
两个月前在星球的会员群中,有人推荐了TextIn这款解析工具。我当时也是第一次听说,最近一段时间陆续在手头项目上测试了些以往认为是 Corner Case 的复杂布局文档后,发现居然都有不错的表现。后续了解到TextIn背后的公司叫合合信息,看起来还是有点陌生,不过这家公司旗下另外一款叫做“扫描全能王”的产品各位应该听说过或者用过。
本着 Garbage in, Garbage out 的理念,构建健壮企业级RAG应用涉及的众多复杂组件集成与优化中,解析组件的选择无疑是首当其冲的重点命题。我在之前的文章里已经介绍了几期关于原生开发和使用 Langchian、Llamaindex 框架开发 RAG 应用的示例。为了针对性的评测 TextIn 的实际解析效果,这篇就结合 RAGFlow 框架(v0.20.4版本)来做个整体演示。
这篇试图说清楚:
解析工具的开源和商业化产品分类、API 和本地部署的两种调用方式、在三类场景(纯文本、表格、图片)下TextIn与 Deepdoc 的效果对比、TextIn在 RAGFlow中二开的两种实现方式等。
1、解析工具分类
1.1是否开源
文档解析工具分为开源和闭源两大类,在开放性、可控性、成本和功能深度上存在明显差别。开源工具例如 PyMuPDF、MinerU、Marker 等,商业化产品例如这篇要介绍的TextIn。
开源产品
开源产品的优势首先肯定是免费,其次就是高透明度,可以根据需求进行二开。当然,活跃的开源社区可以贡献代码、修复漏洞、提供支持等。
但同时劣势也很明显,首先技术门槛高是绕不开的问题,对非技术团队或资源有限的组织挑战较大。同时,因为要依赖社区支持,响应速度和问题解决的专业性、保障性通常不如商业闭源产品的官方支持。最后也是最重要的,就是特定场景功能不足。针对特定行业场景(例如复杂的财务表格、医疗报告结构化)的预训练模型或精细化处理能力,可能不如成熟的商业闭源产品。
商业化产品
