
如上篇文章最后所言,进一步优化原始文档解析和分块策略是控制变量法下,提高最后检索效果天花板的务实做法。从这篇开始,在对历史项目进行迭代的同时,会陆续对不同的文档解析方法和动态分块策略给出更多的原理解析和案例参考。
 图片来源:
图片来源:
https://liduos.com/ai-develope-tools-series-2-open-source-doucment-parsing.html
这篇以MinerU为由,试图说清楚文档解析工具大致构成,MinerU 和 Deepdoc 对比,MinerU 部署,以及如何和图片服务方案结合使用。
以下,enjoy:
1、三种类型解析工具
在 RAG 流程中,文档解析是第一步,主要任务是将各种格式的原始文档转化为一种统一的、易于处理的中间格式。文档解析这一步的输出格式应该尽可能地通用和灵活,使得后续的分块、向量化等步骤不需要高度依赖于特定的解析工具或其内部实现细节。
除了以 Deepdoc 为代表的集成解析器外,还有开源文档解析库(MinerU 属于这种,后文单独介绍)和云端 API 两种。
1.1开源文档解析库
Unstructured.io:专注于简化各种数据格式(包括图像和文本文件,如 PDF、HTML、Word 文档等)的摄取和预处理,以便用于大型语言模型 。它提供模块化的功能和连接器,可以无缝地协同工作,将非结构化数据高效地转换为结构化格式,同时还具有适应各种平台和用例的灵活性。
PyMuPDF: 是一款轻量级且高效的库,用于处理 PDF 文档、XPS 文件和电子书。它提供了提取文本、图像和元数据的功能,使得开发人员能够轻松地操作和分析 PDF 文档。PyMuPDF 基于成熟的 MuPDF 库开发,支持多种文档格式,并提供文档页面渲染、文本提取(包括 Markdown 格式)、表格提取、向量图形提取等功能 [25]。
Marker: 旨在快速准确地将文档转换为 Markdown、JSON 和 HTML 格式。它支持包括 PDF、图像、PPTX、DOCX、XLSX、HTML 和 EPUB 在内的多种文件格式,能够处理各种语言,并格式化表格、公式、链接、参考文献和代码块,同时还可以提取和保存图像,移除页眉页脚等干扰元素。Marker 尤其在处理书籍和科学论文方面表现出色,并且可以通过 LLM 来提高准确性 。
与使用集成解析器相比,集成和配置这些库 需要更多的开发工作 。某些库可能具有外部依赖项(例如 Unstructured.io 中的 Tesseract 用于 OCR),这些依赖项需要单独管理 。
另外需要考虑许可证的问题,不同的开源许可证对软件的发布和修改有不同的要求,某些许可证(例如 PyMuPDF 的 AGPL)可能会对商业使用产生影响,在特定条件下需要开源衍生作品 。
1.2云端 API
