这才是 AI 视频生成的未来?
随着 OpenAI 今年 2 月发布 Sora,世界模型(World Model)再次成为了 AI 领域的热门。
世界模型,即通过预测未来的范式对数字世界和物理世界进行理解,一直以来被认为是通往通用人工智能(AGI)的关键路径之一,与当前大模型推崇的智能体(Agent)方向互相区分。
世界模型的研究促进了交互式内容的创建,并为有根据的、长期的推理提供了基础。当前的基础模型并不能完全满足通用世界模型的功能——大型语言模型(LLM)受到对语言模态的依赖以及对物理世界有限理解的限制,而视频模型(如 Sora)则缺乏对世界模拟的交互式动作控制。
在 UC San Diego、穆罕默德・本・扎耶德人工智能大学(MBZUAI)等机构的最新研究中,人们通过引入 Pandora 向构建通用世界模型迈出了一步。
 MBZUAI 校长邢波(Eric Xing)表示,Pandora 是一个可通过语言命令实时操控的世界模型,能够在视觉空间中实时推理概念层面。是时候超越语言世界中的 LLM,进入物理和感官世界了!
MBZUAI 校长邢波(Eric Xing)表示,Pandora 是一个可通过语言命令实时操控的世界模型,能够在视觉空间中实时推理概念层面。是时候超越语言世界中的 LLM,进入物理和感官世界了!
Pandora 是一种混合自回归扩散模型,可通过生成视频来模拟世界状态,并允许通过自由文本动作(free-text action)进行实时控制。Pandora 通过大规模预训练和指令调整实现了领域通用性、视频一致性和可控性。 更加重要的是,Pandora 通过集成预训练的 LLM(7B)和预训练的视频模型,绕过了从头开始训练的成本,只需要额外的轻量级微调。作者展示了 Pandora 在不同领域(室内 / 室外、自然 / 城市、人类 / 机器人、2D/3D 等)的广泛输出能力。结果表明,通过更大规模的训练,我们能够构建更强大的通用世界模型。
更加重要的是,Pandora 通过集成预训练的 LLM(7B)和预训练的视频模型,绕过了从头开始训练的成本,只需要额外的轻量级微调。作者展示了 Pandora 在不同领域(室内 / 室外、自然 / 城市、人类 / 机器人、2D/3D 等)的广泛输出能力。结果表明,通过更大规模的训练,我们能够构建更强大的通用世界模型。

