昨晚,腾讯开源了2025年世界机器翻译大会(WMT2025)上斩获佳绩的翻译大模型Hunyuan-MT-7B。
根据比赛成绩显示,Hunyuan-MT-7B在中文、英文、法语、德语、马拉地语、爱沙尼亚语、冰岛语、芬兰语、匈牙利语、罗马尼亚语、波斯语、印地语、孟加拉语、泰米尔语、乌尔都语、僧伽罗语等31种主流、小众语言测试中,拿下30个语种第一。
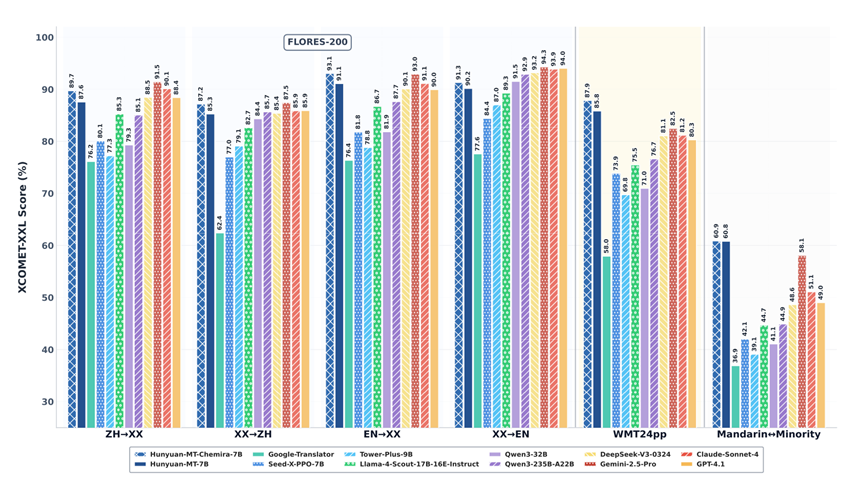
Hunyuan-MT-7B在面对不同语言的复杂语法规则、独特词汇体系以及丰富文化内涵时, 均展现出强大的适应能力与翻译水准,成为同类最佳开源模型。同时在Flores-200 、WMT24pp等权威测试中,超过了谷歌的Gemini-2.5-Pro和Anthropic的Claude-Sonnet-4,可以媲美OpenAI的GPT-4.1。
开源地址:https://github.com/Tencent-Hunyuan/Hunyuan-MT/
https://huggingface.co/tencent/Hunyuan-MT-7B
在线体验:https://hunyuan.tencent.com/modelSquare/home/list
Hunyuan-MT-7B架构简单介绍
在通用预训练阶段,腾讯研究团队采用了涵盖中文、英文以及少数民族语言的海量数据进行混合训练。少数民族语言数据集包含 1.3 万亿个标记,覆盖 112 种非中文/英文语言和方言。
为了确保数据质量,团队开发了一套专有的质量评估模型,从知识价值、真实性和写作风格三个维度对多语言数据进行评分,并采用三级评分系统(0、1、2)对每个维度进行打分。通过加权综合评分,并根据不同数据源的特性对特定维度进行优先级调整,团队筛选出高质量的多语言训练语料。
例如,在处理书籍类和专业网站内容时,优先选择知识水平评分为 2 的文本。此外,为保证多语言训练数据的内容多样性,团队还建立了三个标签系统:学科标签系统、行业标签系统24个类别和内容主题标签系统24 个类别,分别用于平衡学科分布、保证跨行业多样性以及实现多样性管理和针对性过滤。
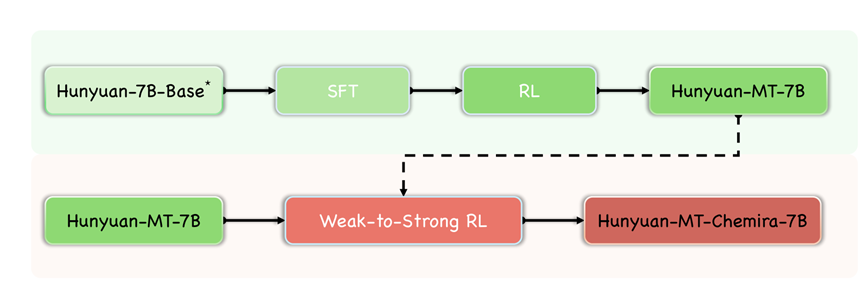
经过这一阶段的训练,腾讯研究团队获得了Hunyuan-7b-Base1基础模型,并且在MMLU-Pro、SuperGPQA、BBH、GPQA、GSM8K、MATH、MultiPL-E等测试中性能很不错。
随后在通用预训练的基础上,腾讯研究团队进一步开展了面向机器翻译的专项预训练。这一阶段的目标是通过精心挑选的单语和双语语料库,进一步提升模型的翻译能力。
单语数据主要来自 mC4 和 OSCAR 数据集,经过严格的清洗流程,包括使用 fastText 进行语言识别、通过 minLSH 进行文档级去重以及利用基于 KenLM 的模型进行质量过滤,以去除高困惑度的文档。对于双语数据,团队则利用公开的平行语料库,如 OPUS 和 ParaCrawl,并采用参考无关的质量估计指标,如 CometKiwi,对句对进行筛选,以确保所选句对的高质量。
为了确定最优的数据混合比例,团队借鉴了 RegMix 的策略。首先在小规模模型上进行实验,拟合一个将采样比例映射到训练损失的函数。通过模拟该函数,找到使预测损失最小化的混合比例,并将其应用于最终翻译模型的面向机器翻译的预训练阶段。此外,为避免灾难性遗忘,团队在训练过程中融入了原始预训练语料库的 20% 回放,并设计了学习率调度,使其在预训练阶段的初始阶段达到峰值学习率,然后逐渐衰减至最小值。
监督微调(SFT)是 Hunyuan-MT 训练过程中的关键环节,旨在通过高质量的标注数据进一步优化模型的翻译性能。SFT 过程分为两个阶段。第一阶段的目标是增强模型的基础翻译能力和对翻译指令的遵循能力。

