「Tokenization(分词)是 Transformer 模型为弥补自身缺陷不得不戴上的枷锁。」
近日,Mamba 作者、CMU 助理教授、Cartesia AI 首席科学家 Albert Gu 撰写了一篇新博客,探讨了状态空间模型(SSM)和 Transformer 之间的权衡,并提出了这样一种观点。

这篇博客改编自 Albert Gu 过去一年来多次进行的一场演讲。虽然演讲内容通俗易懂,面向比较广泛的受众群体,但其中的一些有趣的见解、观点和原理阐释,相信对专业研究者也不乏启发价值。
在社交媒体 X 上,Albert Gu 抛出了「tokens are bullshit」的观点,并预告了接下来要发布的重大架构进展。


图源:https://x.com/_albertgu/status/1942615020111876248
评论区的很多网友赞成 Albert Gu 的观点,认为移除 tokenization 会在计算效率方面带来积极影响。
状态空间模型
本文首先定义了什么是状态空间模型(State Space Model,SSM)。
下面的公式定义了(结构化)状态空间模型,它源自一系列工作,最终催生了 Mamba。状态空间模型可被视为现代版本的循环神经网络(RNN),具有一些关键的特性。尽管实现这类模型需要大量技术工作,但本文首先提炼出了使这类模型成功匹配 Transformer 语言建模性能的核心要素。

三大要素
1. 状态大小
SSM 的一大特性是其隐藏状态 h_t 的维度大于输入和输出「x_t, y_t.」。关键思路在于:在自回归建模中,任何循环网络的隐藏状态是其获取模型上下文的唯一途径。所以,对于语言等信息密集模态的建模,模型需要足够大的状态空间来存储其后续想要调用的相关信息。
在 SSM 中,如果每个输入 x_t 是一维标量,则隐藏状态 h_t 为 N 维向量,其中 N 是独立超参数,被称为状态空间、状态维度或者状态扩展因子。这类模型也被称为 SISO(单输入单输出)SSM,允许模型存储的信息是 LSTM 和 GRU 等传统 RNN 的 N 倍。
2. 状态表现力
模型不仅需要拥有足够大的状态空间以在理论上存储相关上下文信息,更需要具备表现力强大的状态更新函数,以精确编码和调用其需要的信息。
早期版本的「线性时不变」SSM 使用简单的递归公式「h_t=Ah_t−1+Bx_t」,其更新规则在每一个时间步保持恒定。虽然这一机制对音频等压缩数据的适用性很好,却难以应对语言这类信息速率多变的序列 —— 模型必须选择性记忆关键信息。以 Mamba 为代表的选择性 SSM 通过动态转移矩阵解决了此问题:其转移矩阵随时间变化且依赖数据本身,使得递归过程更具有表现力。值得注意的是,这些机制与经典 RNN 的门控结构紧密相关。
