
本文来自于香港中文大学 MMLab 和 vivo AI Lab,其中论文第一作者肖涵,主要研究方向为多模态大模型和智能体学习,合作作者王国志,研究方向为多模态大模型和 Agent 强化学习。项目 leader 任帅,研究方向为多模态大模型、Agent 及具身智能,指导教师是香港中文大学 MMLab 的李鸿升教授。
近年来,多模态大模型(MLLM)在理解和生成任务上取得了巨大突破。学术界和工业界不再仅仅满足于让模型进行聊天和 AIGC,而是致力于将其打造为能够自主规划、执行复杂任务的智能体(Agent)。其中,移动 GUI(图形用户界面)智能体 —— 即能够在智能手机上理解人类指令、自主操作 APP 完成复杂任务的 AI 系统,正在成为 AI 领域的新热点。
然而,如何让一个多模态大模型在手机界面上学会像人类一样 “看懂屏幕、规划步骤、执行任务”,一直是个棘手的难题。一个根本的瓶颈在于数据:这些智能体严重依赖大规模、高质量的专家演示轨迹(即 “一步一步怎么点”)进行微调,而这类数据需要昂贵的人工标注成本,极大地限制了智能体的泛化能力和鲁棒性。
来自香港中文大学 MMLab、vivo AI Lab、上海人工智能实验室等机构的研究团队提出了一个能够自我进化的框架 UI-Genie,它通过让智能体模型(Agent)与奖励模型(Reward Model)相互协作、共同演化,实现无需人工标注的高质量数据合成与能力持续提升。该工作已经被 NeurIPS2025 会议接收。

论文标题:UI-Genie: A Self-Improving Approach for Iteratively Boosting MLLM-based Mobile GUI Agents
