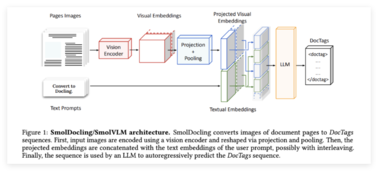
近日,VLM-R1项目的成功推出为这一领域带来了新的曙光。该项目是 DeepSeek 团队的 R1方法在视觉语言模型中的成功迁移,意味着 AI 对视觉内容的理解将进入一个全新的阶段。
VLM-R1的灵感源自于去年 DeepSeek 开源的 R1方法,该方法利用了 GRPO(Generative Reward Processing Optimization)强化学习技术,在纯文本处理上取得了优异的表现。如今,VLM-R1团队将这一方法成功地应用于视觉语言模型,为多模态 AI 的研究开辟了新天地。

在项目的验证结果中,VLM-R1的表现令人惊艳。首先,R1方法在复杂场景下展现出了极高的稳定性,这在实际应用中显得尤为重要。其次,该模型在泛化能力方面表现卓越。在对比实验中,传统的 SFT(Supervised Fine-Tuning)模型在领域外的测试数据上随着训练步数的增加,其性能却逐渐下滑,而 R1模型则能在训练中不断提升。这表明,R1方法使得模型真正掌握了理解视觉内容的能力,而非仅仅依赖于记忆。
此外,VLM-R1项目的上手难度极低,团队为开发者提供了完整的训练和评估流程,让开发者可以快速上手。在一次实际案例中,模型被要求找出一张丰盛美食图片中蛋白质含量最高的食物,结果不仅回答准确,还在图片中精准框选出蛋白质含量最高的鸡蛋饼,展示了其出色的视觉理解和推理能力。
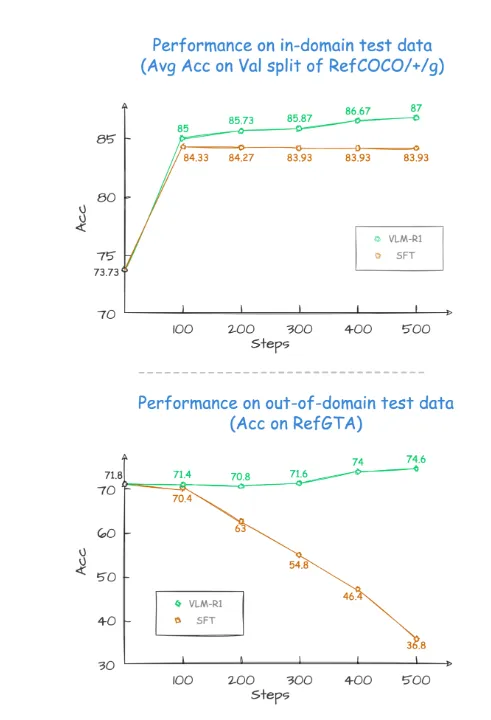
VLM-R1的成功推出不仅证明了 R1方法的通用性,也为多模态模型的训练提供了新思路,预示着一种全新的视觉语言模型训练潮流的到来。更令人振奋的是,该项目完全开源,感兴趣的开发者可以在 GitHub 上找到相关资料。

总之,VLM-R1的问世为视觉语言模型的研究注入了新的活力,期待更多开发者能够参与其中,推动多模态 AI 技术的不断进步。