这正是现代循环模型最活跃的研究领域,聚焦理解转移矩阵 A_t 不同参数化的理论表现力,以及这些参数化如何影响模型在状态空间中的记忆能力。
3. 训练效率
扩展循环状态的容量和表现力很重要,但随之而来的是模型面临的关键计算效率瓶颈。Mamba 通过精心设计递归参数化方式,并采用经典的并行扫描算法攻克了这一难题。
当前涌现的诸多算法创新都具有以下共性特征:
并行化能力:致力于实现并行化,并在 GPU、TPU 等加速器上达到实用级效率 —— 通常利用矩阵乘法(matmuls)作为主力运算;
内存管理机制:必须精细控制内存使用,尤其是采用状态扩展的模型,实际上在主内存中无法实体化整个状态!Mamba 凭借对 GPU 存储层级的深度认知实现硬性解决,而大多数替代方案通过重构整个计算路径,在并行训练过程中规避显式状态计算;
线性特征:模型通常需要保持关于「x_t」的线性特征,因而一些人称此类模型为线性循环模型。线性特征对计算效率以及建模或优化能力均产生重要影响(具体分析详见下文)。
Mamba—— 系统性整合
需特别指出,以下三大技术要素均非首创:
要素 1:线性注意力和早期 SSM 已经采用类似的状态扩展公式;
要素 2:选择性机制的设计灵感来自于 LSTM 和 GRU 等经典 RNN 的门控结构,两者紧密相关;
要素 3:并行扫描算法在 S5 和 LRU 等早期 SSM 或线性 RNN 中已使用,线性注意力变体也采用了基于矩阵乘法的并行训练算法。
Mamba 的核心突破在于证明了:当将所有这些技术要素整合在一起时,模型在语言建模任务中可以实现跨越式性能突破,并达到比肩 Transformer 的效果。
现代循环模型
此后,现代循环模型研究呈现爆发式增长,各类新模型密集涌现。这些研究虽然动机不同,术语繁杂,却共享类似的技术内核:
RWKV、xLSTM 和 Griffin 等模型延续了 RNN 范式,将状态扩展称为矩阵化状态(要素 1),将选择性机制称为门控;
线性注意力率先融合了要素 1 和要素 3(并行算法),后续变体如 GLA、Gated DeltaNet 等引入数据依赖型递归选择性机制,并使用基于注意力的术语(如使用 (K,Q,V) 而不是 (B,C,X))。Mamba-2 可以同时视为 SSM 或线形注意力;
近期的很多模型提出了测试时训练 / 回归框架,将递归更新视为上下文记忆的在线优化过程。在这些框架中,状态被视为联想记忆,并行化通过小批量梯度下降实现。