云服务商提供的文档智能 API 也是文档解析的重要选择,它们通常具有高精度的 OCR 能力和处理大规模文档的潜力。
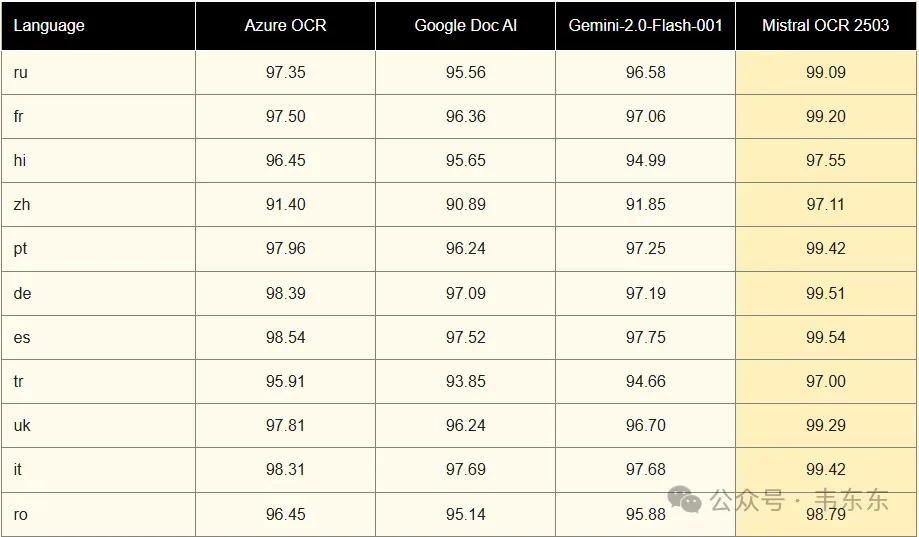
图片来自于Mistral OCR官网
Mistral OCR 是其中的一个典型代表 ,其他知名的服务商还包括 Google Cloud Document AI 和 Azure AI Document Intelligence 。根据 Mistral AI 分享的基准测试,Mistral OCR 的总体准确率达到了 94.89%,超过了 Google 的 83.42% 和 Azure 的 89.52% 。
Mistral OCR我也在测试过程中,后续会专门写篇文章结合案例进行介绍。
2、MinerU vs Deepdoc
说实话,我最早也是在知识星球内有星友提问才知道 MinerU 这个开源项目,之前是花了比较多时间研究 Deepdoc 和 PyMuPDF 的一些优化技术。 后来在公众号、B 站也搜到很多介绍 MinerU 的文章和视频。
我在常逛的 Reddit 的 RAG sub reddit 上也看到有用户评论称,在使用过 llamaparse、docling、pymupdf4llm、unstructured 等工具后,发现 MinerU 是迄今为止最好的 。在 GitHub 上,有用户表示 MinerU 提供了最佳结果,甚至可以识别公式,并且其表格解析和布局检测也更好 。
2.1MinerU
MinerU是一款由上海人工智能实验室的大模型数据基础团队(OpenDataLab)开发的开源数据提取工具,专门用于高效地从复杂的 PDF 文档、网页和电子书中提取内容 。其设计目标是提供高质量的内容提取,并对包括图片、表格、公式等在内的多模态文档具有强大的处理能力 。
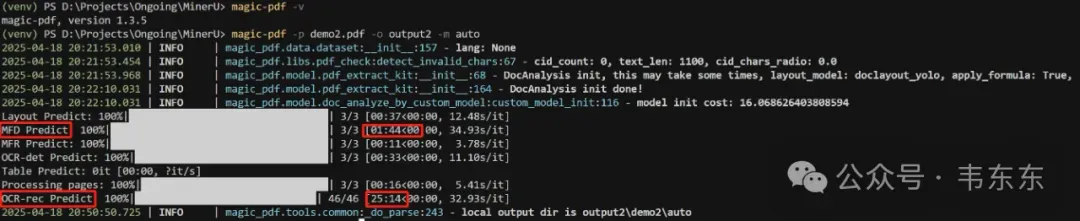
为了更好理解 MinerU 的工作原理,从上述命令行启动日志可以看到多个独立的“Predict”阶段,这表明 MinerU 的解析流程是分解成了多个步骤或模块。
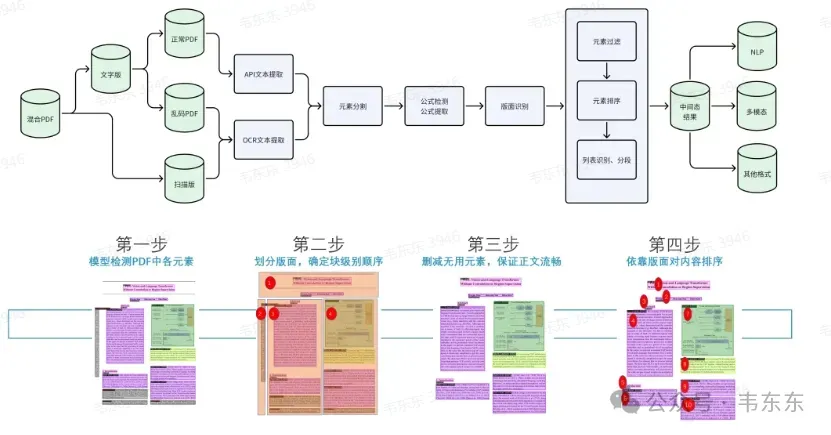
图片来自于上海人工智能实验室的共享飞书文档,感兴趣的点击下方链接移步自取:https://aicarrier.feishu.cn/file/SknGbA2nqoYodbxNjYRcqeUsngf
Layout Predict (版面分析): 识别页面上的主要区域,如文本块、图片、表格、标题、页眉页脚等。这是后续处理的基础。

出处同上
MFD Predict (可能指 Master Feature Detection): 在版面分析的基础上,进一步检测特定对象,日志中紧随其后的是表格相关的步骤,因此这里很可能是专门的表格区域检测。