商业化产品的劣势在于使用成本与低透明度(无法直接修改核心代码)。优势也很明显,就是开箱即用,易于集成。通常都会提供完善的前端界面、SDK、清晰的文档和示例,集成相对简单快捷,使用技术门槛低。技术支持、问题响应上也都比较成熟。其次,在深度优化与特定功能上往往都会比开源工具表现更为出色。 毕竟这些厂商投入大量资源进行核心算法研发、模型训练(尤其在特定领域如法律合同、医学文献、复杂表格识别)和性能优化,总会在精度、特定场景覆盖和功能深度上具备技术优势。当然,还有个持续更新与维护的好处。
1.2调用方式
在使用方法这个维度,主要有 API 调用和本地化部署两类。
API 调用方法可以快速启动,零运维。通常按需付费,避免了前期高昂的硬件和软件许可投资。这点对于中小企业来说比较友好。但同时,对于中大型企业或者特定行业(金融,军工等)往往不符合企业的数据合规要求。
本地部署模式反之最直接的好处,是可以保障数据安全与合规性。 文档数据不用出本地,更容易满足严格的合规和监管要求。劣势就是相应的前期高投入,运维负担重。部署复杂和上线周期长等问题。
总体来说,具体选择往往取决于具体需求和资源情况。接下来的三个场景演示中,考虑便捷程度,演示环节选择直接在TextIn的官网和RAGFlow的知识库页面进行直接评测对比,在RAGFlow的二开环节选择直接集成Textin的 API 方式。
2、三类场景测评效果
为了尽可能的完整对比 Deepdoc 和 TextIn 在不同场景下的解析效果表现,这里用我历史做过的项目中的几个真实的 case 中纯文本、复杂表格、图文混排等三种类型的文档,进行一个具体的测试。
2.1合同中的条款
首先是常见的法律法规类的纯文本合同。这类文档的格式相对比较规范,一般不涉及图表,更多的是如何在分块上能够比较稳定的进行按照条款级进行切分。
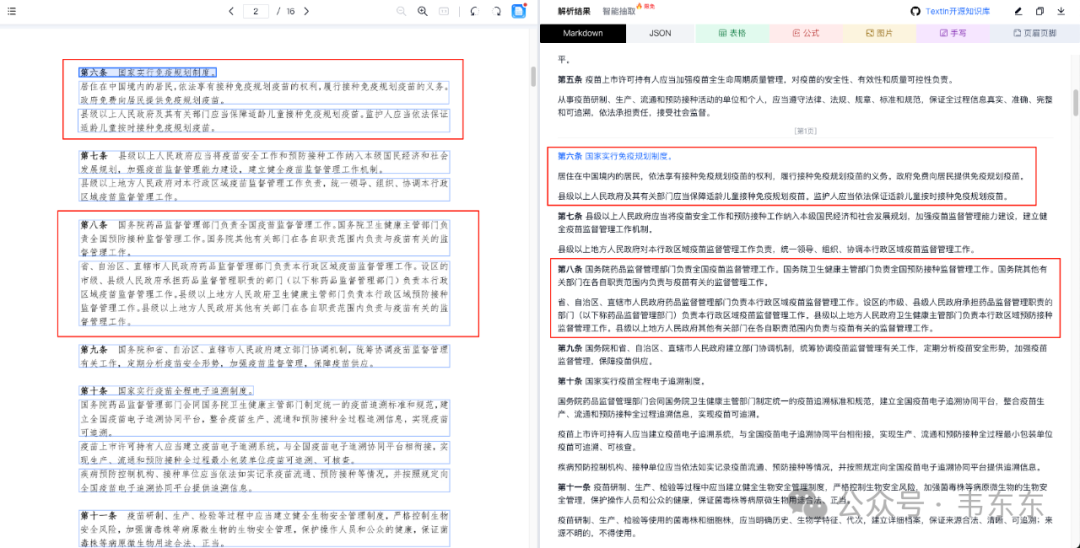