核心共性在于:几乎所有模型可纳入相同的 SSM 公式 (1),主要差异在于转移矩阵 A_t 的结构设计(要素 2)以及对应的高校训练算法(要素 3)。本文采用状态空间模型(或现代循环模型)来统称这一大类新兴模型 —— 它们精确捕捉了 SISO 线性递归和状态扩展等核心共性特征。当然,考虑到技术同源性,其他命名体系同样合理!

尽管该领域的研究加速推进,并且新模型持续涌现,但本文认为当前模型仍然呈现高度同质化的特征,实证性能也基本相当。尤其是相较于二次注意力机制,这些模型之间的相似度远高于它们于 Transformer 的差异。
接下来将重点剖析 SSM 和 Transformer 之间的高阶权衡关系。
状态、大脑和数据库
本文认为:可以通过观察不同模型在自回归状态中存储了什么,以及它们是如何操作这些状态的,来更好地理解它们之间的权衡。这是什么意思呢?
从某种意义上说,每一个自回归模型 —— 比如像现代大语言模型那样按从左到右顺序生成数据的模型 —— 都是一种「状态空间模型」,它在内存中保存某种状态,并在每一个时间步中对其进行更新(比如 LLM 生成每一个词之间的过程)。
序列模型的自回归状态
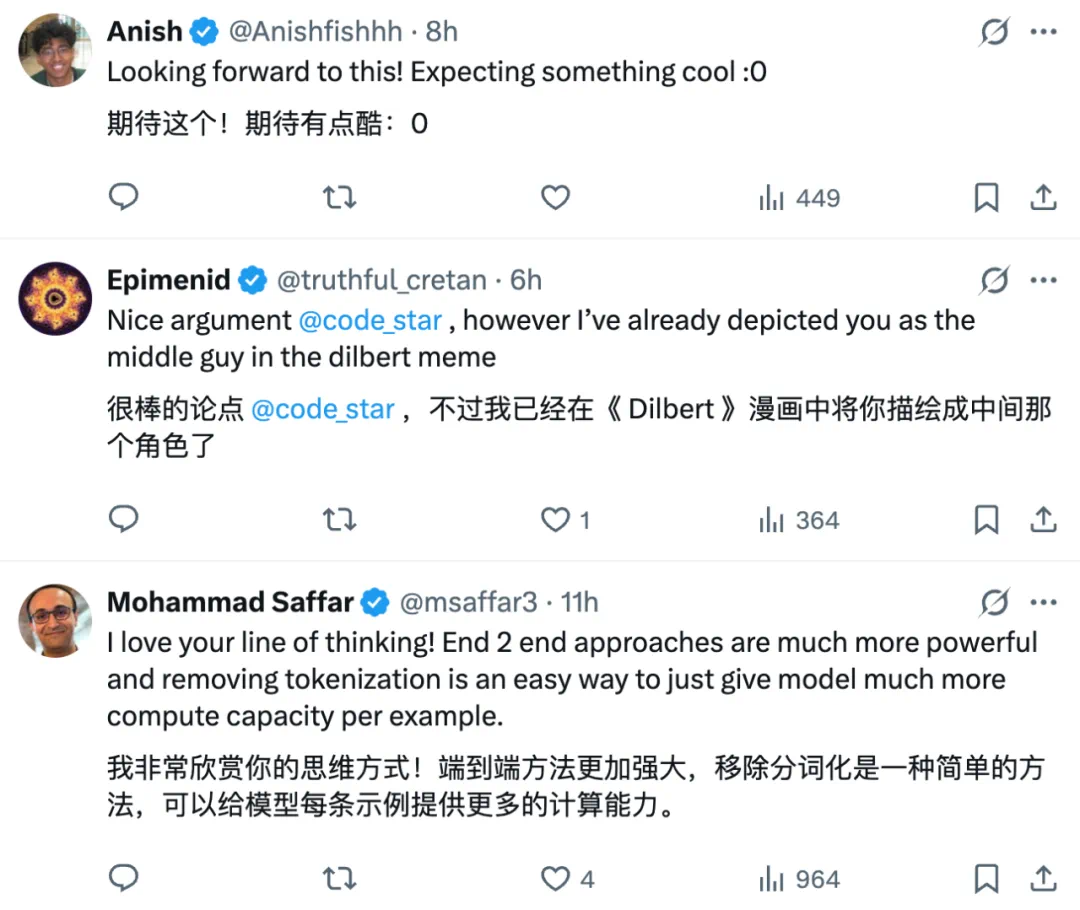
自回归 Transformer 的核心组件是(因果)自注意力机制,往往通过一种特定的操作来定义:计算序列中每一对元素之间的相互作用。因此,其计算成本随着序列长度呈二次增长,这也常被视为注意力机制的主要劣势。
相比之下,由于递归公式(1)中每一步的计算耗时是常数,整个序列的处理时间与序列长度成线性关系,这通常被认为是状态空间模型的主要优势。
但是,与其去思考这些模型在训练阶段的计算成本,本文认为更有启发性的是去关注它们在推理阶段处理新输入时会发生什么。
当一个自注意力层接收到一个新 token 时,它需要将这个 token 与序列中此前出现的所有元素进行比较。这意味着,它必须缓存整个上下文中每一个先前 token 的表示。每接收一个新输入,它都必须将其加入缓存,因此缓存的大小会随着上下文长度线性增长。
相比之下,状态空间模型始终将上下文「x_1,⋯ ,x_t」总结为一个隐藏状态 h_t(见公式 (1)),这个隐藏状态的大小是固定的。这个固定大小的状态就是模型与数据交互的唯一方式:它持续接收数据流,将其压缩进状态中,并依赖这一状态来做出决策或生成新输出。
这里甚至不需要深入探讨这些不同模型的具体定义。可以粗略地说,这些模型完全可以从「自回归状态」的第一性原理出发来定义:
Transformer(自注意力机制)的特点是其状态会缓存历史中的每一个元素,并通过遍历整个缓存来与新输入的数据进行交互。
状态空间模型(SSM)的特点则是其状态会压缩整个历史信息,并以在线流式的方式与新输入数据进行交互。
粗略的类比
尽管状态空间模型(SSM)常被视为更高效但稍逊于 Transformer 的变体,事情其实并没有那么简单。
即使不考虑计算效率,这两类模型在归纳偏置(或建模能力)上也存在不同的权衡。考虑到两者处理数据的方式差异,本文做了一个粗略但贴切的类比来说明这一点。
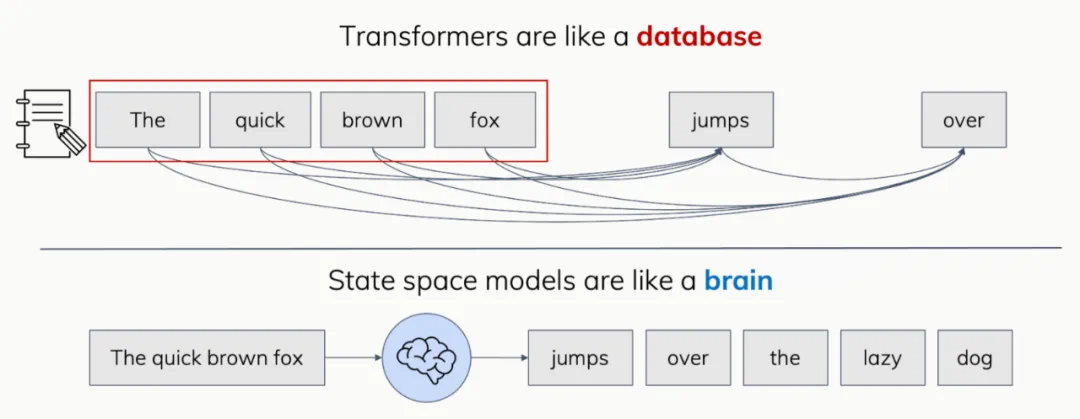
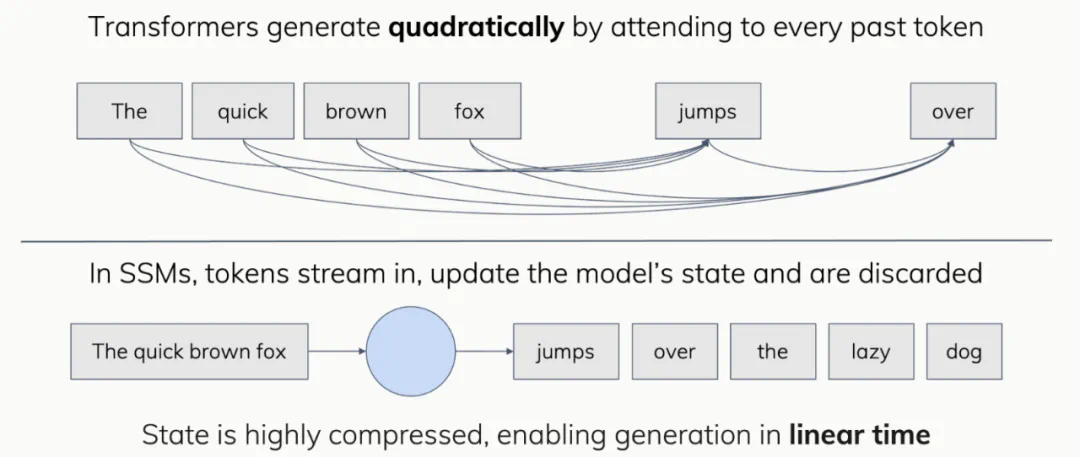
Transformer 更像是数据库:它们把每一个新的观测都当作重要的信息存档,以备将来查用。相比之下,状态空间模型(SSM)更像是大脑:拥有有限大小的记忆,一直处于工作状态,实时处理新输入并产生输出。
这个类比虽然有些浅显,但在直观上确实有助于解释一些经验上观察到的行为模式。例如,SSM 无法在只读一遍的情况下记住整个电话簿并完整背诵出来,或者从记忆中准确回忆任意一个人的电话号码。当然,人类也做不到这一点 —— 我们在精确记忆和检索方面表现得非常差 —— 但这似乎并不妨碍智能的产生!
另一方面,Transformer 在上下文长度上有一个根本的硬性限制(当缓存大小被超过时),而像 SSM 这样的递归模型在理论上可以像人类一样,保有一段无限长(但模糊)的过去记忆。

一个更有趣的经验发现 —— 也许可以从上述类比中预测到 —— 将这两种信息处理方式结合起来,可能会表现得更强大!就像人类的智能能够通过使用笔记本和外部参考资料得到增强一样,当语言模型通过一种简单的交替策略将 SSM 与注意力层结合使用时,其能力也得到了提升。
更令人感兴趣的是,经过多个研究团队的独立验证(包括 H3、Jamba、Zamba、Samba 以及随后涌现出的许多模型),最优的 SSM 与注意力层的比例大致在 3:1 到 10:1 之间。如果你认同这样一个粗略的类比(即人类智能主要依赖于大脑,并通过轻量访问外部数据库得到增强),那么这个比例似乎也在某种程度上印证了这一观点!
如今,这类混合模型已被大规模扩展到非常庞大的规模(例如采用 MoE 架构的总参数量达到 5600 亿),并由一些顶级实验室推出,如 NVIDIA 的 Nemotron-H 和腾讯的 T1/TurboS,都已在多个任务上取得了最先进的性能。
Is Attention All You Need?