腾讯研究团队训练了一个包含约 300 万对的大型平行语料库,该语料库来自五个主要来源:开源的 Flores-200 基准的开发集、以往WMT测试集、人工标注的普通话与少数民族语言对、使用 DeepSeek-V3-0324 生成的合成平行语料库以及用于增强模型对一般和翻译相关指令泛化能力的通用和面向机器翻译的指令调整数据集的20%部分。为提高训练数据质量,团队采用参考无关的质量估计指标 CometKiwi 和 GEMBA 对整个平行语料库进行评分,并过滤掉低于预定义质量阈值的训练样本。在GEMBA 评分中,DeepSeek-V3-0324模型本身作为评估器。
第二阶段则旨在通过一个更小但更高质量的约 268,000 对的数据集进一步优化模型的翻译性能。这一阶段的训练数据经过更严格的筛选过程。基于以往研究,团队采用多样本上下文学习来进一步优化训练数据。对于在多轮评估中得分一致性较差的训练样本,团队会进行人工标注和验证,以确保数据质量。
强化学习(RL)在提升具有结构化输出的任务例如,数学问题求解和代码生成的推理能力方面表现出色,但将其应用于机器翻译却面临独特挑战。机器翻译的输出具有丰富的语义多样性,难以通过明确的规则进行评估。
为应对这一挑战,腾讯研究团队采用了GRPO作为强化学习算法,并设计了一个综合的奖励函数。质量感知奖励:为确保强化学习训练期间的翻译质量,采用了两种互补的奖励信号。第一种是 XCOMET-XXL,这是一种在翻译评估场景中广泛使用的指标,与人类评估具有高度相关性。第二种奖励则利用 DeepSeek-V3-0324 进行评分,提示语从 GEMBA 框架中改编而来。
术语感知奖励:虽然基于 XCOMET 的奖励主要关注翻译输出与参考翻译之间的整体语义相似性,但它们可能无法充分捕捉关键信息,如特定领域的术语。为解决这一局限性,团队引入了基于词对齐的奖励指标(TAT-R1 中提出的)。该奖励机制通过词对齐工具提取关键信息(包括术语),然后计算这些关键元素在翻译输出和参考之间的重叠比率。较高的重叠比率将获得更高的奖励,从而增强模型在训练过程中对术语和其他关键信息的关注。
重复惩罚:团队观察到,在强化训练的后期阶段,模型倾向于生成重复的输出,这可能导致训练崩溃。为缓解这一问题,团队实施了一种重复检测机制,当检测到重复模式时,将应用惩罚,以维护输出的多样性和训练的稳定性。
Hunyuan-MT-7B翻译案例
在中文社交媒体情境中,Hunyuan-MT-7B能够准确地将“小红书”解释为“REDnote”平台,并理解“砍一刀”是拼多多的价格削减机制,而Google-Translator 则产生了字面上但不正确的翻译(“sweet potatoes”和“cuts”)。

在英语俚语表达方面,Hunyuan-MT-7B 能够精准地捕捉到非字面意义,例如,将“You are killing me”翻译为表达娱乐而非字面伤害的意思,而 Google-Translator 则未能识别这种非字面用法。
Hunyuan-MT-7B还在特定领域的术语翻译方面表现出色,能够正确地将“血液疾病”和“尿酸性肾结石”等医学术语翻译出来,并且能够成功地在不同语言之间转换完整的地址,而 Google-Translator 则保持了原样。这些例子表明,Hunyuan-MT-7B拥有更深入的语言细微差别、文化背景和领域知识的理解能力,使其能够产生比传统翻译系统更准确、更自然的翻译。
在游戏翻译测试中,输入“d2”和“make a game”, 其他模型未能正确识别d2是指《暗黑破坏神 2》,而是将其误解为普通文本。同时,其他模型错误地将make a game解释为游戏开发,这在游戏社区中并不准确。而Hunyuan-MT-7B正确识别了d2真正意思,并且make a game在这里是指创建一个游戏房间,用于交换游戏物品。

在处理非正式语言时,例如,输入文本中使用了“fucking”这个词。其他模型可能会直接翻译为字面意思,导致翻译结果显得粗俗。Hunyuan-MT-Chimera-7B能够适当地翻译这个词,避免了字面的粗俗语言,从而生成更自然、更符合语境的翻译。
在体育情境中,Hunyuan-MT-Chimera-7B 也展现了其优势。例如,输入文本中提到了“三分”。其他模型可能会错误地将其翻译为“赢得三场比赛”,这在体育语境中是不准确的。而 Hunyuan-MT-Chimera-7B 正确地将其翻译为“三分球”,这在篮球等体育项目中是常见的术语。
网友表示,成果令人瞩目。一个 70亿参数的模型能达到这样的规模,彰显出在效率方面取得了引人关注的进步。这一突破有望推动高质量翻译的普及化。
腾讯携一款轻量却性能强劲的70亿参数模型,正式跻身机器翻译赛道。

很激动,开源才是最佳出路。

版本稳定性出色,其多语言支持功能令人青睐,且整套技术流程展现出强劲的实力。