上图可以看到Textin 的条款识别是比较准确清晰的。同时,下图可以看到 RAGFlow在Deepdoc 模式下对于条款的识别同样没什么问题。而且得益于 RAGFlow 提供了多种面向特定文档类型的分块策略(这里选择是的 Law),所以针对这种典型的法规类文本可以精准的按照条款级进行分块。这样有利于保障每个分块的语义独立性和完整性。

从这个纯文本的角度来看,Deepdoc 和 Textin 应该说是平分秋色,或者说 Deepdoc 作为原生集成的解析组件,使用起来无疑更加方便些。
2.2财报中的表格
紧接着来测试下更为常见的一些复杂表格的识别。这里选择两种情形。一种是涉及到跨页的表格看下是否能够正常的完成拼接。其次重要看下对于合并单元格的情形,看下是否会有文字错位的情形。
跨页表格
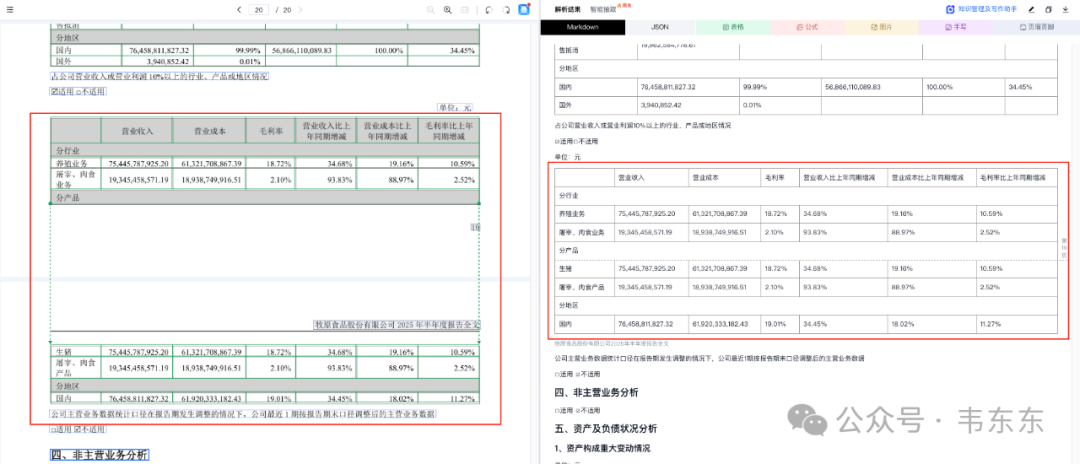
下面依次展示的是 Textin 和 Deepdoc 的解析结果,可以看到两个解析效果依然是不分伯仲,都很好的完成了跨页表格的重组。猜测二者都对这种情景做过单独的优化。
合并单元格识别
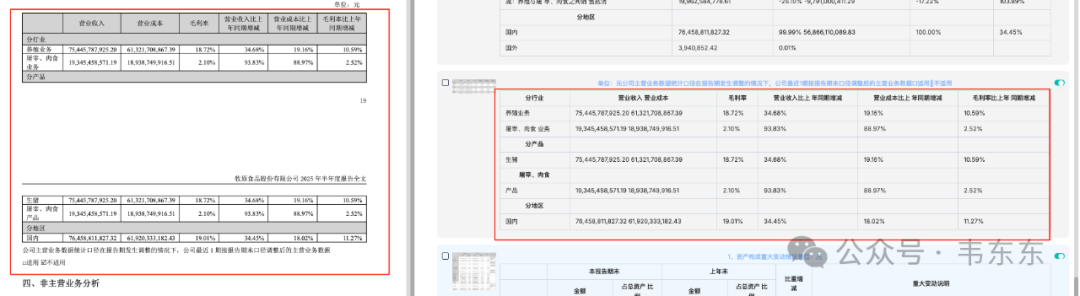
以下展示的是 Deepdoc 与 Textin 的识别效果对比。二者在表格的主体内容上都完成了很准确的解析。包括表头的合并单元的解析也都是准确的。但 Deepdoc 在这里犯了一个不小的错误是,把原本在“固定资产”和“应付账款”两行最后的一列备注(重大变动说明)内容进行了合并处理,而且还莫名的产生了合并单元格。而 Textin 则表现得依旧稳定。
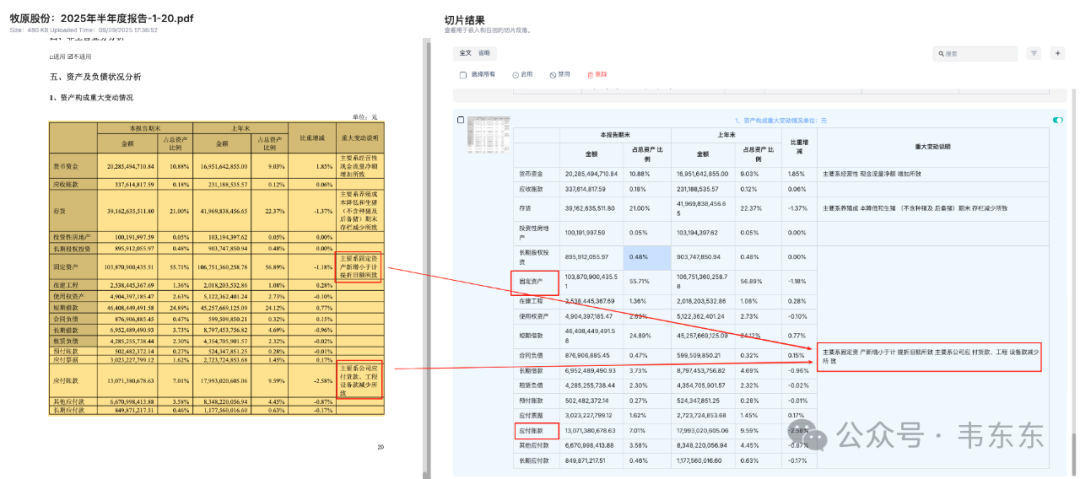
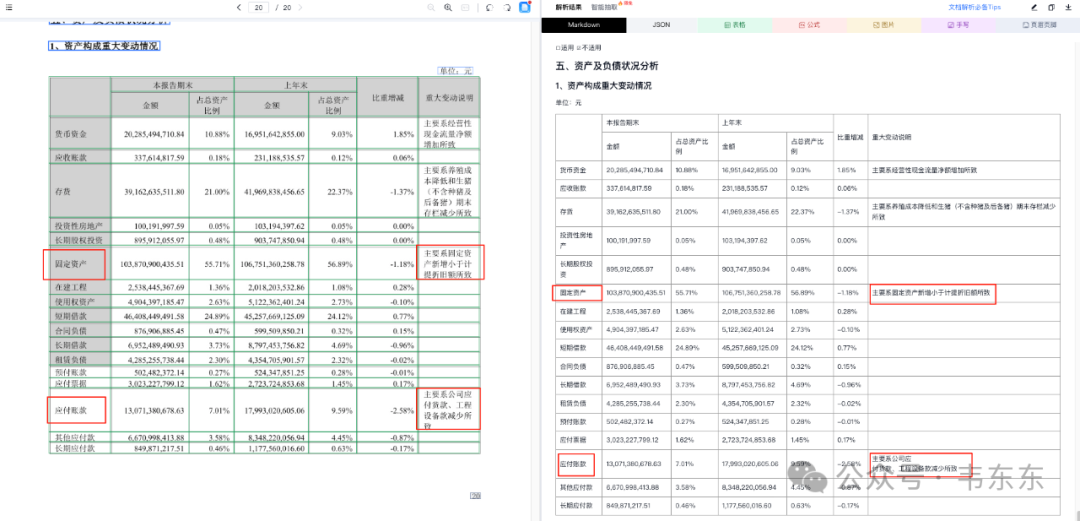
Deepdoc 的这个错误看起来似乎不大,但是当用户问及固定资产或者应付账款的一些变动原因的时候,即使能够召回这个分块作为上下文,但是由于对应的说明内容被混在了一起,大模型可能无法准确的还原出财报上原本的解释含义。
