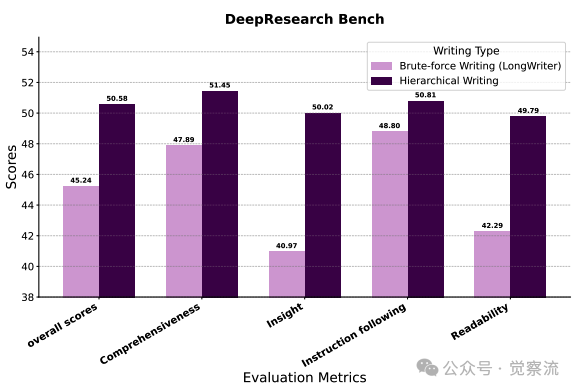
分层写作与暴力写作在DeepResearch Bench上的性能对比
传统"暴力写作"方法在长上下文任务中表现不佳,而WebWeaver的分层写作机制则显著提升了报告质量。
Writer的工作流程严格遵循"思考-检索-写作"的循环:
1. 任务界定:Writer首先确定当前子任务("让我们撰写第一部分")
2. 针对性检索:仅从记忆库中提取大纲中引文指定的相关证据
3. 内部合成:在Think阶段进行推理与洞察合成
4. 内容生成:生成文本并封装在<write>标签内
5. 上下文管理:完成部分后修剪上下文,替换为占位符
这一机制的核心创新在于“动态检索—剪枝”策略。正如论文所述:“只有当内部构思方案形成后,作者才会进入写作阶段,将内容写入 <write> 标签内;一旦某一部分完成,其对应的原始材料会立即从上下文窗口中剪除,并以占位符替代。”
以帕金森病DBS手术患者家庭护理指南的撰写为例,Writer在处理"Device Programming and Optimization"部分时,仅检索与"Initial activation 2-4 weeks post-surgery"和"Optimization period of 4-6 months"相关的证据ID,避免了信息过载。具体大纲结构如下:
复制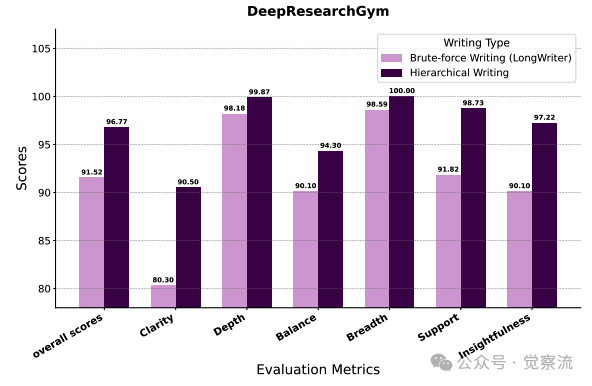
分层写作与暴力写作在DeepResearchGym上的性能对比
上图提供了直接证据:WebWeaver的分层写作机制在Support指标上从91.82跃升至98.73,证明了其有效防止"上下文污染"(contextual bleeding)的能力。上下文污染指已完成部分的信息错误地影响后续内容生成的现象,这一提升验证了"注意力管理"假设——通过聚焦当前部分,写作质量得到实质性提升。
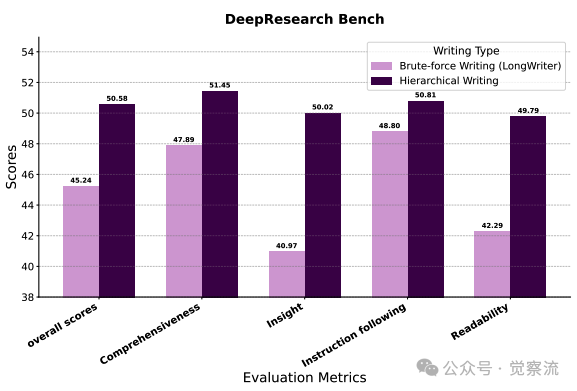
分层写作与暴力写作在DeepResearch Bench上的性能对比
上图进一步显示,这一机制在insight(40.97→50.02)和readability(42.29→49.79)指标上分别提升了9.05和7.5分,直接验证了"注意力管理"假设——通过聚焦当前部分,写作质量得到实质性提升。

WebWeaver-SFT的规划和写作统计数据
上表的数据进一步支持了这一设计的必要性:Writer平均执行22.76次写作步骤,生成22,637个输出token,同时处理14,155个摘要token。这些数字表明,分层写作不仅是一种理论设计,更是应对长上下文挑战的实际需求。
记忆库与工具系统的协同设计
核心问题:如何管理超过100ktoken的证据并确保高质量的写作输出?