论文:Pandora : Towards General World Model with Natural Language Actions and Video States
论文地址:https://world-model.maitrix.org/assets/pandora.pdf
项目地址:https://github.com/maitrix-org/Pandora
项目展示页面:https://world-model.maitrix.org/
该研究展示了一系列先前模型不具有的特性:
能模拟广泛领域的视频状态:Pandora 能够生成广泛领域的视频,例如室内 / 室外、自然 / 城市、人类 / 机器人、2D/3D 和其他场景。这种领域的通用性主要归功于大规模视频预训练(继承自预训练视频模型)。
该模型允许通过自由文本动作进行动态控制:Pandora 接受自然语言动作描述作为视频生成期间的输入,以指导未来的世界状态。这与以前的文本到视频模型有很大不同,以前的文本到视频模型仅允许在视频开头出现文本提示。动态控制实现了世界模型的承诺,支持交互式内容生成并增强稳健的推理和规划。该功能是通过模型的自回归架构(允许随时输入文本)、预训练的 LLM 主干(可以理解任何文本表达式)和指令调整(可以大大增强控制的有效性)来实现的。
动作可控性跨域迁移:如前所述,使用高质量数据进行指令调整使模型能够学习有效的动作控制,并迁移到不同的新领域。新模型从特定领域学到的动作可以无缝地应用于不同新领域。
自回归模型主干支持更长的视频:基于扩散架构的现有视频生成模型通常会生成固定长度(例如 2 秒)的视频。通过将预训练视频模型与 LLM 自回归主干集成,Pandora 能够以自回归方式无限延长视频持续时间。结合额外的训练(例如指令调整),作者证明 Pandora 可以生成更高质量的更长视频(可长达 8 秒)。
方法
模型架构
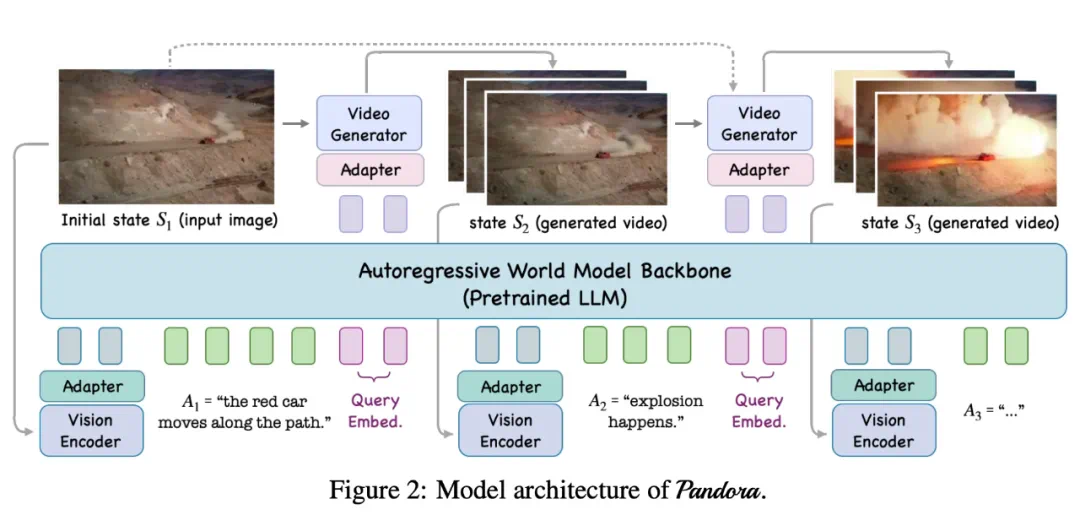
Pandora 是一个自回归世界模型。给定世界先前的状态(例如图像或视频剪辑)和自然语言动作描述,它可以预测世界的下一个状态(以视频剪辑的形式)。
如下图 2 所示,Pandora 的两个核心组件包括自回归主干网络(源自预训练 LLM)和视频生成器(使用预训练视频模型进行初始化)。为了将这两个组件拼接在一起,Pandora 还添加了其他必要的组件,包括视觉编码器,以及分别将视觉编码器连接到 LLM 主干和将 LLM 主干连接到视频生成器的两个适配器。
阶段性训练
通用世界模型需要实现一致性、可控性和通用性,即它需要生成一致的视频来准确描述世界状态,允许在视频生成过程中随时接受自然语言动作描述来进行动态控制,并跨越所有不同的领域执行上述操作(具有不同的场景和动作)。
直接训练世界模型需要大量高质量序列(视频 S1、文本 A1、视频 S2……)作为训练数据,而这在实践中很难获得。
因此,该研究设计了一个两阶段的训练策略,包括预训练和指令调整。
预训练阶段旨在让模型获得一些关键能力,包括:
视频生成器的一致、通用视频生成能力;
自回归主干网络的通用文本理解能力,以处理动作;
两个组件之间的表征空间对齐能力。
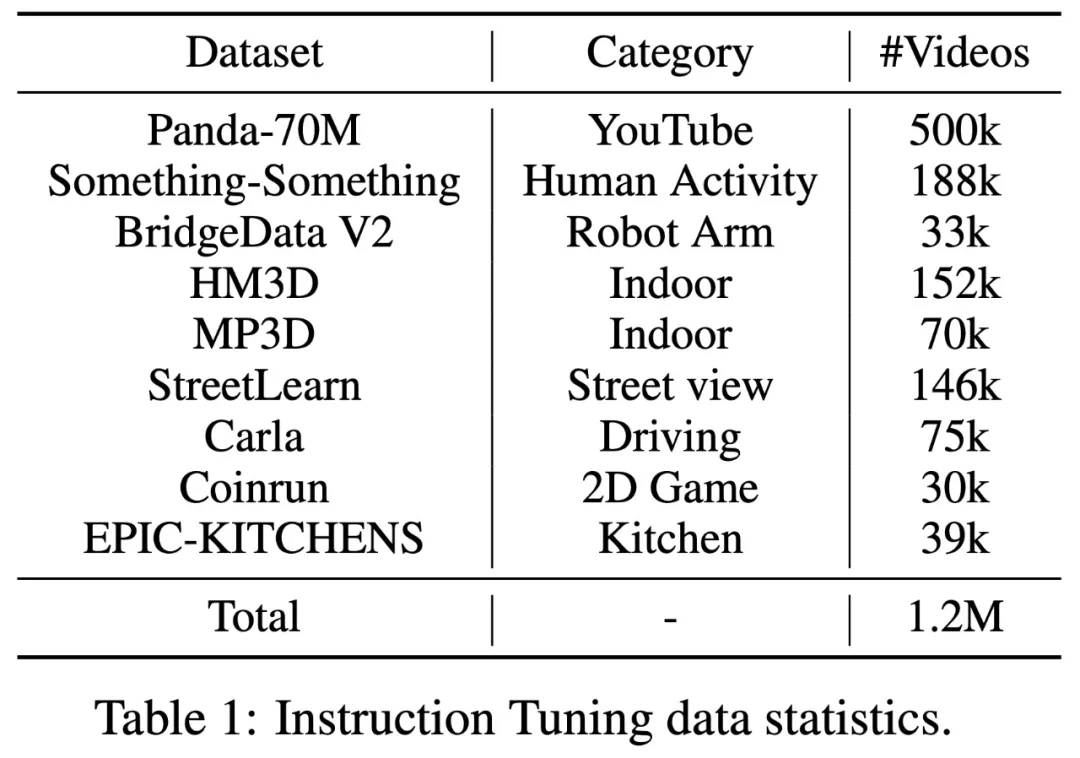
表 1 总结了该研究收集到的数据,主要来自公共语料库和数据处理模拟器。
定性结果
研究论文展示了一些定性结果,表明 Pandora 作为世界模拟器的核心功能,未来该研究将提供更多定量结果。
跨域的即时控制
Pandora 是一个通用世界模型,能够生成跨广泛领域的视频。它允许通过自由文本动作进行动态控制,即它可以在视频生成期间随时接受文本动作控制并相应地预测未来的世界状态。


