今天凌晨,腾讯开源最新图像模型混元Image 2.1。
混元Image 2.1支持原生2K分辨率图像和1000 token的超长篇复杂提示词,并且在文本语义理解和文字嵌入方面非常强几乎完美,能将中英文无缝写入到图像中,很适用于产品封面、插画、海报设计等专业场景
此外,腾讯还开源了基于MeanFlow的加速版模型权重,该版本可将推理步数从100步大幅缩减至仅8步,以及业内首个工业级提示词改写模型 PromptEnhancer,能对提示词进行优化,帮助用户生成更细腻、富有表现力的图像。
开源地址:https://huggingface.co/tencent/混元Image 2.1
Github:https://github.com/Tencent-Hunyuan/混元Image 2.1?tab=readme-ov-file
在线体验:
https://hunyuan.tencent.com/modelSquare/home/play?modelId=286&from=open-source-image-zh-0
混元Image 2.1案例
目前,混元Image 2.1已经可以使用,下面给大家展示一下它的生成效果。
它生成的图像尺寸是可以更改包含1:1、3:4、4:3、9:16、16:9五种类型,一次最多可以生成4张图像。
我们先试几个超难得中英文混合文字嵌入。
提示词:阳光明媚的街角户外书店场景,画面左侧是挂在木质挂钩上的米色帆布包,包身正面用靛蓝色粗体中文印着 “读书行路・见世界”,下方用浅灰色细体英文 “Read & Walk, See the World” 作为点缀,字体下方有简约的黑色线条勾勒出的书本与道路图案;画面右侧是书店的木质招牌,招牌主体为深绿色,顶部用白色宋体中文写着 “转角书店”,下方用白色斜体英文 “Corner Bookstore”。


文字嵌入几乎完美,字体、格式、布局也符合文本提示。
提示词:超写实风格的复古黑胶唱片店宣传海报,画面中央是深棕色木质唱片架,架上整齐摆放着贴有彩色标签的黑胶唱片,唱片架正上方悬挂着米白色亚麻布横幅,横幅左侧用烫金宋体清晰印着中文 “时光回响・黑胶盛宴”,右侧用复古花体英文 “Echoes of Time: Vinyl Feast” 与之对称,字体边缘带有细微的金色光晕;
海报左下角放着一台银色老式唱片机,唱针轻触黑胶唱片,唱片边缘印着黑色英文小字 “Limited Edition 2024”,右下角则用红色楷体标注中文 “每周六下午 2 点・唱片品鉴会”。


提示词:写实风格的街头潮牌 T 恤平铺场景,T 恤主体为黑色,胸前左侧用荧光绿色涂鸦风格字体印着中文 “破界而生”,字体带有不规则的白色泼墨效果,右侧对应位置用荧光粉色英文 “Break Boundaries, Born New”,字体边缘有渐变的银色轮廓;T 恤下摆处用白色小字印着中文 “2024 夏季限定款” 和英文 “Summer Limited Edition 2024”,字体呈弧形排列。


提示词:清晨五点半的阿尔卑斯山脉腹地,朝阳穿过薄纱般的淡粉色晨雾,在覆盖着零星残雪的墨绿色冷杉林顶端洒下金橙色光斑,近处覆着白霜的高山草甸上点缀着紫色龙胆花与黄色毛茛,山脚下的冰川融水溪流泛着淡蓝色光泽,水面倒映着远处锯齿状的雪山轮廓,溪流中几枚半透明的鹅卵石清晰可见,空气里漂浮着湿润的泥土与松针气息,整体画面采用2K超高清分辨率,光影遵循自然侧逆光规律,色调偏清冷却带着晨光的暖意,细节需呈现冷杉树皮的粗糙纹理、霜花的六角结晶结构及溪流水面的微波光斑。


提示词:未来的城市环境,特征是用透明材料建造的高塔建筑,由光桥相互连接,飞行汽车在空中快速穿梭,全息广告投射在建筑物侧面,反映出科技与自然完美融合的社会,具有精确细节和动态角度的建筑设计可视化。