上述动态研究循环与分层写作机制的高效运行,离不开一个看不见但至关重要的支撑系统——记忆库与工具链的协同设计。
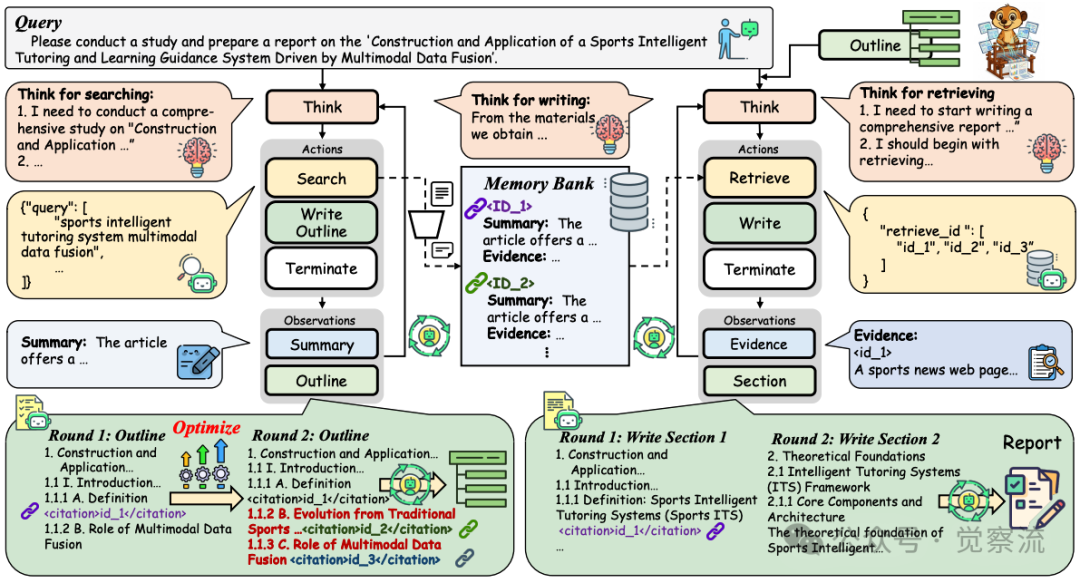
WebWeaver框架架构图
如上图所示,记忆库采用双重存储结构:每个证据ID对应摘要(用于规划阶段)和详细证据(用于写作阶段)。这种设计解决了OEDR任务中的长上下文瓶颈——Planner通常需要搜索超过100个网页(超过100ktoken),而Writer最终需要生成超过20ktoken的综合报告。
记忆库的核心功能是通过引用机制实现的。在Planner生成的大纲中,每个部分都包含<citation>id_x</citation>标签,这些标签精确链接到记忆库中的证据ID。当Writer需要撰写某一部分时,它只需检索这些特定ID对应的证据,避免了处理全部原始材料的需要。
记忆库的双重存储设计确保了高效的信息处理:Planner能快速评估证据价值(通常处理摘要信息),而Writer在撰写特定部分时仅检索相关详细证据。研究案例显示,Writer在撰写"帕金森病DBS手术患者家庭护理指南"时,仅检索与"患者舒适措施、设备故障排除和术后药物管理"相关的证据ID,避免了信息过载。
WebWeaver还深度应用了ReAct框架,确保Planner和Writer都能执行完整的Thought-Action-Observation循环。这一设计使智能体能够进行可解析的思考,执行环境交互,并基于观察结果调整策略,形成完整的认知闭环。
工具链的协同工作也是WebWeaver成功的关键。系统整合了:
- 搜索引擎:获取原始网页
- URL筛选器:过滤低质量结果
- 摘要生成器:提炼关键信息供规划
- 证据提取器:存储详细内容供写作
- 检索系统:按需获取相关证据
这些工具配合得天衣无缝,让 Planner 和 Writer 各展所长、高效完成各自任务。正如论文所述:“这种默契分工使我们的智能体能够在纷繁复杂的信息海洋中穿梭自如,最终生成既视野全面、又证据扎实的报告。”
用数据说话——为什么WebWeaver是当前最强?
核心问题:WebWeaver的性能优势如何量化?其核心机制的实际效果如何验证?
