随着通用型(Generalist)机器人策略的发展,机器人能够通过自然语言指令在多种环境中完成各类任务,但这也带来了显著的挑战。
一方面,真实世界评估成本极高,需要系统性地覆盖常规场景、极端情况、分布外(OOD)环境以及各类安全风险,通常需要进行成百上千次真实硬件实验,不仅耗时、昂贵,还可能存在操作风险。
另一方面,安全性评估尤为棘手,许多潜在的不安全行为(例如误夹人手、损坏设备或引发环境危险)本身就不适合在真实环境中反复测试,使得传统的硬件评估方法在安全场景下往往难以实施。
传统的物理仿真器虽然有帮助,但在真实感、多样性、搭建成本和视觉一致性方面仍存在明显瓶颈。
另外,前沿视频模型为世界仿真提供了一种替代路径,有望解决前文提到的诸多挑战。然而,要真正发挥这一潜力面临很多困难,主要原因包括:
1)在闭环、动作条件生成中容易产生伪影;
2)对接触动力学(如物体接触、碰撞)的仿真十分困难;
3)现代策略架构对多视角一致性提出了较高要求,而这在视频生成中并不容易满足。

论文地址:https://arxiv.org/pdf/2512.10675
项目主页:https://veo-robotics.github.io/
论文标题:Evaluating Gemini Robotics Policies in a Veo World Simulator
本文,来自 Google DeepMind Gemini Robotics 团队研究者提出了一种基于视频建模的机器人策略评估系统,能够支持机器人领域中完整范围的策略评估需求,包括分布内评估、分布外泛化评估,以及红队测试。

具体而言,该系统基于最先进的视频生成模型 Veo,实现了带动作条件约束、具备多视角一致性的视频仿真,不仅在视觉上高度真实,还能够对机器人细粒度控制做出合理响应。同时,该系统集成了生成式编辑技术,使得无需搭建真实物理场景,就能生成包含新物体、新视觉背景以及安全关键元素的多样化、逼真的真实世界场景变体。
通过 1600 余次真实世界实验,并在八个通用型策略检查点和五项任务上验证了视频模型预测结果的有效性。实验结果表明,该系统在保持底层视频基础模型原有能力的同时,达到了进行严格机器人评估所需的高保真度。
尽管视频建模在机器人领域仍处于早期阶段,但本文清晰地展示了一条利用视频仿真世界,实现机器人策略泛化能力与安全性可扩展评估的可行路径。
方法介绍
在模型架构方面,本文采用 Veo 2 作为基础模型。
在数据方面,模型在一个包含大量视频、图像及其对应标注的数据集上进行训练。这些文本描述由 Gemini 模型自动生成,并且所有数据都经过了严格的预处理与整理。
此外,本文在一个大规模机器人数据集上对预训练的 Veo2 模型进行了微调。该数据集包含多种任务,覆盖了在大量不同场景中所需的广泛操作技能。图 2(上)展示了一个示例,将渲染后的机器人位姿叠加在生成的视频帧之上的效果。

最后,为减轻部分观测带来的影响,本文将系统中的四个相机视角(包括俯视视角、侧视视角,以及左右腕部视角)拼接成一个整体输入。然后对 Veo2 进行微调,使其能够在给定初始帧和未来机器人位姿的条件下,生成这种拼接后的多视角未来帧。图 2(下)展示了一个由该模型生成的多视角视频帧示例。

实验
本文通过 1600 余次真实世界评估,在八个通用型策略检查点和五项任务上进行了实验。
在基于 Gemini Robotics On-Device(GROD)模型训练了端到端的 VLA 策略。随后,使用经过微调的 Veo(Robotics)视频模型,在分布内场景中对这些策略进行评估。
指令:把右上角的红色葡萄放入灰色盒子的左上角隔间。

指令:把乐高积木放进乐高积木袋里。

指令:把棕色的长条物放进午餐包的顶部口袋里。
研究中,作者还使用 Veo(Robotics)模型,对 8 个不同版本的 VLA 机器人策略进行性能预测,然后把这些预测结果与机器人在真实世界中的实际测试结果进行对比,以检验视频模型预测是否准确、可靠。如下 demo 展示了 Veo(Robotics)针对两种策略的实际运行示例。
下图比较了视频模拟预测结果与实际成功率。可以观察到,Veo(Robotics)能够根据性能对不同的策略进行排名。本文还发现预测成功率与实际成功率之间存在很强的相关性。
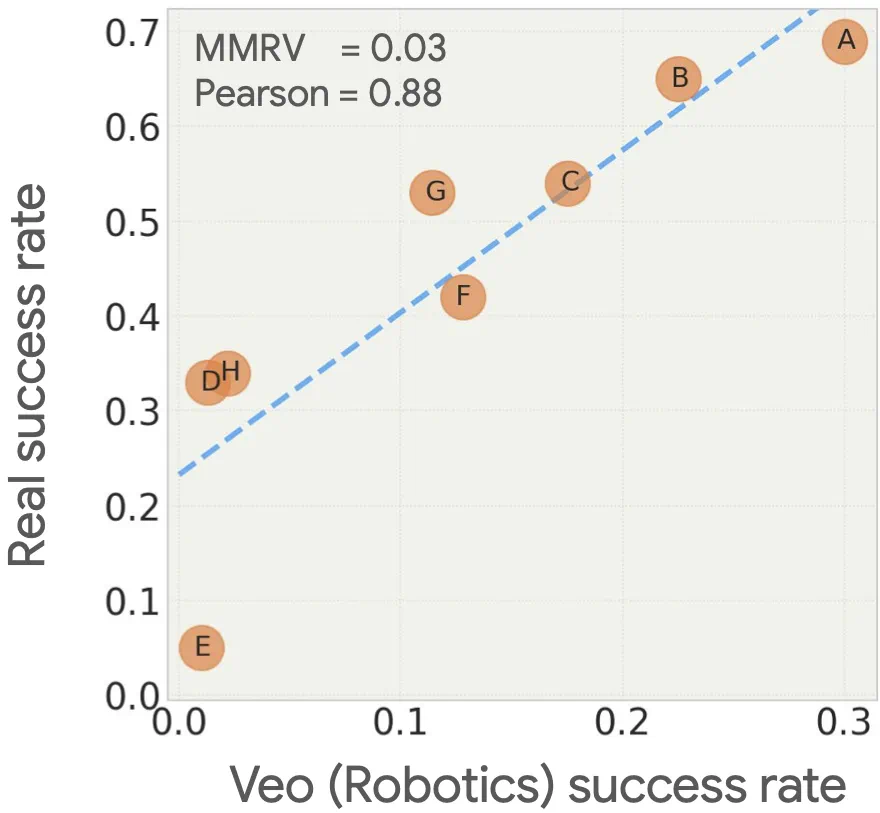
接下来作者测试了模型分布外泛化能力。通过改造真实场景来制造新情况,用视频模型提前预测机器人在陌生环境中的表现,并用真实实验验证这些预测是否靠谱。
最后,本文证明了 Veo(Robotics)世界模型可以用来做安全红队测试。也就是说,不需要先让机器人在真实世界中冒险,就可以在视频模拟的世界里主动寻找策略可能出现的不安全行为。
例如合上电脑:

快速抓取红色积木:

了解更多内容,请参考原论文。