2.3图文混排关联
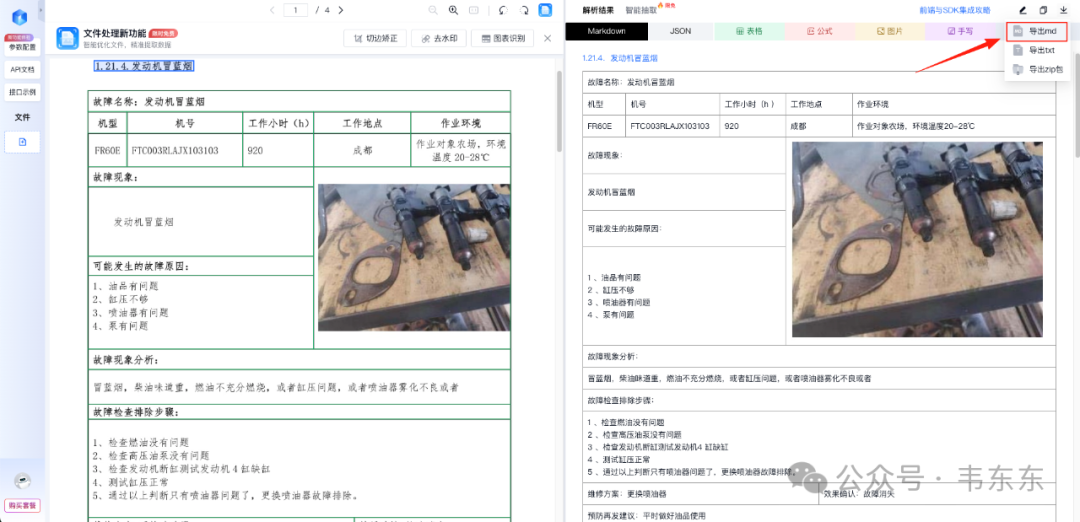
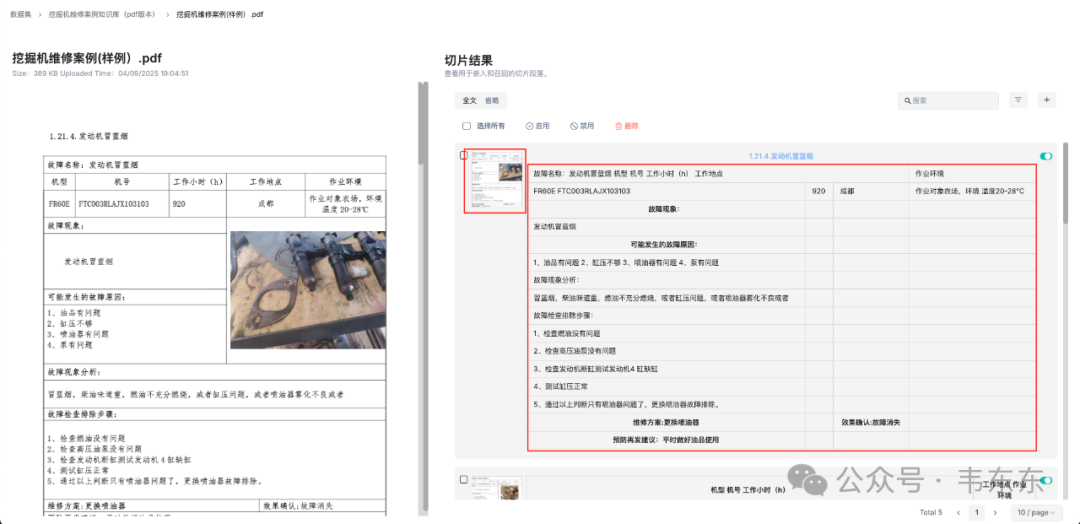
说完了文本和表格之后,肯定要来对比下图片部分的处理效果了。为了提高测试难度,这部分以历史文章中介绍过工程机械维保案例文档(表格内嵌图片)的一个页面来看下。下图依次是 Textin 和 Deepdoc 的回答,可以看出 Textin 比较完整的还原出了原始表格的布局。而 Deepdoc 则在图示中丢失了原始的图片,取而代之的是 v0.19 版本之后更新的原生快照。但这张快照是整个 PDF 页面的完整截图,而非案例中的具体故障部件图片。
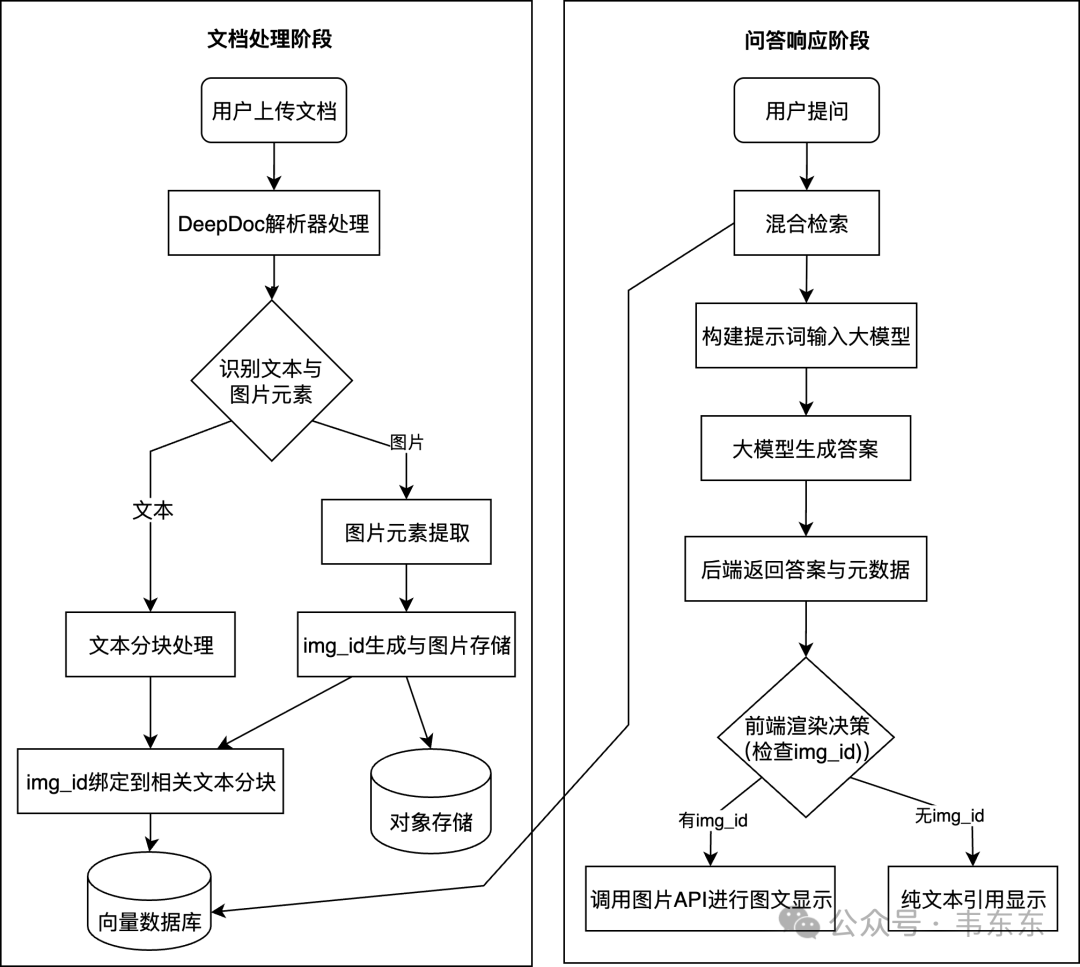
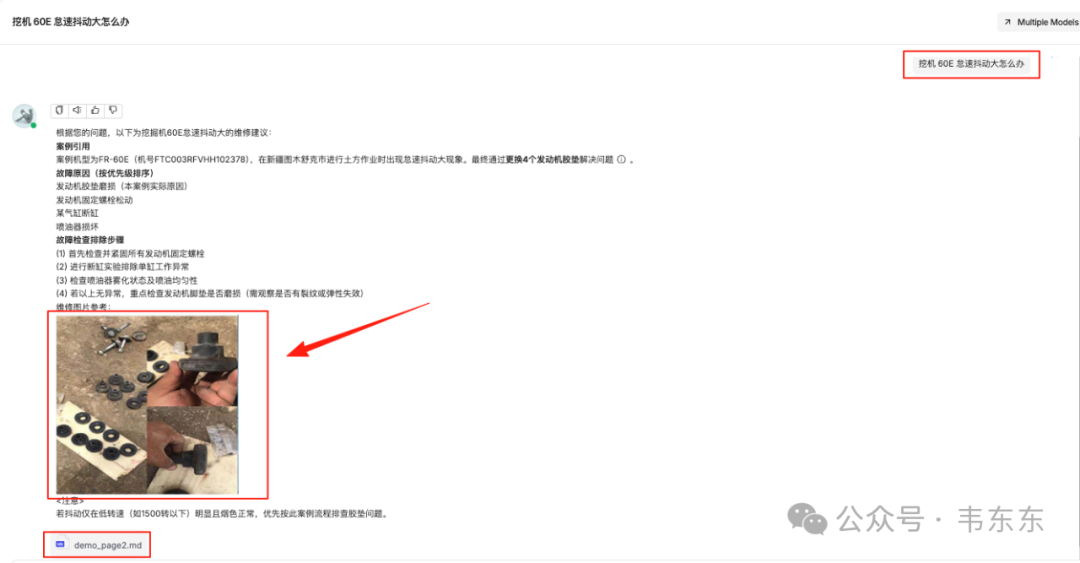
为了更好理解RAGFlow的原生图文问答逻辑,手绘了下图供各位做个参考。
进一步来说,当手动下载 Textin 解析好的MD文档之后可以发现,其中的图片是存到了Textin的服务器上,并通过一个公开访问的链接回填到了文档的对应位置。这和历史文章中介绍过的通过预处理把文档中的图片先保存到 RAGFlow 的 Minio 实例上然后返回一个公开访问 URL 链接的做法殊途同归。
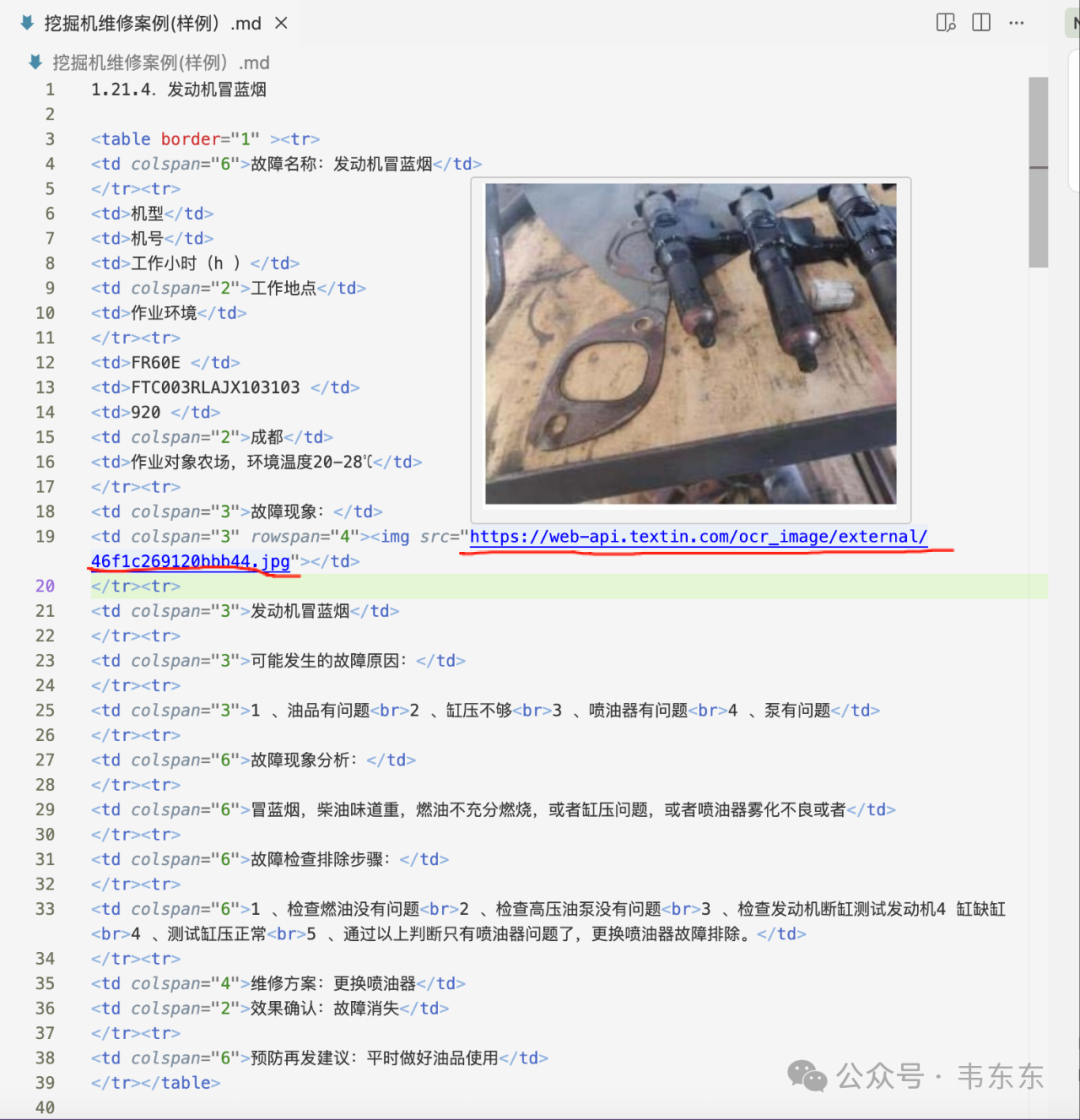
这种URL的方案关键优势在于大模型生成答案会自然继承源分块中的<img>标签,当包含 HTML 标签的答案返回前端时,浏览器会自动解析<img>标签并根据 URL 显示图片,最终实现图文回答呈现。
