浙江大学、哈佛大学、南洋理工大学联合提出了统一的图像插入框架Insert Anything,支持多种实际场景,包括艺术创作、逼真的脸部交换、电影场景构图、虚拟服装试穿、配饰定制和数字道具更换,下图展示了其在各种图像编辑任务中的多功能性和有效性。

效果展示





相关链接
- 论文:https://arxiv.org/pdf/2504.15009
- 主页:https://song-wensong.github.io/insert-anything
论文介绍

插入任何内容:通过 DiT 中的上下文编辑插入图像
本研究提出了“Insert Anything”,这是一个基于参考的图像插入统一框架,可在用户指定的灵活控制指导下将参考图像中的对象无缝集成到目标场景中。我们的方法并非针对单个任务训练单独的模型,而是在我们新的AnyInsertion数据集上训练一次——该数据集包含 12 万个提示图像对,涵盖人物、物体和服装插入等多种任务——并可轻松推广到各种插入场景。如此具有挑战性的设置需要捕捉身份特征和精细细节,同时允许在样式、颜色和纹理方面进行灵活的局部调整。为此,我们建议利用扩散变换器 (DiT) 的多模态注意力机制来支持蒙版和文本引导的编辑。此外,论文引入了一种上下文编辑机制,将参考图像视为上下文信息,采用两种提示策略使插入的元素与目标场景协调一致,同时忠实地保留其独特特征。在 AnyInsertion、DreamBooth 和 VTON-HD 基准上进行的大量实验表明,提出的方法始终优于现有的替代方案,凸显了其在创意内容生成、虚拟试穿和场景合成等实际应用中的巨大潜力。
AnyInsertion 数据集
 图像对收集自互联网来源、人体视频和多视角图像。数据集分为口罩提示和文本提示两类,每种提示类型又细分为配饰、物体和人物。数据集类别涵盖多种插入场景:家具、日用品、服装、车辆和人体。
图像对收集自互联网来源、人体视频和多视角图像。数据集分为口罩提示和文本提示两类,每种提示类型又细分为配饰、物体和人物。数据集类别涵盖多种插入场景:家具、日用品、服装、车辆和人体。
方法概述
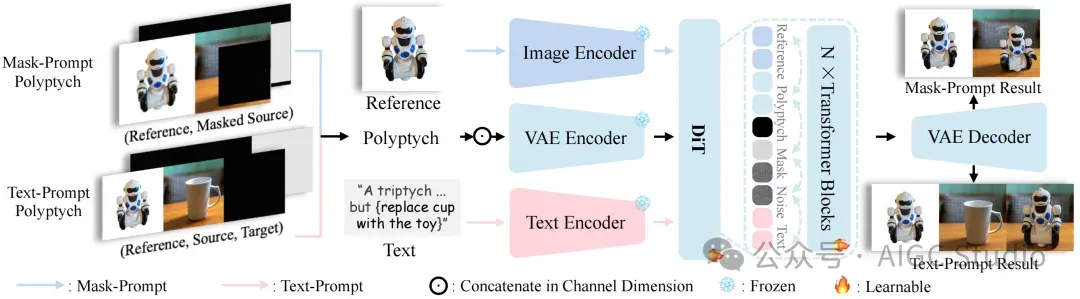 面对不同类型的提示,提出的统一框架会通过冻结的 VAE 编码器处理多联画输入(参考图像、源图像和蒙版的串联),以保留高频细节,并从图像和文本编码器中提取语义引导。这些嵌入会被组合并输入到可学习的 DiT Transformer 模块中进行上下文学习,从而实现由蒙版或文本提示引导的精准灵活的图像插入。
面对不同类型的提示,提出的统一框架会通过冻结的 VAE 编码器处理多联画输入(参考图像、源图像和蒙版的串联),以保留高频细节,并从图像和文本编码器中提取语义引导。这些嵌入会被组合并输入到可学习的 DiT Transformer 模块中进行上下文学习,从而实现由蒙版或文本提示引导的精准灵活的图像插入。
实验结果

定性比较。与现有方法(AnyDoor、MimicBrush、Ace++、OOTD、CatVTON)相比,该方法在各种插入任务(人物、物体和服装)中始终如一地保留了身份信息并保持了视觉连贯性。
结论
Insert Anything是一个基于参考的图像插入统一框架,它通过支持蒙版和文本引导控制,克服了专用方法的局限性,适用于各种插入任务。利用新开发的包含 12 万个提示图像对的 AnyInsertion 数据集以及 DiT 架构的功能实现了创新的上下文编辑机制,该机制采用双联画和三联画提示策略,能够有效地保留身份特征,同时保持插入元素与目标场景之间的视觉和谐。在三个基准测试上进行的大量实验表明,提出的方法在人物、物体和服装插入方面始终优于最先进的方法,为基于参考的图像编辑树立了新标杆,并为现实世界的创意应用提供了通用的解决方案。


