当一位熟练的木匠抓起锤子时,锤子消失了 —— 不是物理上的消失,而是无需思考便可自如使用。然而,当前最先进的机器人仍然无法“放下”这把“锤子”,它们被困在循环中 —— 识别锤子、规划如何使用锤子,每一次交互都需要重新“拿起”工具作为认知对象,这种割裂式的处理方式让 AI 永远无法达到人类那种直觉的工具使用境界。
具身智能的突破,不会来自对现有基于视觉 - 语言基础模型的修补,而将源于一场架构革命。
自变量机器人主张,必须放弃以“多模态模块融合”为核心的拼凑式范式,转向一个端到端的统一架构。该架构旨在彻底消解视觉、语言和行动之间的人为边界,将它们还原为单一信息流进行处理。
当前范式的根本局限
现有主流方法将不同模态视为独立模块,如预训练的 ViT 处理视觉信息,LLM 处理语言理解,然后通过融合层进行连接。这种“委员会”式的设计存在着本质缺陷。
首先是表征瓶颈问题。信息在不同模态的专属编码器之间传递时,会产生不可避免的压缩损失,就像将一幅油画描述给盲人,再让盲人向聋人传达画面内容一样,每次转换都会丢失关键的细节和关联。这种损失阻碍了模型对物理世界进行深层次的跨模态理解。
最关键的是无法涌现的问题。结构上的割裂使得模型难以学习到物理世界中跨越模态的、直觉式的因果规律。就像一个人无法仅通过阅读教科书就学会骑自行车一样,真正的物理智能需要的是整体性的、具身的理解,而不是模块化的知识拼接。
统一架构:从分治到整合
自变量机器人提出的统一模态架构源于一个核心洞察:真正的具身智能不应该是多个专门模块的协作,而应该像人类认知一样,在统一的计算框架内同时处理感知、推理和行动。
架构的核心是统一表示学习。自变量机器人将所有模态信息 —— 视觉、语言、触觉、动作 —— 转换为共享的高维 token 序列,消除模态间的人为边界。
关键突破在于采用多任务多模态生成作为监督机制:系统必须学会从任一模态生成其他模态的内容,这迫使模型建立起深层的跨模态对应关系。
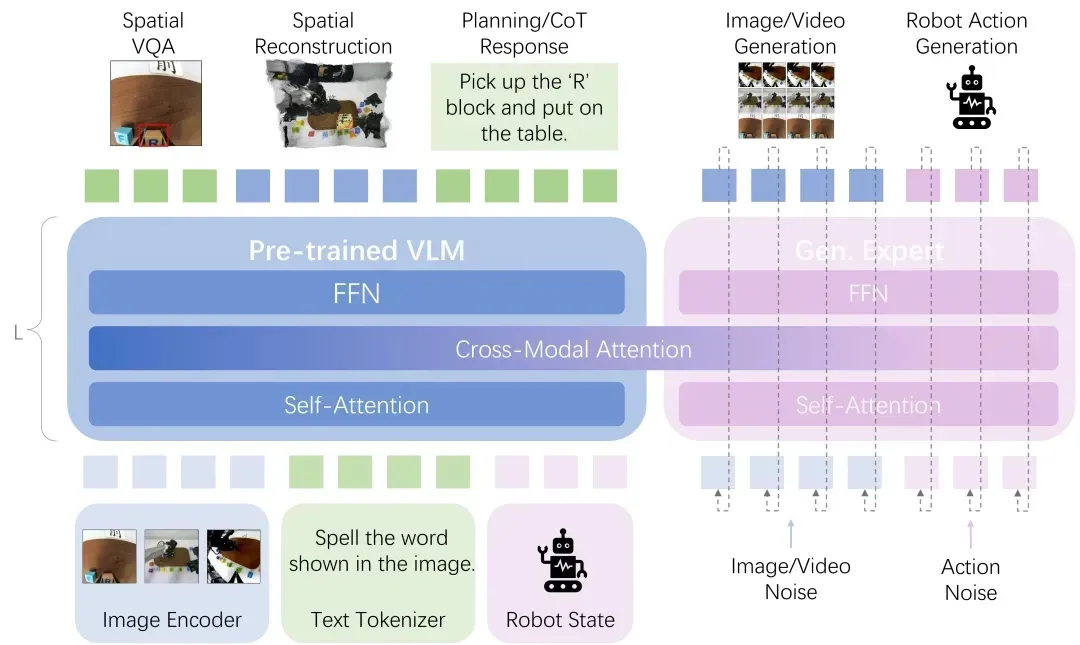
具体而言,将所有输入模态,包括多视角图像、文本指令与机器人实时状态,通过各自的编码器转化为统一的 token 序列,该序列被送入一个 Transformer 核心。其中,预训练多模态理解模型负责整合信息以完成空间感知理解与任务推理规划,而生成专家 (Gen. Expert) 则预测未来的图像与视频,以及直接生成可执行的机器人动作。两者通过一个跨模态注意力 (Cross-Modal Attention) 层深度耦合,使得感知、推理和行为的信息流在每一个计算层都能无损地双向交互与共同演进,从而实现了端到端的统一学习。
这种架构实现了具身多模态推理的涌现。当面对新任务时,系统能够像人类一样进行整体性认知处理 —— 视觉理解、语义推理、物理预测和动作规划在统一空间内并行发生、相互影响,而非串行处理。
通过这种端到端的统一学习,系统最终能够像人类一样思考和工作:不再依赖模块化的信息传递,而是在深层表示空间中直接进行跨模态的因果推理和行动决策。
涌现能力:具身多模态推理
这种统一架构旨在解锁当前模块化系统无法实现的全方位具身多模态推理能力。
第一个是符号-空间推理能力。
当人类随意画出几何形状时,机器人首先通过理解复杂几何图案,然后在统一的表示空间中进行多层次推理:将抽象的二维图形解构为具体的字母组合,理解这些字母的空间排列逻辑,并推断出它们组合成的完整单词。同时,机器人能够将这种抽象的符号理解直接转化为三维空间中的物理操作,用积木块精确地重现字母的空间排布。
整个过程体现了视觉感知、因果推理和空间操作的深度融合。