MFR Predict (可能指 Master Feature Recognition): 在检测到特定对象后,对对象内容进行识别或提取。紧随 MFD 之后,很可能是对检测到的表格区域进行结构和内容识别。
OCR-det Predict: 在文本块内,检测具体的文本行或单个字符的位置。
OCR-rec Predict: 对检测到的文本行或字符区域进行图像到文本的转换,即执行 OCR。
Table Predict (表格处理): 在 MFD 和 MFR 的基础上,进一步处理表格数据,可能包括结构化提取、单元格合并、跨页表格处理等。
Processing Pages (后处理): 整合所有步骤的结果,生成最终的结构化输出(如 Markdown, JSON 等)。
2.2Deepdoc
RAGFlow 的文档解析核心组件被称为 DeepDoc。这并不是一个单一的黑箱,而是一个利用视觉信息和解析技术对文档进行深度理解的系统,其功能模块化地包含了多个部分,这与 MinerU 的模块化思路也是相似的,或者说是殊途同归。
DeepDoc 的主要解析逻辑和模块包括:
OCR: 将图片或扫描文档中的文字识别出来。支持多种语言和字体,并能处理复杂的布局和图像质量。这是基础步骤,将非文本内容转化为可处理的文本信息。
识别: 识别文档的整体布局和 结构,区分不同的内容区域,如标题、段落、表格、图像、页眉、页脚、公式等。这是理解文档结构的关键一步。日志中提到的 Layout Predict 在 DeepDoc 中也有对应的模块。
图片来自:https://github.com/infiniflow/ragflow/blob/main/deepdoc/README_zh.md
表格结构识别 : 专门针对检测到的表格区域,识别表格的行、列、单元格以及合并单元格等复杂结构,并将表格内容结构化提取(例如转换为 HTML 格式)。日志中的 MFD Predict 和 MFR Predict 对应 DeepDoc 的这一能力。
解析器: 针对不同类型的文档格式(如 PDF, DOCX, EXCEL, PPT, TXT, MD, JSON, EML, HTML, IMAGE 等),DeepDoc 提供了相应的解析器来处理。PDF 解析器通常需要结合上述的 OCR、版面分析和表格识别结果来还原文档内容和结构。

出处 同上
后处理: 在各个模块识别和提取信息后,需要进行后处理,例如合并段落、过滤分页信息、清理噪音内容(如页眉页脚、版权声明等),最终生成用于分块和向量化的文本及结构化数据。
对于 PDF 文档,DeepDoc的处理流程通常包括:文档转图片 -> 版面分析 -> 表格识别 -> 文字识别 -> 合并段落 -> 后处理。这个流程与从 MinerU 日志推断的步骤非常相似。此外,DeepDoc 还针对一些特殊文档类型提供了专门的处理逻辑,例如:
简历解析: 将简历这种非标准化文档解析为结构化数据字段(如姓名、工作经历等),而不是简单地分块。
特定格式分块: RAGFlow 提供了多种针对不同文档结构(如通用、问答、表格、论文、书籍、法律、演示文稿、图片、简历等)的模板化分块方法。这些方法会利用 DeepDoc 解析出的文档结构信息,按照更符合文档逻辑的方式进行切分,而不是简单的固定长度或标点符号分块。
2.3孰优孰劣
DeepDoc 和 MinerU 在处理复杂文档时都采取了模块化、多步骤的策略,这是解决文档理解难题的一种常见且有效的方法。它们的主要差异可能在于各模块使用的具体算法、模型的训练数据、工程实现细节以及针对不同文档类型的优化侧重点。
关于优劣的具体对比,文档解析是一个复杂任务,不像图像分类有 ImageNet,文本识别有 ICDAR 等相对标准化的数据集。端到端的文档解析涉及到布局、文本、表格、公式等多种元素的识别和结构化,很难定义一个普适的评测指标和数据集来公平衡量所有系统。不同的文档类型(扫描、电子、复杂布局、多语言等)会导致评测结果差异巨大。
社区成员对解析效果的评价往往是基于他们在自己的文档集上的使用体验,而这些文档集往往具有特定行业的特点和固有的复杂性,某个系统在某个用户的特定文档集上表现更好,并不能代表它在所有文档集上都更好。
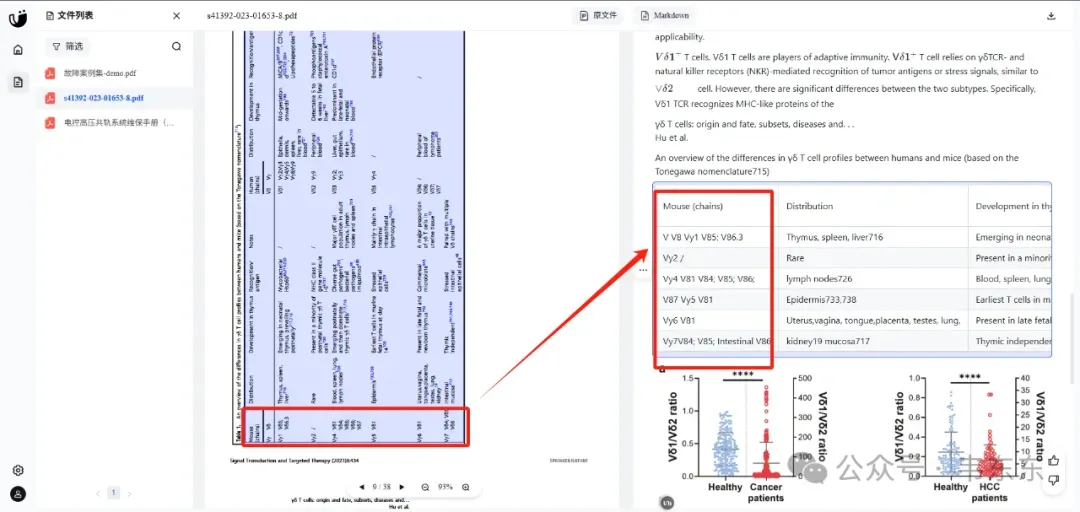
医学paper中的竖向表格识别的很好

医学领域的特殊符号也能正常解析
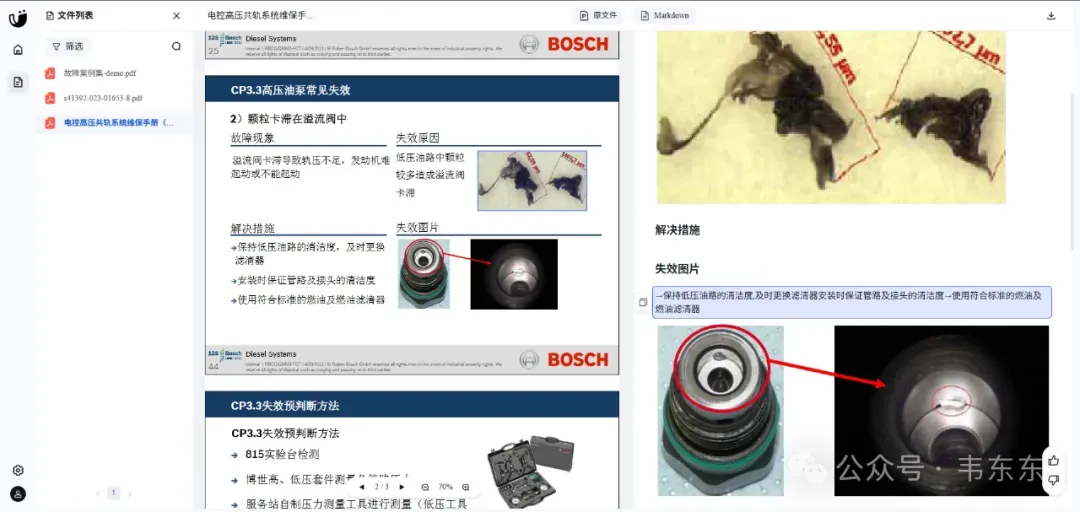
设备维保的PPT布局也能正常识别,而且自动去除了页眉和页脚
我在针对手头目前在做的两个设备维保场景和医学 paper 三个文档进行对比发现,MinerU 确实整体表现优异,但是也有些无法处理的情况。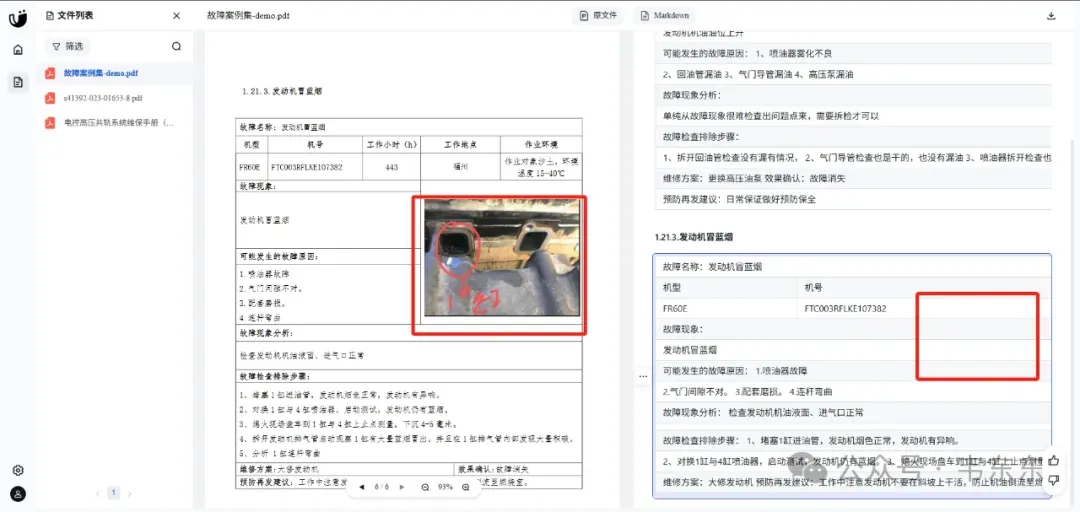
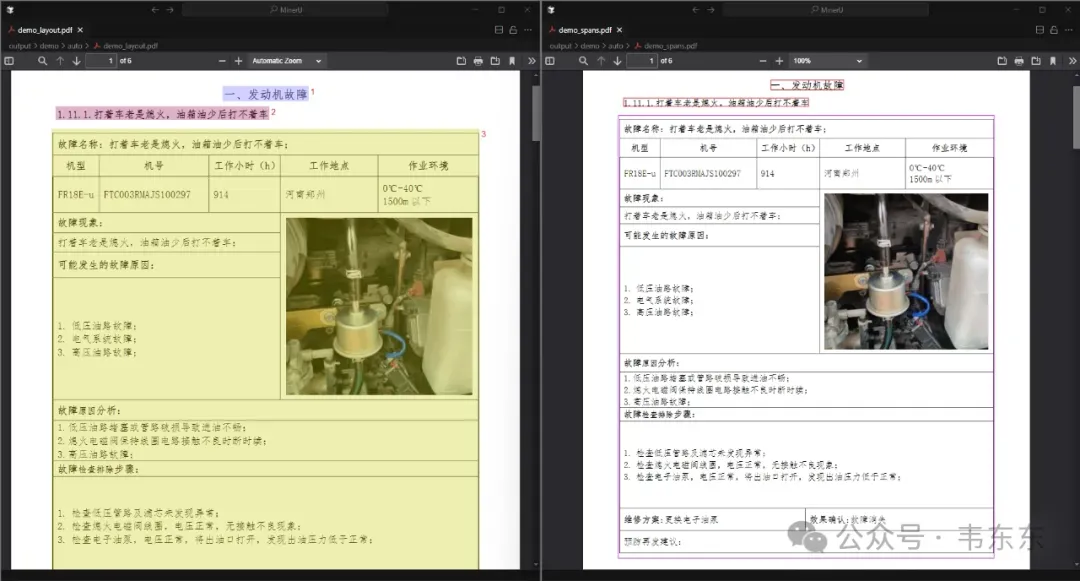
从截图中可以明显看到表格中间部分的图片没有被MinerU正确识别。这是MinerU在处理某些特定情况下的一个局限性。这种情况可能有以下几个原因:
- 表格内嵌图片的识别挑战MinerU在处理嵌入在表格单元格内的图片时,有时会将其视为表格的一部分,而非独立的图像元素,这在复杂布局中是常见的挑战。
- 模型识别边界版面分析模型可能将表格整体作为一个单元处理,没有正确区分出表格中的图片区域与文本区域的边界。
- 图片质量和边界如果图片与表格边界融合得比较紧密,没有明显的分隔线或边框,模型可能难以正确区分。不过我也检索了下MinerU的Github历史迭代记录, 他们确实提供了对这类问题的持续改进,但这个问题显然还没有解决的很彻底。
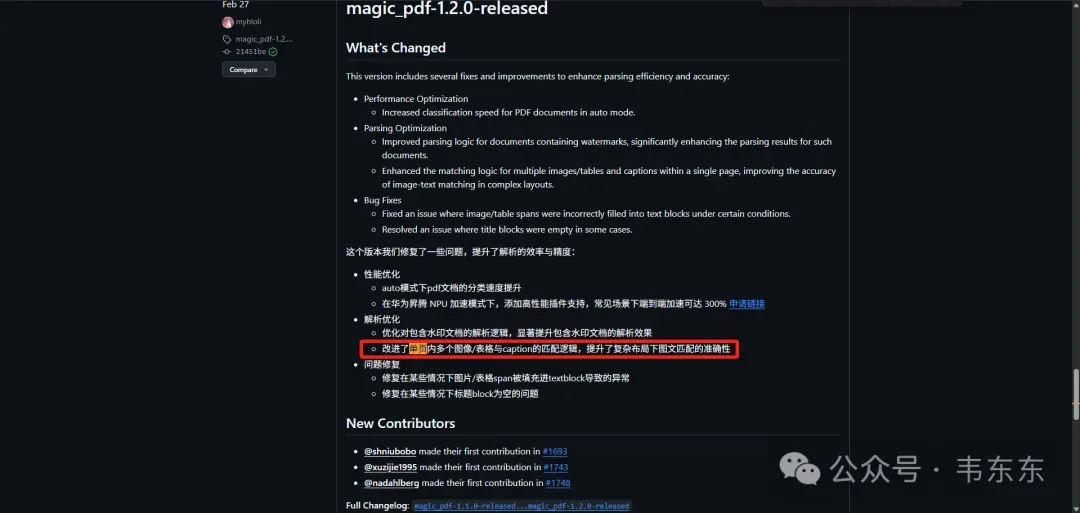