WebWeaver的卓越性能在三大基准测试中得到验证:
在DeepResearch Bench上,WebWeaver(Claude-sonnet)以50.58分确立SOTA地位,超越Gemini-2.5-pro(49.71)和OpenAI-deepresearch(46.45)。DeepConsult测试中,WebWeaver以66.86%的胜率领先所有系统。而在DeepResearchGym上,WebWeaver获得96.77的平均分,Depth和Breadth指标接近满分(100.00)。
深入分析关键指标发现:
- 高引用准确性:C. acc.达85.90%,证明报告严格基于证据,大幅减少了幻觉问题
- 高有效引用数:Eff. c.高达90.89,表明Planner具有内在动力,会主动寻求更多证据,以确保每一部分都有充分支持
- 卓越的深度与广度:Depth和Breadth接近满分,显示动态研究循环使报告超越静态规划局限
WebWeaver的性能优势可概括为"三个90+":
- 90%+的引用准确率(C. acc. 85.90%)
- 90+的有效引用数(Eff. c. 90.89)
- 90+的综合评分(DeepResearchGym 96.77)
消融实验提供了更具说服力的证据:
1. 动态大纲优化价值:如下图显示,随着Outline Optimization轮次增加,Comprehensiveness和Insight评分稳步上升。这一提升不仅反映了内容扩充,更体现了证据支撑质量的实质性提升。
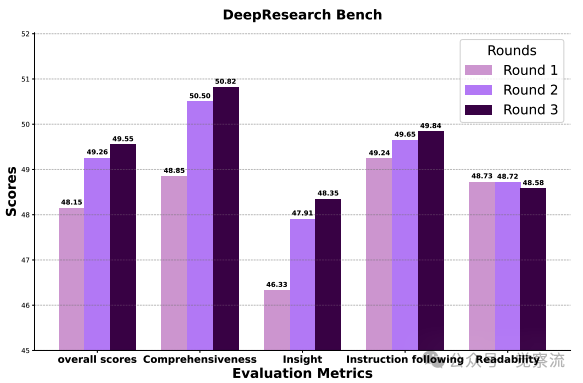
DeepResearch Bench上不同大纲优化轮次的端到-端评分
2. 收敛效率:如下图显示,大多数案例在2~3轮内完成优化(54.4%+28.2%),证明该循环具有良好的实用性。
WebWeaver-SFT中大纲优化的轮次统计
3. 分层写作必要性:下表显示,WebWeaver在Support指标上达到98.73,远超其他系统。
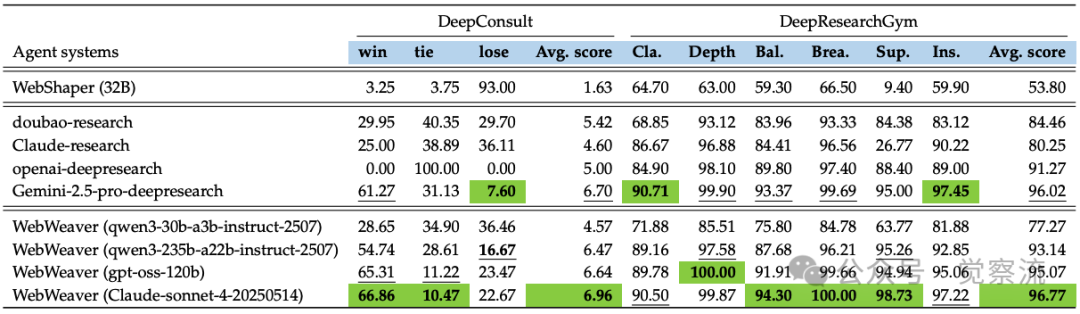
DeepConsult和DeepResearchGym上的性能比较
如下图所示,这一机制有效防止了"上下文污染",将Support指标从91.82提升至98.73。
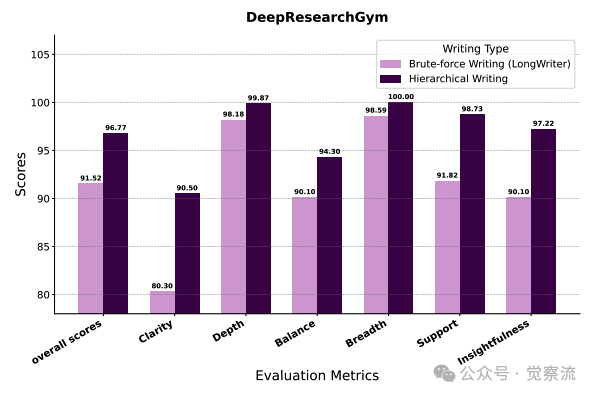
分层写作与暴力写作在DeepResearchGym上的性能对比
下表揭示了OEDR任务的复杂性:Planner平均执行14.67次搜索步骤和2.18轮大纲优化,保存106.65个网页,处理超过62,000个证据token。这些数据直观解释了为何动态研究循环必不可少——面对如此庞大的信息量,静态大纲方法必然导致"对新发现视而不见"。

WebWeaver-SFT的规划和写作统计数据
教一个学生,而不是造一台机器——WebWeaver-3k的蒸馏之道
核心问题:如何让较小模型也能掌握专家级OEDR能力?
