近日,通义大模型发布CoGenAV,以音画同步理念创新语音识别技术,有效解决语音识别中噪声干扰的难题。
传统语音识别在噪声环境下表现欠佳,CoGenAV则另辟蹊径,通过学习audio-visual-text之间的时序对齐关系,构建出更鲁棒、更通用的语音表征框架,系统性提升语音识别任务(VSR/AVSR)、语音重建任务(AVSS/AVSE)以及语音同步任务(ASD)等多个Speech-Centric任务的表现力。

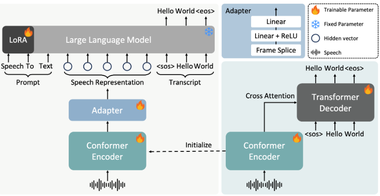
在技术实现上,CoGenAV采用“对比生成同步”策略。特征提取阶段,模型利用ResNet3D CNN分析视频中说话人的唇部动作,捕捉声音与口型之间的动态关联,同时用Transformer编码器提取音频中的语音信息,并将音视频特征精确对齐。对比生成同步训练通过对比同步和生成同步两种方式提升模型理解能力。对比同步采用Seq2Seq Contrastive Learning方法,增强音频与视频特征之间的对应关系,并引入ReLU激活函数过滤干扰帧;生成同步借助预训练ASR模型将音视频特征与其声学-文本表示对齐,并设计轻量级适配模块提升跨模态融合效率。
凭借这些创新技术,CoGenAV在多个基准数据集上取得突破性成果。在视觉语音识别(VSR)任务中,仅用223小时唇动视频训练,在LRS2数据集上就达到20.5%的词错误率(WER),效果媲美使用数千小时数据的传统模型。在音视频语音识别(AVSR)任务中,结合Whisper Medium模型,在相同数据集实现1.27% WER,刷新SOTA记录,在0dB噪声环境下性能提升超过80%,显著优于纯音频模型。在语音增强与分离(AVSE/AVSS)任务中,作为视觉特征提取器,在LRS2语音分离任务中SDRi指标达16.0dB,超越AvHuBERT1.6dB、Av SepFormer0.3dB;在语音增强任务中,SDRi指标为9.0dB,优于Av HuBERT1.6dB。在主动说话人检测(ASD)任务中,在Talkies数据集上平均精度(mAP)达到96.3%,领先现有方法。
CoGenAV可直接接入主流语音识别模型,如Whisper,无需修改或微调即可实现视觉语音识别功能,降低了部署门槛,展现出出色的抗噪能力和数据效率,大大节省了训练成本,增强了模型的实用性与扩展潜力。目前,CoGenAV的相关代码和模型已在GitHub、arivx、HuggingFace、ModelScope等平台开源,供研究者和开发者使用。
GitHub:https://github.com/HumanMLLM/CoGenAV
arivx:https://arxiv.org/pdf/2505.03186
HuggingFace:https://huggingface.co/detao/CoGenAV
ModelScope:https://modelscope.cn/models/iic/cogenav