但是这个corner case实际通过PyMuPDF可以很好的被解决,具体请参考历史文章:RAGFlow框架优化经验分享(附代码):图文识别+动态分块 、API调优+源码修改
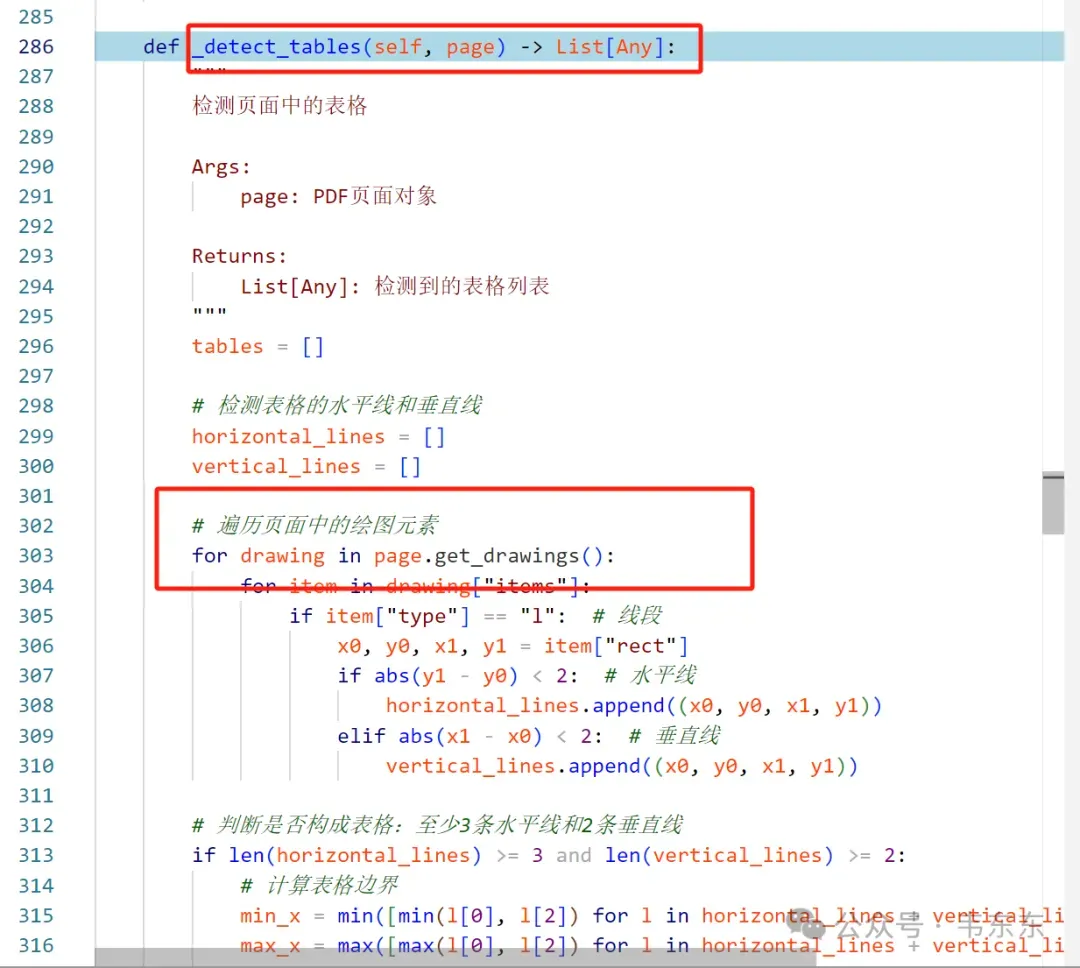
3、MinerU 如何本地配置
看完上述介绍后,感兴趣的盆友可以在 MinerU 官网或者参照流程本地部署下 MinerU 进一步测试。注意,没有哪个绝对更好,能解决你业务需求的更加实际。
以下配置说明节选自官方教程,我做了一定的整理和说明,逐步操作即可。
https://github.com/opendatalab/MinerU/blob/master/README_zh-CN.md
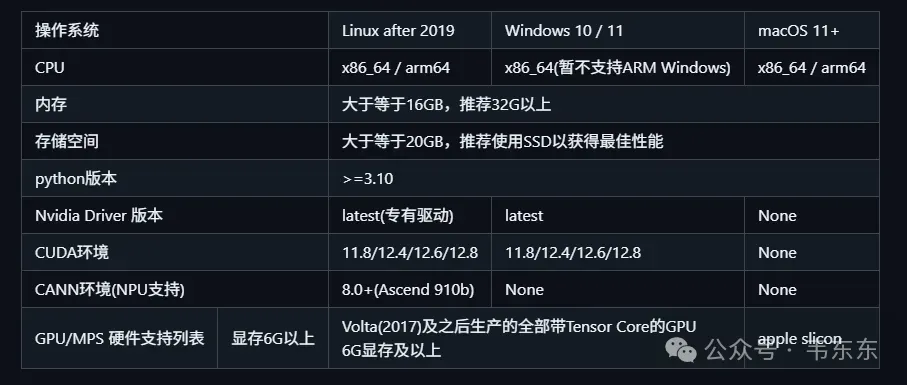
3.1软硬件环境要求
实测纯 CPU 能跑,但是很慢,有条件的建议刚开始就修改下下方提到的 magic-pdf.json使用 GPU 加速。
3.2安装 magic-pdf
复制conda create -n mineru 'python>=3.10' -y conda activate mineru pip install -U "magic-pdf[full]" -i https://mirrors.aliyun.com/pypi/simple
关于创建虚拟环境这一步,windows 用户可以使用:
复制python -m venv venv venv\\Scripts\\activate
3.3下载模型权重文件
复制# 有条件的也可以选择 Hugging Face镜像 pip install modelscope https://gcore.jsdelivr.net/gh/opendatalab/MinerU@master/scripts/download_models.py -O download_models.py python download_models.py
完成下载模型权重文件步骤后,脚本会自动生成用户目录下的 magicpdf.json 文件,并自动配置默认模型路径。可以选择修改该文件中的部分配置实现功能的开关,如表格识别功能,为节省篇幅这部分不做展开讨论。
注:如此前通过 HuggingFace 或 Model Scope 下载过模型,可以重复执行此前的模型下载 python 脚本,将会自动将模型目录更新到最新版本。
3.4两种打开方式
命令行
复制# show version
magic-pdf -v
# command line example
magic-pdf -p {some_pdf} -o {some_output_dir} -m auto注意,输入的文件需要是以下后缀:.pdf .png .jpg .ppt .pptx .doc .docx