所以,「Attention is all you need」,对吧?如今普遍存在一种看法:Transforme 是终极架构,能够从原始数据中学到任何东西,只要数据足够多、计算资源充足,唯一的瓶颈就是算力。

但事实并非如此简单。Attention 确实非常出色,已经成为几乎所有模态的核心骨干,从最初在语言上的应用拓展到了视觉、音频,甚至更多领域。不过,这其中还有更多细节值得探讨。

本文想提出的观点是:要真正有效地使用 Transformer,数据必须经过相当程度的预处理。为了支持这个观点,可以先来看看 Transformer 在实际中的使用方式。
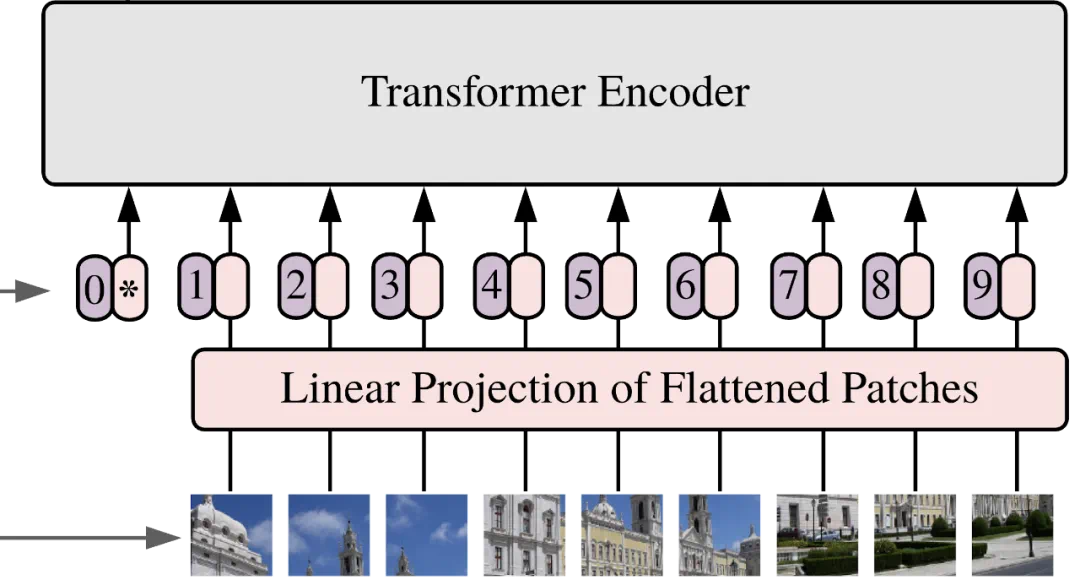
在几乎所有真实的应用流程中,原始数据在输入 Transformer 之前都会先通过某种编码器进行处理,例如:
在视觉任务中,无论是分类还是生成,都需要一个「切块」(patchification)步骤;
在语言建模中,需要先进行「分词」(tokenization)。
这听起来也许很直观:毕竟注意力机制的计算复杂度是二次的,我们会希望尽量简化输入数据(比如缩短序列长度)。
但本文想说的并不仅仅是计算效率的问题,而是一个更强的观点:Transformer 在建模能力上本身就存在一定的局限性。
我们应该摆脱 tokenization 吗?
Tokenization 是所有语言建模流程中一个重要步骤,最常见的是 BPE 算法,本文中 tokenization 与 BPE 可互换使用。
但这个过程带来很多问题,如询问大模型「strawberry 里有几个字母 r?」,它们经常回答错误,这些都暴露了分词机制在理解语言细节上的局限。

那我们为什么还要使用 tokenization 呢?
从大量观点来看,几乎所有人都同意:tokenizer 既笨拙又丑陋,但它又必然存在。
在实际应用中,tokenization 大约可以将序列长度缩短一个数量级左右,这显著提升了语言模型的运算效率。尽管存在一些极端案例,但大多数情况下,它们确实能用。
但本文恰恰相反,认为我们应该彻底摆脱 tokenization,这不仅仅是出于实际原因,也是为了美观和无形的考虑。
除了可以修复边缘案例(如 strawberry 这个单词里有几个字母 r),移除 tokenization 更符合深度学习的本质。
深度学习一直都致力于用强大的端到端神经网络取代手工设计的特征工程,这些神经网络可以自动从数据中学习模式。从 CNN 取代计算机视觉领域中人工设计的边缘检测器,到 Transformers 取代自然语言处理领域的语言特征,人工智能的重大进步总是伴随着更少的数据处理和更多的自动学习(正如《苦涩的教训》所倡导的那样)。
用端到端模型替代 tokenization 将带来深远的影响,具体体现在以下几个方面:
扩展律(scaling laws):从原始数据中学习更优的模式,总能带来更强大的模型能力;
多语言与多模态处理:对某些语言和其他类型的序列数据而言,tokenization 一直是一个出了名的难题,甚至根本无法适配;
推理能力:模型可以从数据中学习到更具语义的模式,并在更高抽象层面上进行推理。
假如没有 tokenization,会发生什么?