视频演示 1:机器人根据手绘图形拼出对应单词
第二个是物理空间推理能力。
当向机器人展示积木的操作步骤时,机器人能够在其统一的潜在空间中直接进行视觉的空间逻辑推理和因果关系推演。这个过程中,机器人理解每个积木的放置如何影响整体结构的稳定性,推断操作顺序背后的工程逻辑,并预测不同操作路径可能导致的结果。同时,机器人能够将这种物理推理过程外化为语言思考链,清晰地表达其对空间关系、重力约束和构建策略的理解。
最终,机器人能够基于这种深层的物理理解,独立完成复杂的三维结构搭建,展现了物理直觉与推理能力的有机结合。

视频演示 2:观察积木操作步骤并搭建对应空间形状
第三个突破是具备推理链的自主探索能力。
面对复杂的环境,系统能够整合视觉观察、空间记忆和常识知识,构建出连贯的推理链条。整个过程体现了感知、记忆、推理和行动的无缝整合,以及基于常识知识的灵活决策能力。
这种推理过程是端到端学习的自然涌现。
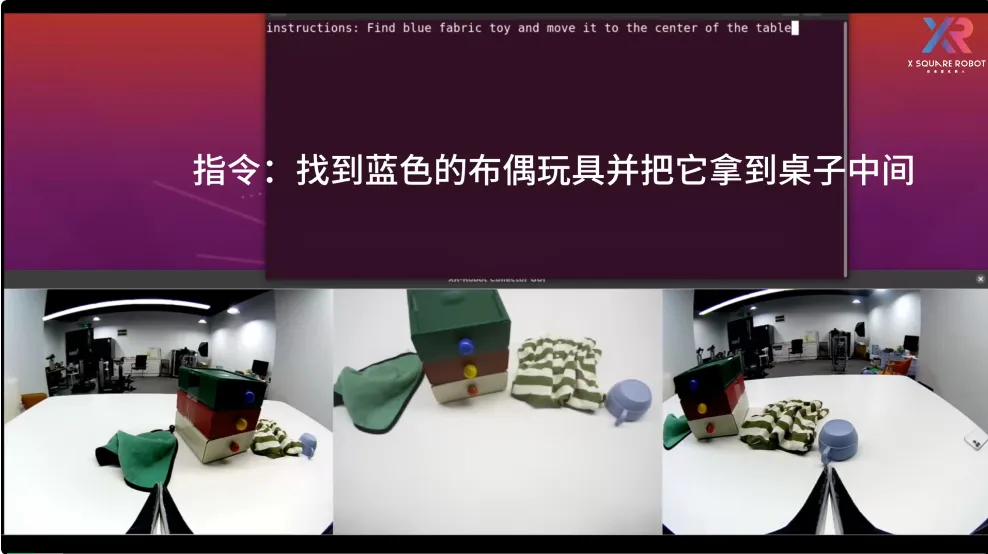
视频演示 3:带有推理过程的物品搜索
以上三个视频, 机器人需要在操作中实时输出推理过程,这要求模型在统一架构中实现物理操作、视觉和语言推理的精确同步。
最后一个展示了机器人从视频中学习能力和协作推理能力。
当观察人类的操作视频时,机器人从视频中推断行为背后的深层意图和目标状态。这种能力超越了简单的动作模仿,体现了视频学习、对人类意图的理解、对协作目标的推断,以及自主的协作决策能力,展现了真正的自主学习和人机协同能力。

视频演示 4:从视频中推断动作意图并自主执行
结语
这些演示背后体现的是一个根本性的范式转换。
传统的多模态系统将世界分解为独立的表征模块,但物理世界的交互是连续的、实时的、多模态耦合的 —— 当机器人抓取一个易碎物品时,视觉判断、力度控制和安全预测必须同时发生,任何模块间的延迟或信息损失都可能导致失败。自变量机器人的统一架构正是为满足这种具身交互的要求生的。
这种转变的意义在于,它让机器人能够像海德格尔描述的熟练工匠一样,将感知、理解和行动无缝融合。
机器人不再需要经历 “视觉识别→语言规划→动作执行” 的冗长串行处理,而是在统一的表征空间中被直接理解为实现特定意图的媒介 —— 机器人能够同时 “看到” 物理属性、“理解” 其在任务中的作用、“感知” 操作的空间约束,并 “规划” 相应的动作序列。
正是这种多模态信息的并行融合处理,使得具身多模态推理能力得以自然涌现,让机器人最终能够像人类一样流畅地与物理世界交互。
自变量机器人主张,具身智能的未来路径是从设计“割裂式表征”的系统,转向构建能够进行真正具身多模态推理的统一系统。这并非一次增量改进,而是让 AI 具备跨模态因果推理、空间逻辑推演和实现通用操作的具身智能所必需的架构进化。