论文地址:https://arxiv.org/abs/2505.21496
开源模型及数据集地址:https://huggingface.co/collections/HanXiao1999/ui-genie
GitHub 地址:https://github.com/Euphoria16/UI-Genie
核心突破:从 "被动学习" 到 "主动进化"
训练一个移动 GUI 智能体通常需要使用高质量的轨迹数据(包含任务指令、屏幕截图与正确动作)。然而,这类数据的获取面临两大挑战:
1. 轨迹验证困境
与常规问答任务不同,GUI 操作的正确性高度依赖于历史上下文。例如,在 “将外卖订单截图分享到微信好友” 这样的任务中,判断点击 “发送” 按钮是否正确,必须知道之前是否已选中正确的联系人。现有评估方法,包括用商用模型打分的方式,难以准确判断每一步操作的有效性及最终是否完成任务。
2. 数据规模瓶颈
由于缺乏可靠的轨迹验证方法,当前训练仍依赖人工标注的演示数据,不仅成本高昂,也难扩展到长链路、跨应用的复杂任务。
因此,如何让智能体自主地、低成本地产生高质量训练数据,是提升移动 GUI 智能体的关键。针对这一问题,UI-Genie 提出了一个创新解决方案,包括两部分:一是专为移动 GUI 操作设计的奖励模型 UI-Genie-RM,二是用于智能体和奖励模型共同进化的训练闭环。
一、UI-Genie-RM:首个移动 GUI 轨迹评估的 “专业裁判”
为了解决轨迹验证的难题,UI-Genie 首先构建了一个强大的奖励模型 —— UI-Genie-RM。这是首个专为移动 GUI 智能体轨迹评估而设计的奖励模型。
1. 架构设计
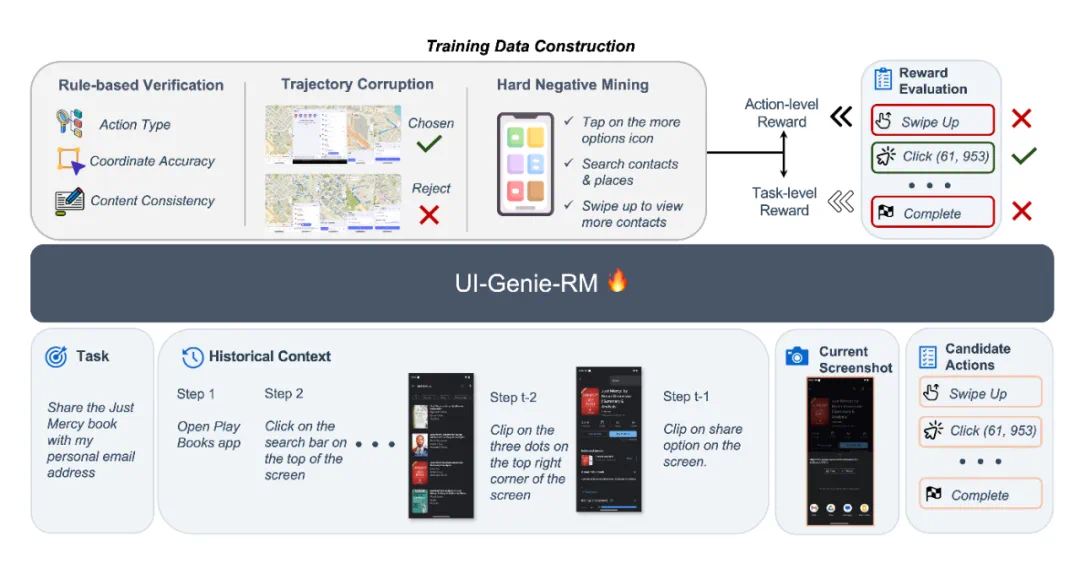