LLM 时代,几乎没有几篇论文真正认真思考或尝试解决「去除 tokenizer」这个问题。甚至很难找到一套可靠的基准,用来评估无 tokenizer 模型的表现。
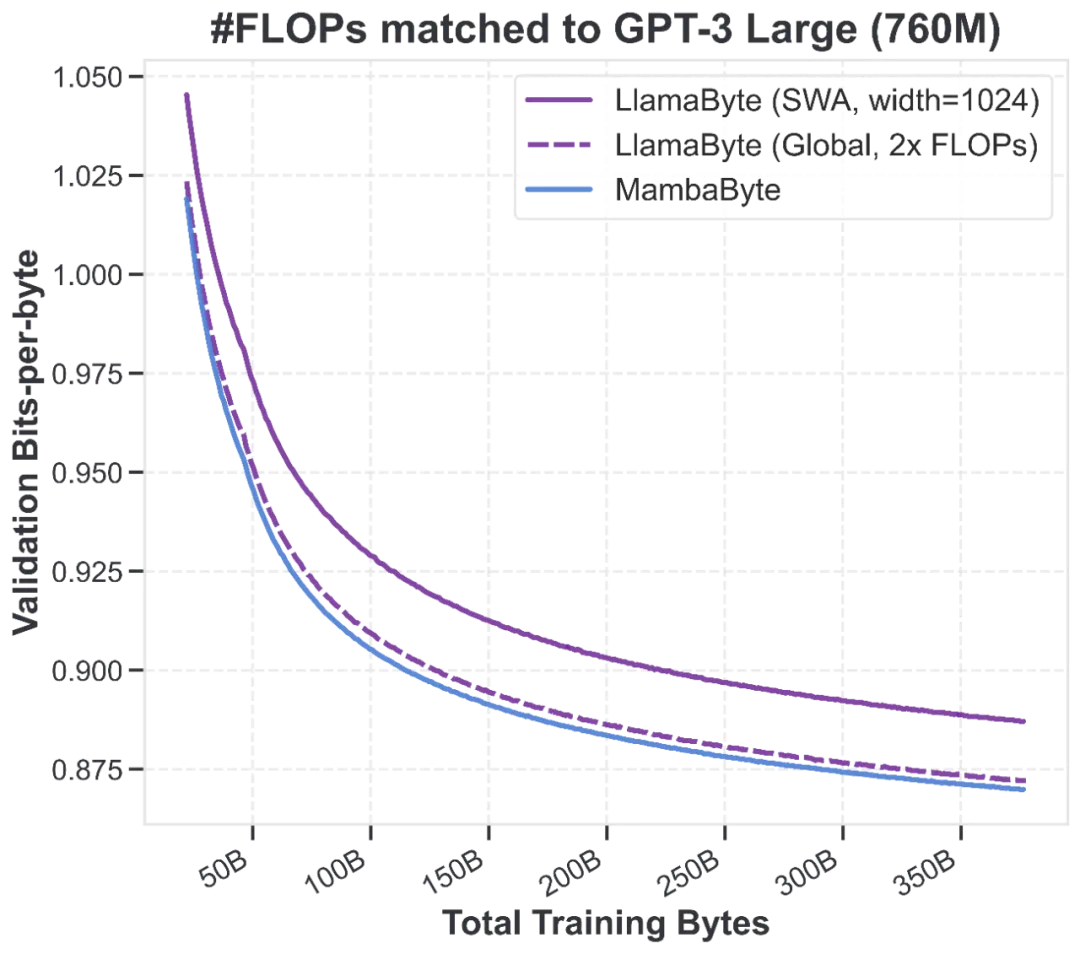
假如没有 tokenization,会发生什么?