WebWeaver的另一个重要贡献是WebWeaver-3k数据集,这是一个高质量的监督微调(Supervised Fine-Tuning, SFT)数据集,用于提升较小模型的OEDR能力。
WebWeaver-3k采用自举式方法生成:首先使用强大的教师模型(如Claude Sonnet)在WebWeaver框架内执行端到端研究任务,然后通过严格筛选,仅保留"成功执行完整研究流程的样本",排除任何中途失败或质量不达标的轨迹。这些样本包含了"复杂的多轮工具调用序列和长上下文推理过程",为训练模型提供了从"思考-搜索-写作"的完整认知闭环学习机会。
WebWeaver-3k的蒸馏效果极为显著:微调前模型的引用准确率(C. acc.)仅为"几乎不可用的25%",微调后跃升至可靠的85.90%。这一飞跃提供了直接证据,证明模型已掌握Writer智能体的复杂机制——能够执行精确的证据检索工具调用,并严格依据基于证据的大纲进行写作。
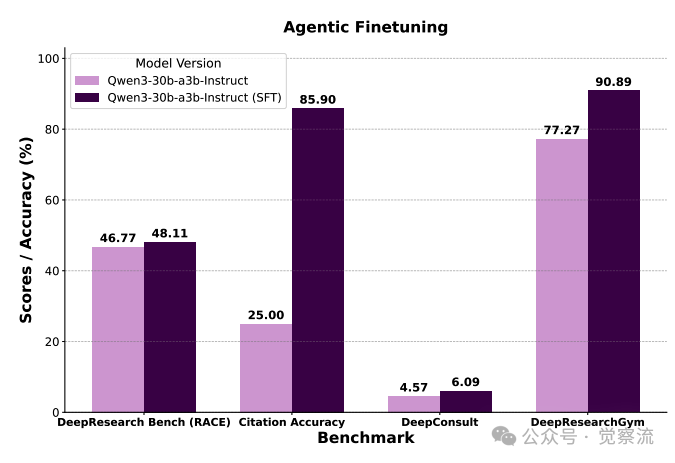
WebWeaver-3k在DeepResearch Bench上的性能提升
如上图所示,经过WebWeaver-3k微调的Qwen3-30B模型在DeepResearch Bench上的得分从46.77提升至48.11,这一提升使其性能接近甚至超过某些闭源系统(如Gemini-2.5-pro的49.71)。
WebWeaver-3k的价值不仅在于提升模型性能,更在于建立了"框架生成数据→数据训练模型→模型增强框架"的良性循环。这种方法使OEDR能力不再局限于大型闭源模型,而是可以被更广泛的研究社区所利用和改进。
不只是框架,更是方法论——我们该如何构建未来的AI研究员?
WebWeaver的核心价值不仅在于其技术实现,更在于它提出了一种全新的研究范式。如论文所述:"人类专家不会在开始前就固定全部计划,而是允许大纲成为一个'活文档'。WebWeaver正是对这一原则的算法实现——通过动态循环支持真正的探索,通过分层写作保障深度合成。"
这一设计代表了范式级的创新:它将不可控的长上下文问题,转化为可控的系统级信息管理问题;它证明复杂认知任务可以通过"动态适应+分层合成+强接地性"可靠解决;它为构建能处理知识密集型任务的AI系统提供了新思路。
WebWeaver不仅是一个性能更强的系统,更是一种思维方式的转变。未来的AI研究员应该具备"探索性思维"而非"机械执行",通过"刻意行动"而非"暴力注意力"掌握知识。正如研究结尾所强调的:"这一工作不只呈现了更好的智能体系统,更提供了构建能通过刻意行动而非蛮力注意力掌握密集知识的智能体系统的新蓝图。"
WebWeaver 的价值,在于它改写了 AI 攻克复杂知识题的路径。它不再死守“机器流水线”,而是像人一样“边想边找、边找边想”——把研究做“活”了。结果是:不仅分数更高,AI 第一次跑通了“深度研究”,而不是停留在“拼摘要”。