UI-Genie-RM 的设计充分考虑了 GUI 操作任务的特性。它不仅要判断当前动作是否正确,还需要理解整个操作历史,这对于跨应用、多步骤任务尤为关键。因此 UI-Genie-RM 采用图像 - 文本交错的架构,处理以下四种输入:
任务目标(Task Goal): 用户下达的自然语言指令。
当前截图(Current Screenshot): 手机当前的屏幕状态。
候选动作(Candidate Action): 智能体下一步打算做什么。
历史上下文(Historical Context): 包括最近 5 步的截图和已执行的动作序列(以自然语言描述形式进行总结)。
这种设计确保了长期上下文信息的覆盖,又避免了处理完整历史带来的计算开销。
2. 数据构建
为了训练一个有效的 GUI 奖励模型,研究团队设计了三种自动化的数据生成策略,总计构建约 51.7 万条奖励样本:
基于规则的验证(Rule-based Verification): 利用动作类型匹配、坐标准确性、语义一致性等规则筛选正负样本;
受控的轨迹破坏(Controlled Trajectory Corruption): 在正确轨迹中注入错误步骤,模拟失败操作。
困难负样本挖掘(Hard Negative Mining): 专门生成那些 “看起来合理但其实错误” 的候选动作,提升模型判别力。
二、自我进化:智能体与奖励模型的 “双向增强”
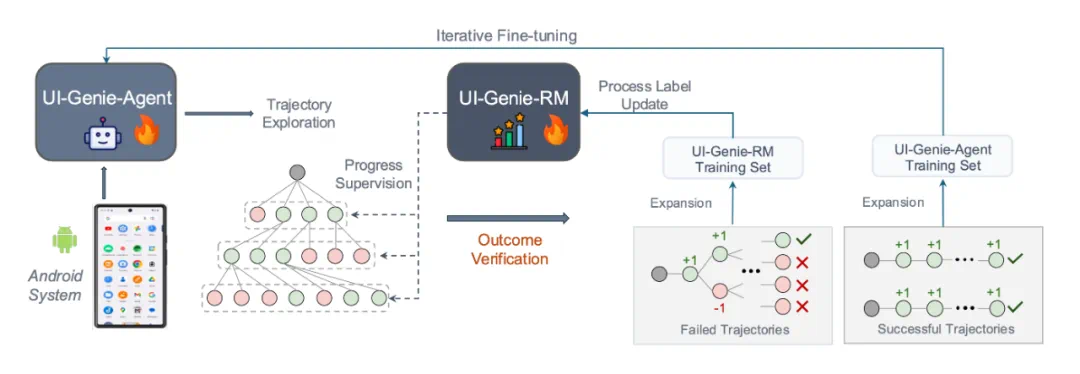
在拥有可靠 “裁判” 后,UI-Genie 启动了其核心机制 —— 数据生成和模型迭代的闭环,这个过程包含三个关键环节:
1. 奖励引导的轨迹探索