简单小结一下来说,Textin 作为一款成熟的商业解析工具,在复杂布局的图表文档上,相比与 RAGFlow 内置的 Deepdoc 而言是略胜一筹。关于在实际生产场景中如何使用的问题,肯定不是上述演示的那样通过Textin 的官方或者本地调用Textin api 进行预处理之后再上传到 RAGFlow 知识库。更方便的方式还是进行系统层面的整合集成。以下演示置换和集成Deepdoc 的两种做法。
3、Deepdoc 的解析器置换
如果你倾向于直接使用 TextIn 替换掉 Deepdoc,但又不想对 RAGFlow 的核心分块逻辑进大改。关键是找到解析和分块之间的解耦点,进行一次模块置换。
3.1代码溯源分析
为了找到这个解耦点,我深入分析了 RAGFlow 处理 PDF 的源码,路径位于 ragflow/rag/app/naive.py。整个流程的关键在于 chunk 函数。它通过调用 Pdf 类实例来获得两个核心变量:sections (文本段落列表) 和 tables (表格列表)。这两个变量就是连接解析和分块的数据总线。所以,理论上只要用 TextIn 生成同样格式的 sections 和 tables,就能实现无缝替换。

3.2两步走的改造方案
整个解析器的置换过程分为两步,全部围绕着 ragflow/rag/app/naive.py 文件展开。在开始之前,先通过 docker exec -it ragflow-server /bin/bash 进入容器,并备份一下原始文件,以防万一。
复制改造 Pdf 解析类
首要任务是让 RAGFlow 放弃调用自带的 DeepDoc 解析流程。在 naive.py 文件中,找到 class Pdf(PdfParser): 这个类定义。这个类的 call 方法是 DeepDoc 执行 PDF 解析的入口。它原本包含了一系列复杂的步骤,如布局分析、表格识别等。没必要全部删除,只需要让它提前结束即可。同时,可以保留第一步 self.images(...)的调用,因为 RAGFlow 在前端展示分块对应的原文位置时,需要用到 PDF 的页面截图。将 call 方法修改如下:
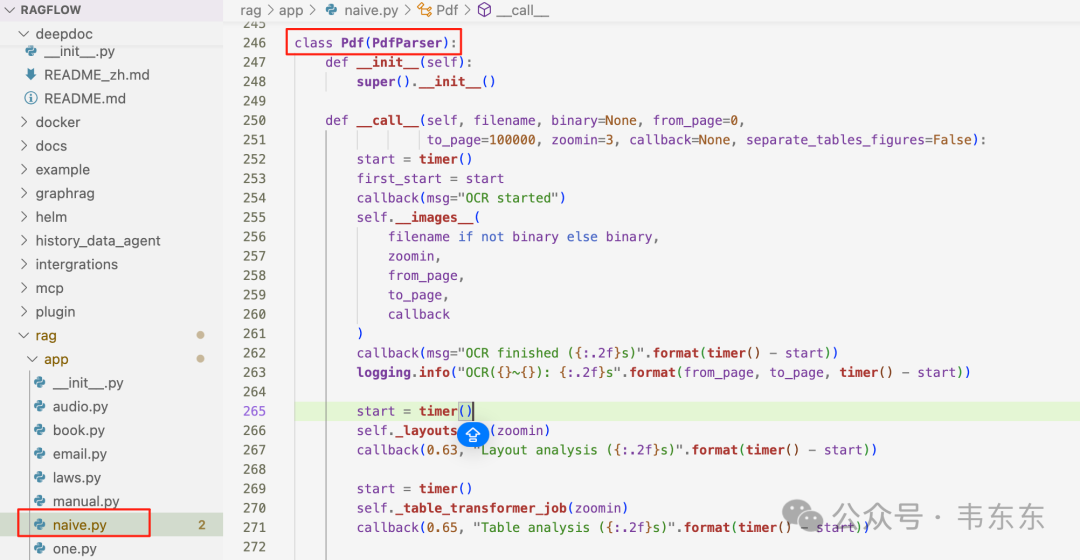
通过在中间插入一行 return [], [],就巧妙地架空了 DeepDoc。Pdf 这个类依然可以被正常调用,但它不再进行任何实质性的解析工作,只会返回两个空的列表,为下一步注入 TextIn 的数据做好了铺垫。
改造 chunk 调度函数
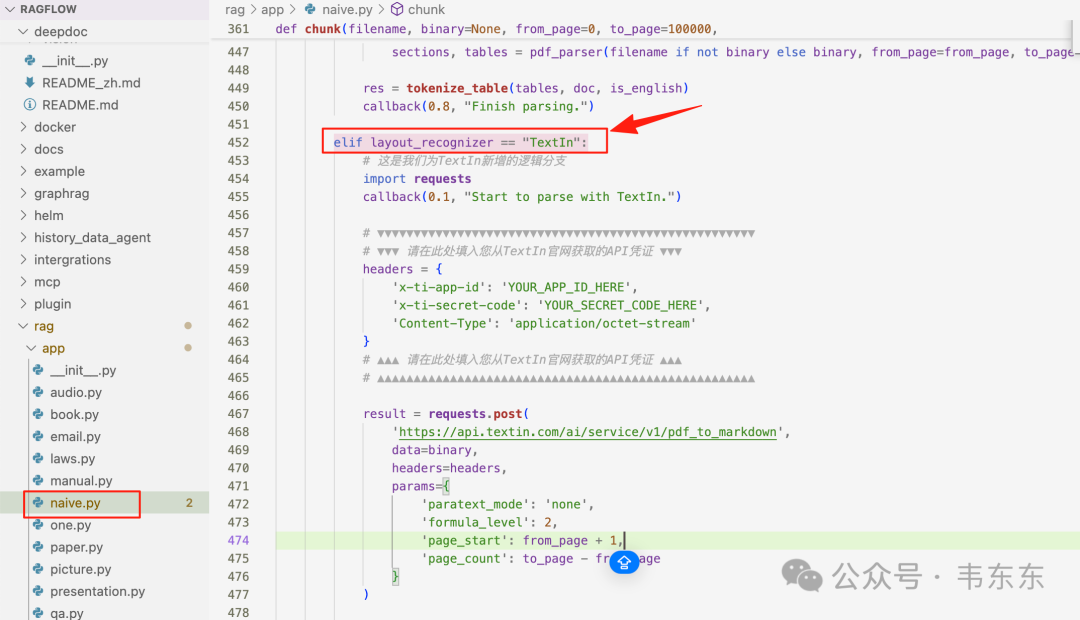
在同一个文件中,找到 def chunk(...) 函数,并定位到处理 PDF 的逻辑分支 elif re.search(r".pdf$", filename, re.IGNORECASE):,再找到 if layout_recognizer == "DeepDOC": 的内部代码块。这里是整个流程的总指挥室。就在这里注入调用 TextIn API 的代码,然后写一个适配器,把 API 返回的 JSON 数据,精确地转换成 RAGFlow 内部流通的 sections 和 tables 数据格式。参考下述代码,把 if layout_recognizer == "DeepDOC": 内部的代码块替换为以下内容:
复制这段代码的核心是 for 循环,它会逐字逐句地把 TextIn 的 JSON 翻译成了 DeepDoc 的特定的 Python 列表和元组结构。通过这种方式,下游的 tokenize_table 和 tokenize_chunks 等分块函数,完全感知不到上游的变化,可以继续它们的工作。(注意,记得去Textin 官方获取对应的访问凭证,更新在上述脚本中。)
重启服务生效
代码修改完成后,需要将其应用到正在运行的 RAGFlow 服务中。使用 docker cp 命令将修改后的文件复制到容器内,覆盖原始文件。
复制把 /path/to/your/local/ 替换成你本地 naive.py 文件所在的真实路径。在 docker 文件夹下,执行以下命令,RAGFlow 会自动加载新的代码。