Pandora 模型能够理解现实世界的物理概念,可以生成演示基本物理现象的视频:

动作可控性迁移
虽然一些动作及其相应的运动模式只出现在一些模拟数据中,但 Pandora 可以将动作可控性迁移到不同的未见领域。如下图所示图,Pandora 分别将 Coinrun 的 2D 游戏能力和 HM3D 的 3D 模拟器能力迁移到其他未见领域。

自回归生成更长的视频
借助自回归主干网络,Pandora 能够以自回归方式生成更高质量的更长视频。Pandora 接受最长 5 秒(40 帧)的视频训练,但它能够生成更长的视频。下图显示了生成 8 秒(64 帧)视频的结果。

尽管如此,作者表示 Pandora 很难生成高质量和良好可控的视频。在论文中,作者展示了一些语义理解、运动控制和视频一致性方面的失败案例。

在进行小规模探索实验时,作者发现数据质量,即动力学描述的精度对模型性能有很大影响。在存在高质量仿真数据的领域,模型很容易获得良好的可控性。但在公共视频数据集领域,GPT-4 Turbo 生成的字幕存在噪声,导致模型并没有表现出良好的性能。然而,当增加训练计算量时,模型上就会涌现出跨通用领域的可控性。
Pandora 的探索表明通过更大规模的训练,构建更强大的通用世界模型,这一研究方向具有巨大潜力。