智能体模型在 Android 模拟环境中生成多条候选轨迹,由 奖励模型打分,并保留累计得分最高的 5 条路径继续探索。这种 beam search 策略比传统蒙特卡洛树搜索更高效,尤其适用于 GUI 场景(如点击无效区域不改变状态)。
2. 训练数据双向扩展
探索得到的轨迹同时用于强化两个模型:
为智能体扩充训练数据:奖励模型验证并筛选出 “成功轨迹”,加入到智能体的训练数据中。
为奖励模型扩充监督信号:对失败轨迹中的每一步进行延续推演,若从该步出发能最终成功,则将其标注为正例,自动生成细粒度的监督信号。
3. 渐进式任务复杂度提升
在自我进化的过程中,共进行了三轮迭代,每一轮迭代任务难度逐步增加:
第一轮:使用开源轨迹数据集中包含的任务指令。
第二轮:通过开源 LLM 改写和扩展第一轮的任务指令。
第三轮: 融合前两轮失败任务与人工设计的复杂场景(如超过 10 步的任务)。
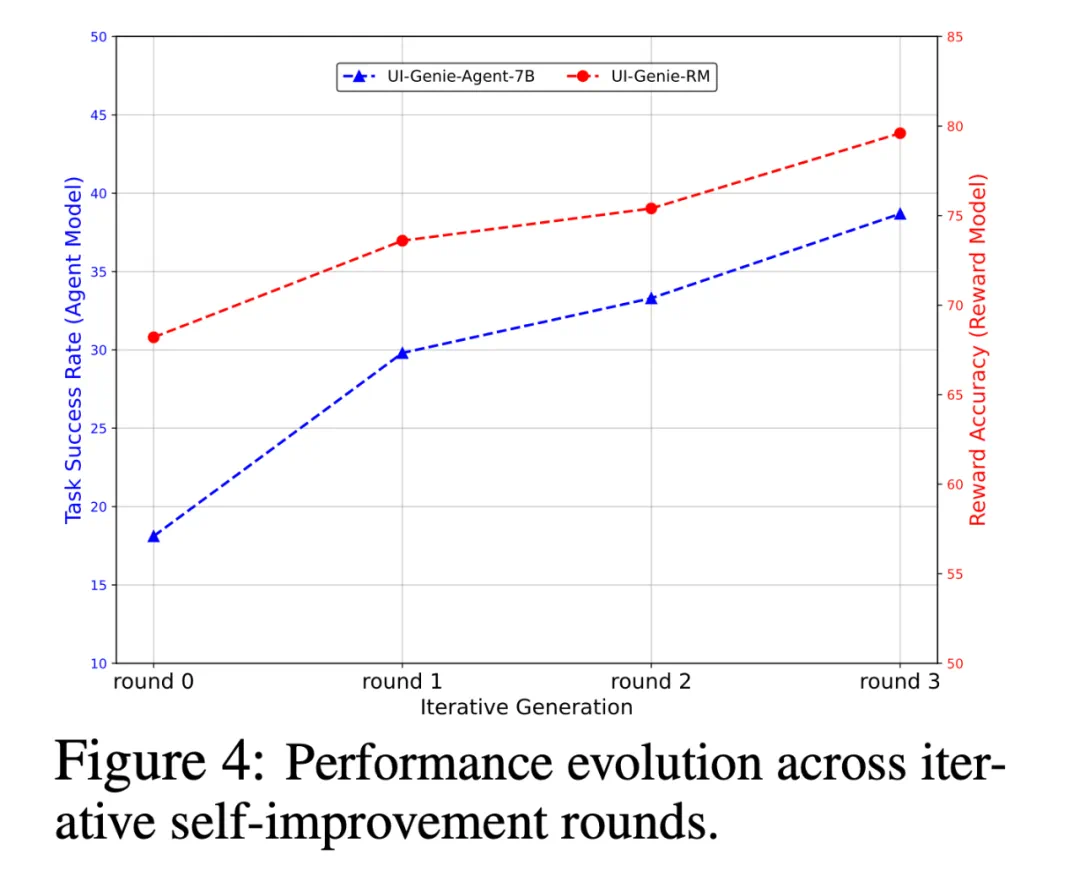
这一闭环,创造了一个正反馈循环:智能体模型在更多、更高质量的成功轨迹上训练,能力越来越强从而能通过探索完成更复杂的任务;奖励模型见过了更多样的成功与失败案例(尤其是智能体犯的新错误),评估更准。
任务评测
1. 离线操作任务
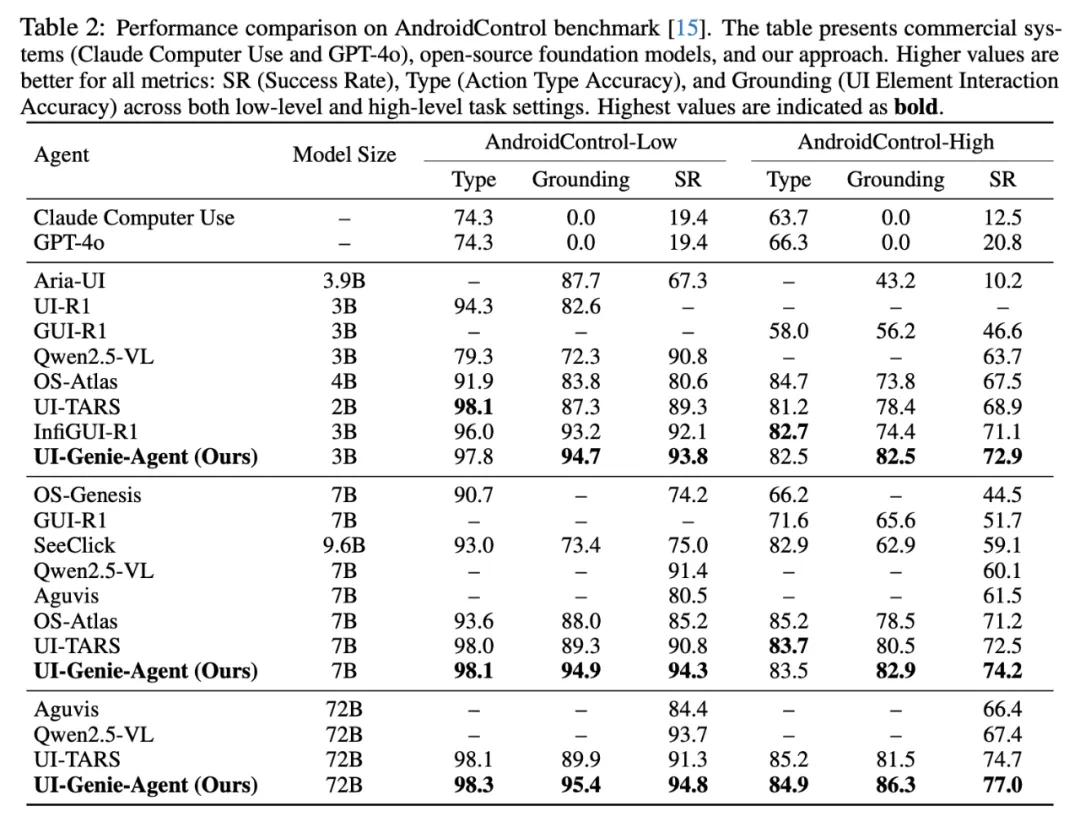
在 AndroidControl 基准上,UI-Genie 在任务成功率(SR)与元素定位准确率(Grounding)上全面超越基线方法。其中 72B 模型在高级任务指令下取得 86.3% 的定位准确率与 77.0% 的操作成功率,体现了在奖励模型引导下更精准的 UI 理解能力和步骤规划能力。
2. 在线操作任务
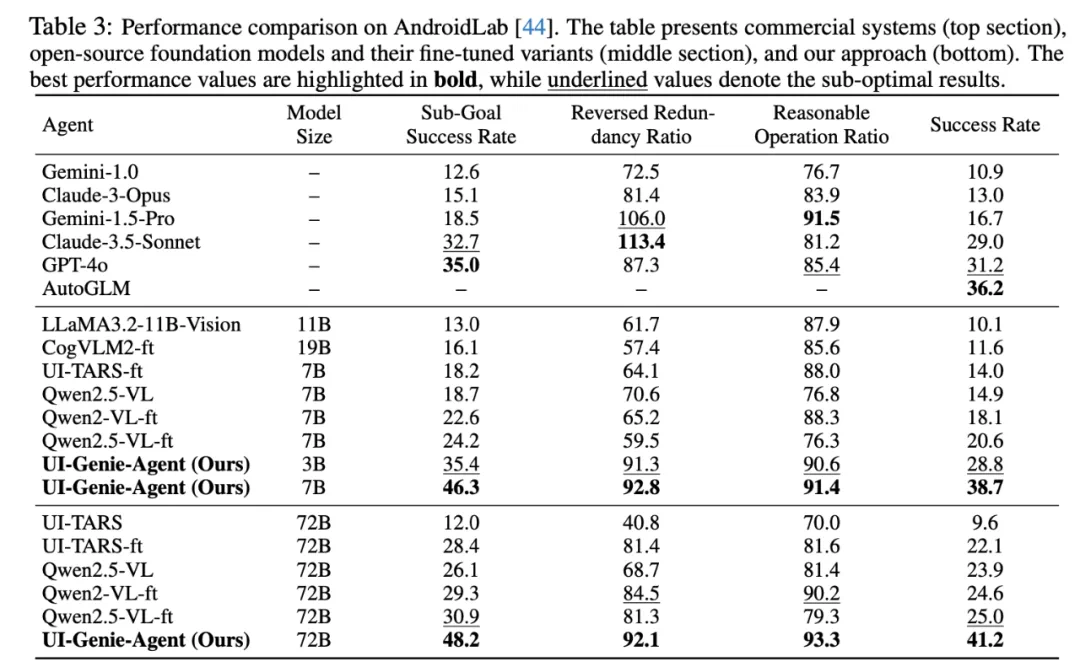