复制重启完成后,RAGFlow 在处理 PDF 时就已经用上了 TextIn 解析服务。
3.3两个都要怎么办
通过直接覆写 DeepDOC 的逻辑分支,实现了对解析器的替换。虽然这很直接,但无疑也牺牲了灵活性。一个更完美的方案是,在 RAGFlow 的 UI 上增加一个“TextIn”的选项,用户可以自由切换。要实现这一点,需要进行一次小型的全栈开发,包括后端逻辑的扩展和前端界面的修改。
后端改造
后端的修改依然是在 ragflow/rag/app/naive.py 文件中进行。思路是不再替换,而是新增。具体来说,首先把注释或删除的 DeepDOC 分支下的原生代码恢复原状。确保当 layout_recognizer == "DeepDOC"时,执行的是原生的 DeepDoc 解析流程。其次,新增 TextIn 的逻辑分支。在 if layout_recognizer == "DeepDOC":代码块之后,增加一个新的 elif 分支,专门用于处理 TextIn 的逻辑。修改后的代码结构会是这样。
通过这样的改造,后端现在具备了处理三种不同 layout_recognizer 值的能力:"DeepDOC", "TextIn", 和 "Plain Text"。只要前端能传来正确的值,后端就能调用对应的解析逻辑。
前端改造
如图找到 layout-recognize-form-field.tsx 这个文件,从名字也可以看出来是布局识别表单字段。它就是一个用来选择布局识别方式的表单组件。enum DocumentType 是数据源,在文件的第 16-19 行,可以看到一个枚举(enum)定义。 在前端开发中,enum 是定义一组固定选项的“标准答案”。这里明确定义了“PDF 解析器”目前只有两种合法的值:DeepDOC 和 Plain Text。
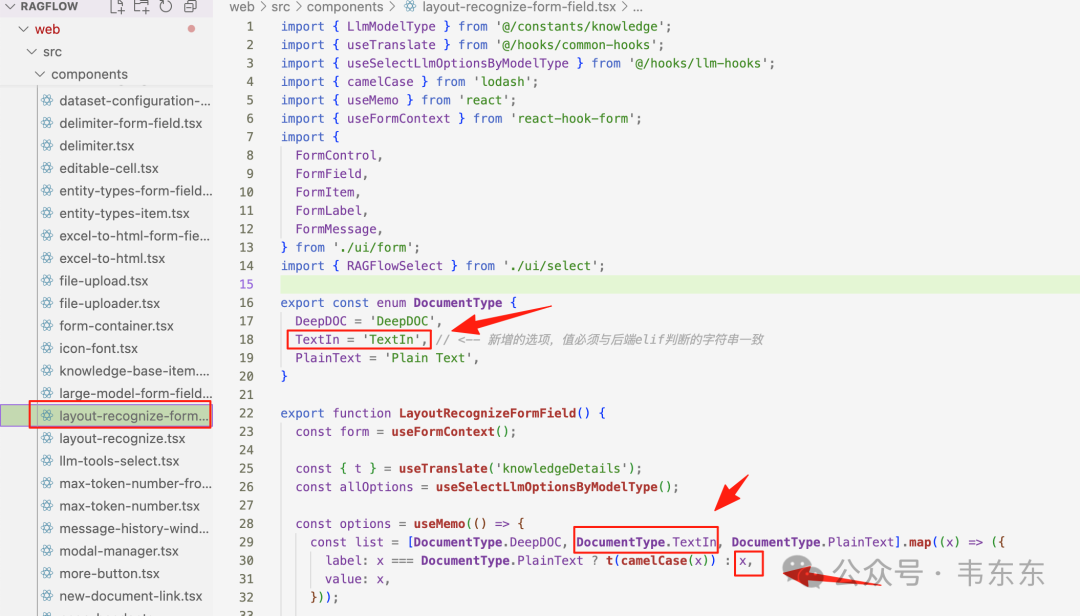