{some_pdf} 可以是单个 pdf 文件,也可以是一个文件夹包含多个 PDF,处理结果会保存在 {some_output_dir}文件夹中,文件列表为:
复制├── some_pdf.md # markdown file ├── images # directory for storing images ├── some_pdf_layout.pdf # layout diagram ├── some_pdf_middle.json # MinerU intermediate processing result ├── some_pdf_model.json # model inference result ├── some_pdf_origin.pdf # original PDF file ├── some_pdf_spans.pdf # smallest granularity bbox position information diagram └── some_pdf_content_list.json # Rich text JSON arranged in reading order
使用 API
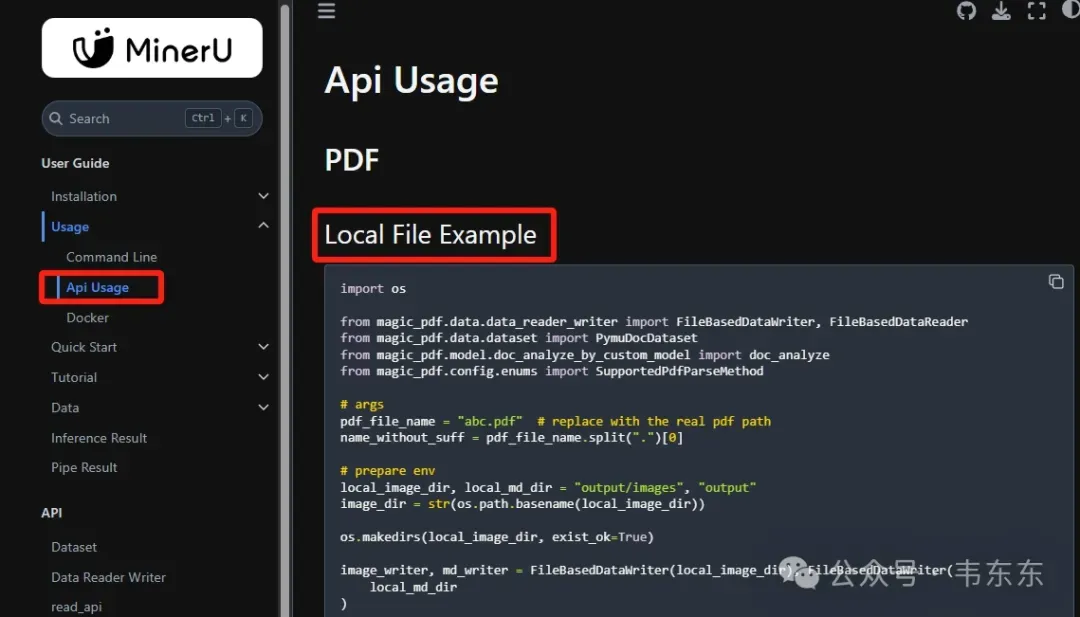
官方提供了标准的 python 示例代码,只需要简单修改即可直接使用,这里也不做赘述。下面重点介绍 RAGFlow+MinerU 整合使用版本。
4、RAGFlow + MinerU 图片服务方案
在使用 RAGFlow 框架结合 MinerU 进行 PDF 文档解析和问答时,MinerU 会智能地提取文档中的文本和图片。为了在 RAGFlow 的问答结果中能够展示这些由 MinerU 提取的图片,我们需要一个可靠的机制来提供图片的网络访问。本项目沿用并改进了原有的独立图片服务器容器方案,使得 RAGFlow 容器能够通过 Docker 网络访问 MinerU 输出的图片资源。
原有独立图片服务器容器方案文章请移步:
RAGFlow如何实现图片问答:原理分析+详细步骤(附源码)
4.1系统架构
系统主要包含两个交互的 Docker 容器:
RAGFlow 容器:负责知识库管理、问答流程和与大模型交互。
图片服务器容器:使用 FastAPI 搭建,提供 MinerU 提取出的图片资源的 HTTP 访问。
两个容器通过 Docker 自定义网络 (rag-network) 连接。RAGFlow+MinerU_test.py 脚本使用 MinerU 解析 PDF,将提取的图片存储到映射给图片服务器容器的卷中。脚本随后将 MinerU 输出的 Markdown 中的[IMG::...]占位符替换为完整的 HTML<img> 标签(包含指向图片服务器的 HTTP URL),然后将处理后的文本上传到 RAGFlow。RAGFlow 在生成回答时,如果需要引用图片,会依赖其知识库中已经包含的 HTML <img> 标签。