在 AndroidLab 的 138 个真实任务上,UI-Genie 的平均成功率显著高于商用与开源模型。其 3B 版本已能对标 7B 级别基线,7B 模型甚至超过部分 70B 级模型。
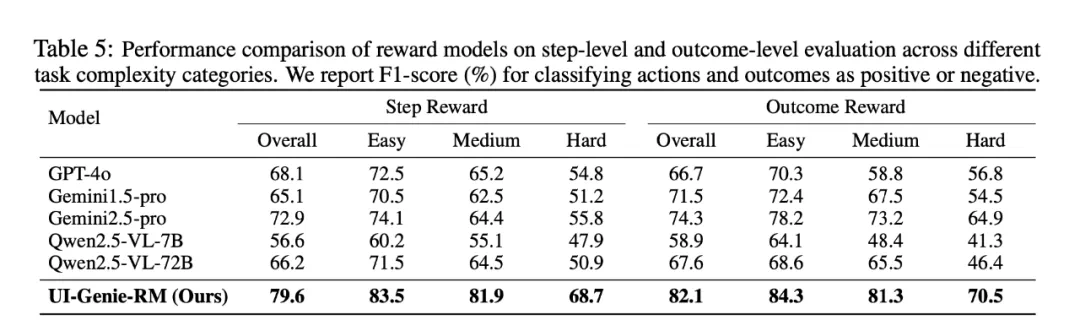
3. 奖励模型评估
在包含 1050 对样本的综合基准上,UI-Genie-RM 在步骤级与结果级评估中均表现最佳。实验同时验证了自我进化过程的有效性:经过三轮迭代,智能体在 AndroidLab 上的任务成功率从 18.1% 提升至 38.7%,奖励模型准确率从 68.2% 提高到 79.6%。
总结
UI-Genie 提出了一种创新的自我进化框架,通过构建专用奖励模型与协同迭代机制,实现了自动化的数据生成与训练闭环。该工作打破了人工标注瓶颈,不仅在多个基准上刷新了 SOTA,也为解决智能体训练中的数据稀缺与验证难题提供了新范式。未来,研究团队计划将该框架扩展至桌面端智能体等更复杂的多模态交互场景,并探索奖励模型与强化学习的深度结合,推动智能体实现真正的 “自主成长”。
未来展望
GUI Agent 作为 “端侧隐形助理”,正在重塑手机的交互方式,应用场景广泛扩展。在生活中,GUI Agent 可以跨应用协同原生日历、文档和邮件应用,自动完成会议安排、旅行计划与重要提醒,无需手动切换界面,显著提升工作效率。在娱乐场景下,它能够与手机自带的媒体播放器和相册无缝集成,智能识别播放控件,实现顺畅的指令操作,如调整音量、切换曲目或整理相册等,为用户提供更为流畅的手机使用体验。既为老年用户、视障人士简化手机使用门槛,也为忙碌人群提供 “动口不动手” 的便捷服务,未来更将融入智能网联生态成为连接手机与智能设备的核心交互枢纽,提供更自然的智能体验。