由上图,我们可以得出一些让人颇感意外的结论。
但现在我们只做一件事:保持模型和数据不变,仅仅取消 tokenization(直接用字节输入),结果是 ——Transformer 用上了更多的计算资源,表现却明显落后于 SSM。
首先要指出的是:在 FLOPs 匹配的前提下,SSM 的表现远优于 Transformer。
这一点对一些人来说也许并不意外,因为在字节级建模中,输入序列远长于 BPE token 序列,而 Transformer 会因其对序列长度呈二次复杂度的计算瓶颈而受到影响。
然而,Transformer 的弱点并不仅仅在于效率问题,更在于其建模能力的局限。
值得注意的是,即使让 Transformer 使用远多于 SSM 的计算资源(以数据量匹配,而非计算量匹配),SSM 依然始终领先。
作为对比:如果用完全相同的数据对这两类模型进行对比,但对数据做了 tokenization,那么两者的困惑度(perplexity)曲线会基本相似(甚至 Transformer 会略优),并且它们的 FLOP 也会差不多。
但如果在保持模型和数据不变的前提下,只是将输入不进行 tokenize,Transformer 虽然使用了更多的计算量,其性能反而相对 SSM 有明显下降。
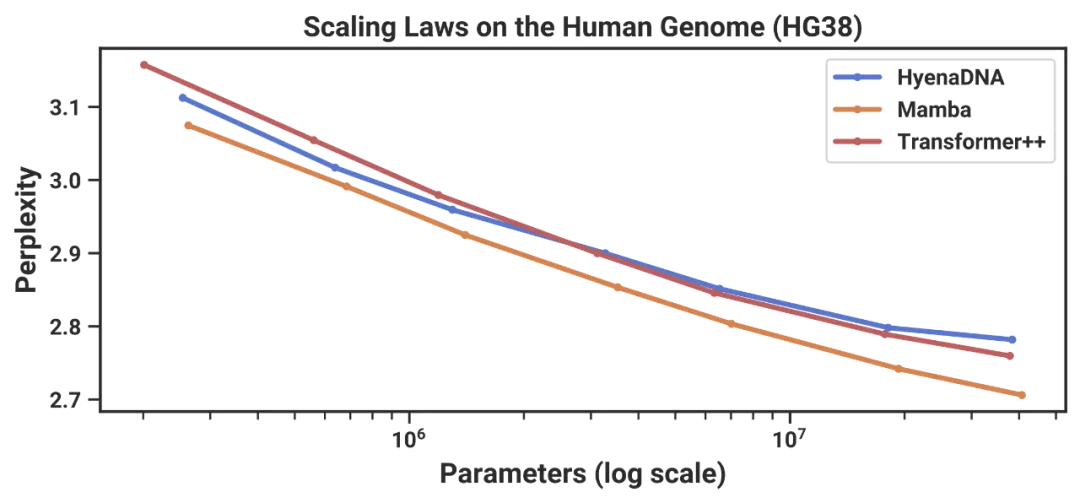
最初的 Mamba 论文显示,在 DNA 语言建模任务中,Mamba 在无需特别调优的情况下,其扩展能力明显优于 Transformer。
这或许给我们一点启示:tokenization 本质上是为 Transformer 缺陷设计的补丁,而 SSM 类模型在原生处理低语义密度数据时展现出更根本的建模优势,这可能重塑我们对语言模型本质能力的认知框架。
要理解这里发生了什么,一个有用的思维模型是回到自回归状态。简而言之,由于 Transformer 显式缓存了所有先前的 token,它就带有一种归纳偏置:倾向于关注每一个具体的 token。或者更简洁地说:软注意力的归纳偏置,其实是硬注意力。
在处理语言时,我们通常关注的是词(word)或子词(如词根、前缀 / 后缀)这样的单位,它们具有明确的语义含义。
但反过来看,如果这种假设不成立 —— 比如阅读时我们很少会关注某个单独的字符,那么注意力机制的表现就会下降。
更有趣的是,很多其他类型的数据处于这两者之间的模糊地带。
比如图像中的 patch 在某些情况下能捕捉到显著特征,有时是有意义的;但在其他时候,它们可能毫无用处,或者语义不完整。

一个假想
当序列中存在噪声时会发生什么?
众所周知,LLM 的训练数据通常需要大量的预处理、筛选和清洗,但现实世界中的数据(尤其是多模态数据)并非如此。人类也能在大量噪声中学习得很好!
那么,在一个非常简单的情形下,如果我们在序列中插入一些不包含任何信息的填充 token,会发生什么呢?