4.2项目文件说明
复制1. `RAGFlow+MinerU_test.py`: 核心脚本,整合了 MinerU PDF 解析和 RAGFlow 资源创建。 2. `image_server.py`: 图片服务器的 FastAPI 主程序。 3. `Dockerfile`: 用于构建图片服务器容器的配置文件。 4. `requirements.txt`: 项目所需的 Python 依赖包列表。 5. `README.md`: 本说明文件。 6. `images/`: (可选) 存放 README 中引用的图片。 7. `output_mineru/images/`: MinerU 默认输出图片的目录 (运行脚本后生成)。 8、`download_models.py`: MinerU模型下载文件。
项目源码老规矩同步更新在知识星球内, 接着上面提到的Reddit帖子预告下,五月初我会在知识星球会员微信群内引入RAG日报机器人,每天自动 搜索汇总国内外公开的行业最佳实践案例。

4.3处理流程说明
复制python RAGFlow+MinerU_test.py
此脚本将执行以下操作:
1. 使用 MinerU (`magic-pdf`) 读取并解析指定的 PDF 文件。
2. 提取文本内容和图片,图片保存到配置的输出目录 (`output_mineru/images`)。
3. 生成包含图片占位符 (`[IMG::...]`) 的 Markdown 格式增强文本。
4. 将 Markdown 文本中的 `[IMG::...]` 占位符替换为包含完整 HTTP URL 的 HTML `<img>` 标签。
5. 调用 RAGFlow API:
* 创建数据集 (知识库)。
* 将包含 HTML `<img>` 标签的文本上传到数据集中。
* 触发文档解析 (分块和向量化)。
* 创建聊天助手,关联到该数据集。
* 配置助手的 Prompt,使其能理解并按要求在回答中包含 HTML `<img>` 标签。4.4MinerU 占位符替换 vs. PyMuPDF 直接生成
相比上一版本的独立图片服务器容器方案,新脚本在处理图片链接生成的方式上确实有所不同,做说明如下:
PyMuPDF_test.py 的逻辑 (旧方法):
这个脚本是直接使用 fitz (PyMuPDF) 库来解析 PDF。它在代码中手动遍历页面元素,提取图片,并在组装最终输出文本时,直接在代码中构建 完整的 <img> HTML 标签,包含 http://... 格式的 URL。这种方式给予了开发者完全的控制权,可以在提取的同时就生成最终格式。
RAGFlow+MinerU_test.py的逻辑 (新方法):