这是需要修改的第一个地方:
复制修改后:
复制const list = [...] 是选择列表:在文件的第 28 行,可以看到这行代码:
复制这行代码的作用是,从上面看到的 enum 标准答案中,取出 DeepDOC 和 PlainText 这两个选项,然后用它们来生成一个列表(菜单),最终渲染成用户在界面上看到的下拉选项。注意,需要同步修改下一行的 label 的生成逻辑,默认直接显示选项的值本身,只对 PlainText 这个特例进行翻译处理。修改后:
复制完成以上两处修改后,就成功地从代码层面为 RAGFlow 增加了 TextIn 选项。注意为了让修改生效,还要执行如下步骤:
- 在前端项目根目录运行 npm install 确保依赖安装完整(如果有 node 版本依赖冲突,就强制安装 npm install --force)。
- 运行 npm run build 编译前端代码,生成最新的静态文件。
- 将新生成的 dist 目录下的内容,替换掉 RAGFlow 服务中对应的旧前端文件,并重启 RAGFlow 服务。
以上修改的完整源码见知识星球
4、写在最后
RAG 系统的优化是一项环环相扣的工程。优质的文档解析结果提供了系统运行的基础,接下来,分块策略也是影响 RAG 能力的重要因素。分块策略目前业界也有很多思考,但其实际应用受制于输入的结构化文件、上下文窗口长度等因素。这里也提出一些可能性,权当抛砖引玉。
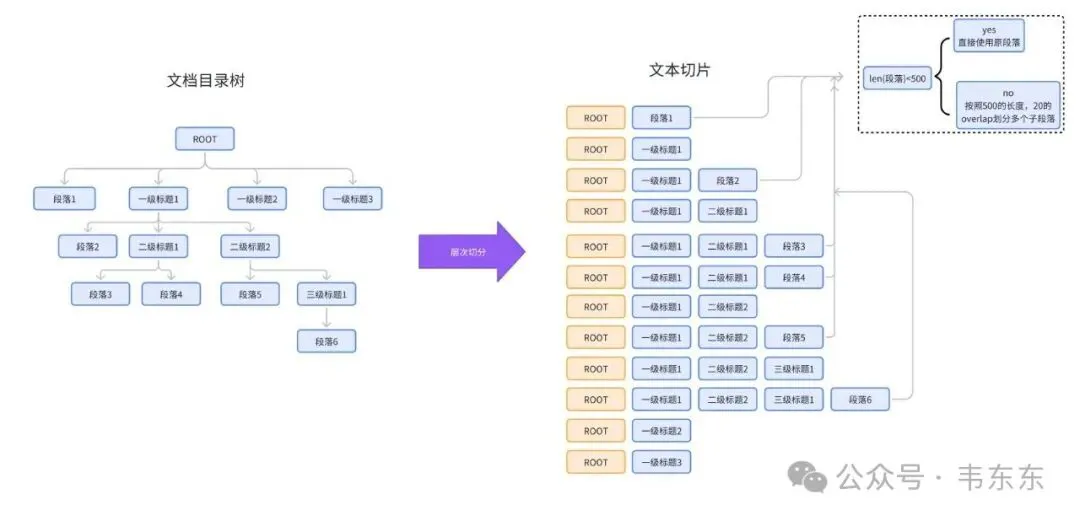
- 保留文档结构:通过目录树(Root/Heading/Text/Table 等节点)维护标题层级关系和语义上下文,实现标题层级递归切片,保留文档内在逻辑结构的完整性。
- 动态处理长内容:超长文本/表格按固定窗口切分,标题节点合并子内容。
- 优化检索效率:以最小内容单元(子段落)作为检索主体,提升匹配精度。