混元Image 2.1架构简单介绍
混元Image 2.1使用了分层的语义信息,包括短、中、长、超长四个层次,这显著提升了模型对复杂语义的响应能力。还引入了OCR代理和IP RAG,解决了通用视觉语言模型在密集文本和世界知识描述方面的不足,并通过双向验证策略确保描述的准确性。
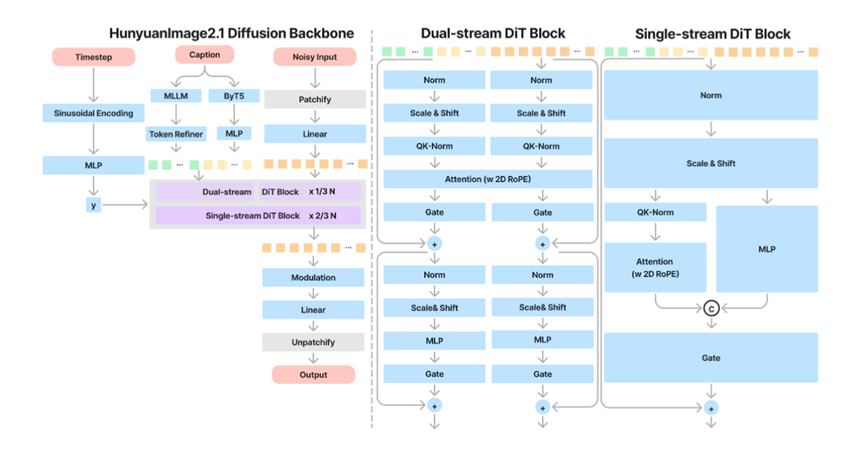
文本到图像模型的架构采用了32×压缩率的VAE,大幅减少了DiT模型的输入token数量。通过与DINOv2特征对齐,加速了高压缩率VAE的训练。多桶、多分辨率的REPA损失函数将DiT特征与高维语义特征空间对齐,加速了模型收敛。
此外,模型还配备了双文本编码器,包括一个用于更好地理解场景描述、人物动作和详细要求的多模态大语言模型,以及一个专注于文本生成和多语言表达的多语言ByT5文本编码器。整个网络是一个拥有170亿参数的单流和双流扩散变换器。
在模型训练的后处理阶段,混元Image 2.1采用了两阶段的后训练方法,包括监督微调和强化学习。为了确保强化学习的稳定性和改进效果,团队引入了奖励分布对齐算法,将高质量图像作为选择样本。
混元Image 2.1 还提出了第一个系统级的工业重写模型。通过SFT训练,该模型能够结构化地重写用户文本指令,丰富视觉表达。GRPO训练使用细粒度语义AlignEvaluator奖励模型,显著提升了重写文本生成图像的语义质量。
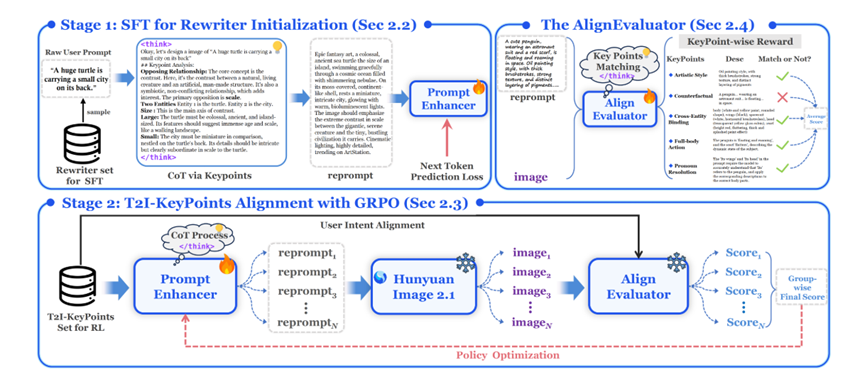
AlignEvaluator覆盖了6大类和24个细粒度评估点。PromptEnhancer支持中文和英文的重写,并在开源和专有文本到图像模型中展现出通用性。为了进一步提升模型的效率,混元Image 2.1 提出了一种基于均值流的新型蒸馏方法。这种方法解决了标准均值流训练中存在的不稳定性和低效性问题,并且能够在仅用几个采样步骤的情况下生成高质量的图像。据所知,这是首次将均值流成功应用于工业级模型。
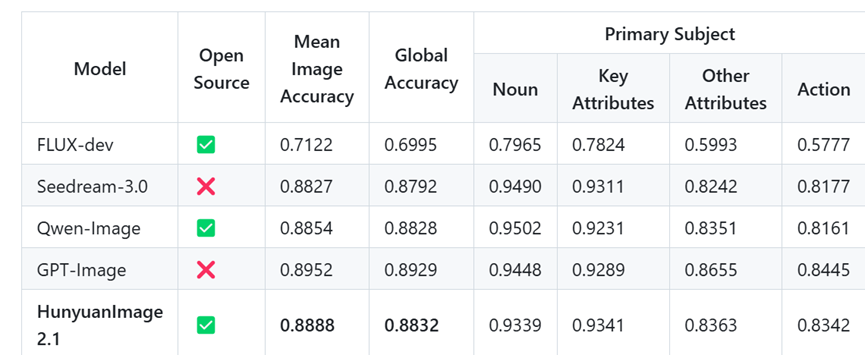
在性能对比方面,混元Image 2.1 采用了SSAE和GSB评估方法。SSAE是一种基于先进多模态大语言模型的智能评估指标,用于评估图像与文本的对齐程度。通过对12个类别中的3500个关键点进行评估,使用多模态大语言模型自动比较生成图像与这些关键点的视觉内容,并进行评分。
从评估结果来看,混元Image 2.1在语义对齐方面达到了开源模型中的最优性能,并且与闭源商业模型的性能非常接近。
GSB评估方法则从整体图像感知的角度评估两个模型之间的相对性能。使用1000个文本提示,为所有比较的模型生成等量的图像样本,并由100多名专业评估者进行评估。评估结果显示,混元Image 2.1与闭源商业模型的相对胜率为-1.36%,并且以2.89%的胜率优于开源模型(Qwen-Image)。
这充分证明了混元Image 2.1作为开源模型,在文本到图像生成任务中达到了与闭源商业模型相当的图像生成质量。