这个脚本使用了 magic-pdf (MinerU) 库。magic-pdf 库的设计是将文档解析和 Markdown 输出封装起来。它的标准 pipe_result.get_markdown() 方法输出的是包含 [IMG::...] 占位符 的 Markdown。为了得到最终需要的 HTML <img> 标签和完整 URL,我们在获取 MinerU 的输出后,增加了一个后处理步骤(即 replace_img_placeholders_with_urls 函数),专门负责查找这些占位符并将其替换为完整的 <img> 标签。
评估与选择:
为什么不直接让 MinerU 输出 <img> 标签?
修改 magic-pdf 库内部的 get_markdown 逻辑来直接输出带完整 URL 的 <img> 标签是不推荐的。这会破坏库的标准输出,使得代码更难维护,并且未来升级 magic-pdf 库时可能会遇到兼容性问题。
为什么当前方法 (占位符 -> 替换) 更合适?
遵循库标准: 它利用了 magic-pdf 库的标准输出,代码更清晰,与库的耦合度更低。
关注点分离: MinerU 负责解析和生成带占位符的结构化文本,而链接替换逻辑则独立出来,易于修改和调试。比如,如果以后 URL 格式需要改变,只需要修改 replace_img_placeholders_with_urls 函数。
可调试性: 可以先检查 MinerU 输出的带占位符的 Markdown 文件 (_placeholders.md),再检查替换后的文件 (_with_urls.md),方便排查问题。
结论
虽然 PyMuPDF_test.py的直接生成方式看起来更一步到位,但在当前使用 magic-pdf 库的场景下,采用“先获取带占位符的输出,再进行后处理替换”的方式是更合理、更健壮、更易于维护的选择。RAGFlow+MinerU_test.py当前的实现方式是推荐的。
5、写在最后
5.1特别说明
本篇所介绍的 MinerU 的测评是针对特定案例材料的介绍,不管如何, MinerU 无疑是值得关注和尝试的一个文档解析框架,但是具体效果各位还要结合手头项目文档做仔细横评。我后续会继续 针对 PaddleOCR、Mistra OCR 等 工具进行具体案例测试后写文章出来供参考。
5.2项目升级预告
上一期介绍到 Dify+RAGFLow:基于占位符的图片问答升级方案中,接下来我会在两个方面进行迭代。一方面,计划移除 image_server.py 和对应的 Docker 容器,统一用 MinIO 来解决映射关系和图片的存储问题,解决了本地部署的需求。其次,关于工作流设计 Code 节点批处理限制导致无法流式输出影响体验的问题,计划通过 Tampermonkey 用户脚本为本地 Dify 添加前端图片占位符替换功能。