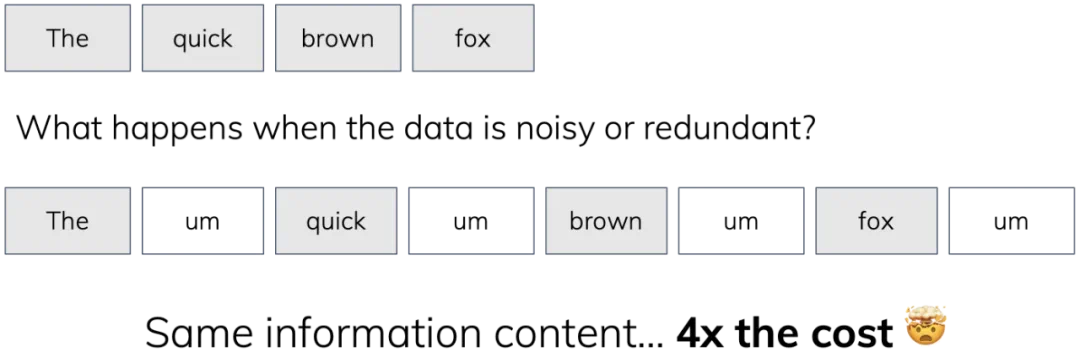
图中揭示了标准注意力机制的又一个失败模式:计算不应该按 k^2 扩展,推理时的内存消耗更不应该这样扩张,缓存这些毫无意义的噪声 token 是完全没有意义的。
相比之下,SSM 做得更好:即使冗余因子增加,模型的内存不会增加。
但这也并未完全解决问题,因为任何标准架构的计算量仍然会随着 token 的增加而增加。所以说,所有当前的大模型在面对噪声或冗余时都存在性能损耗的问题。
所以,理想的模型体系架构应该在不(实质上)增加计算或内存使用的情况下,能够处理这种带有填充序列的任务,而不是盲目地处理所有 token。
更一般地,假设我们有一个数据集的两个副本,其中一个包含很多额外的噪声,但总体而言,它们具有基本相同的有用信息。我们应该预期正确的架构在这两个数据集上的表现基本相同。
这就引出一个问题:Is attention all you need? 答案是注意力机制对处于正确抽象层级的预压缩数据最为有效。
当然,这种说法是对实际情况的过度简化,作者表示也不知道该如何正式定义抽象层级这种概念。但作者相信,在某种模糊的意义上,这确实是对的。
状态空间模型与 Transformer 之间的权衡
状态空间模型
先说优势,SSM 是一种天然具备状态记忆的模型,擅长高效、交互式、在线处理。缺点是缺乏精细的回忆(recall)和检索能力。
这两者好比同一枚硬币的两面,根源都在于状态压缩机制的本质特性。
那么压缩是否其实是智能的根本特征之一?是否有可能,正是因为将信息强行压缩进一个更小的状态空间,才迫使模型去学习更有用的模式和抽象?
虽然在很多文献中,压缩状态常被视为一种缺陷,但这种观点的产生可能是因为压缩带来的弱点很容易被量化衡量,而压缩所带来的那些更微妙的、定性的正面影响却很难被准确评估。

无论如何,现在肯定有很多有趣的应用,SSM 看起来是非常合适的工具。
Transformer
Transformer 的表现非常出色,事实上,在那些需要关注上下文中单个 token 的任务中,Transformer 几乎是唯一能够胜任的工具。
Transformer 的优势是拥有完美的召回率,并能在其上下文中对单个 token 进行细粒度的操作。
那么它的缺点呢?大家都知道 Transformer 的主要弱点是其二次方复杂度。
并非如此。这篇文章的主题是要阐明 Transformer 确实存在归纳偏差,这使其在建模能力方面存在弱点,而不仅仅是效率方面。与 SSM 一样,Transformer 的高层优势和劣势是同一枚硬币的两面,都是其自回归状态结构的结果:token 缓存会维持给定输入分辨率的粒度。
Transformer 弱点是受制于赋予它们的 token。
换句话说,它们对数据的分辨率和语义内容更加敏感。Transformer 的特点在于其上下文缓存,它为序列中的每个元素存储单独的表示,这意味着每个元素最好都有用。
最后,让我们来谈谈当前人工智能发展浪潮的主要驱动力之一:扩展律 Scaling Laws,或者说,在模型上投入更多计算资源会持续带来更多能力的现象。
这些定律总是以 FLOP(浮点运算次数)为 x 轴,以某种性能指标为 y 轴来绘制,其理念是,这条线的斜率衡量「计算能力转化为能力的速率」。事实上,本文认为有一种流行的观点认为 Transformer 只是一种以最佳方式执行这种转换的工具。
这很好地描述了架构研究的目标,本文只是在寻找一个能够以最佳方式执行这种转换的黑匣子。从这个角度来看,只有一个核心问题:
模型是否合理地利用了它的计算能力?
换句话说,本文希望每个 FLOP 都有效。希望读完这篇文章后,大家能够清楚地认识到 Transformer 远非最佳方案(至少作者已经说服了自己!)。
题外话:这真的重要吗?
尽管作者被誉为 Transformer 替代方案方向的领导者,但他同时也认为 Transformer 非常棒,注意力机制确实是建模的基本原语。但作者也认为,Transformer 本身显然不是最终的解决方案。我们还有很多工作要做。
博客链接:https://goombalab.github.io/blog/2025/tradeoffs/#a-coarse-analogy

