
大家好,我是肆〇柒。今天我们一起探索一项来自UIUC、Amazon、Purdue大学和斯坦福大学的联合研究——TATTOO。这项研究揭示了一个令人惊讶的现象:尽管现有Process Reward Models (PRMs)在文本推理中表现出色,但在面对表格数据时却近乎"失明"。研究团队通过详实的实证分析发现,当将模型提取的子表替换为随机子表后,PRM给出的奖励分布几乎不变,这意味着PRM无法有效利用表格信息进行监督。针对这一问题,他们提出了创新的TATTOO框架,让PRM不仅能"看见"表格,还能"用工具验证"表格操作,改变了表格推理的监督范式。
表格数据在金融、科学分析和政务决策等场景中无处不在,如何让大型推理模型(LRM)准确理解并推理表格内容已成为人工智能领域的新战场。想象一下,当你需要从一张包含数千行财务数据的表格中快速识别异常交易模式,或是在医疗研究中从复杂的临床试验表格中提取关键结论,这些任务对人类专家都颇具挑战,更不用说对AI模型了。与自由文本不同,表格通过行列结构隐式编码信息,有效推理需要精确解读表格内容并进行逐步逻辑推导。Process Reward Models (PRMs) 作为测试时扩展(Test-Time Scaling, TTS)的关键组件,本应提供步骤级监督以增强 LRM 的推理能力,但实证研究表明,现有 PRMs 在表格推理任务中却表现乏力。当研究者将 LRM 提取的子表替换为随机选择的子表区域后,PRM 给出的奖励分布与原表几乎一致,这揭示了现有 PRM 在表格监督中的根本缺陷——它们无法有效利用表格信息进行可靠监督。
表格推理为何成为 LLM(Large Language Model)的新战场?
表格推理能力已成为新兴大型推理模型(LRM)在现实世界应用中的基础能力,涵盖数值分析、事实核查和问答等多个场景。与自由文本不同,表格通过行列结构隐式编码信息,有效推理需要准确解读表格内容并进行逐步逻辑推导。在表格环境中,模型首先需要正确检索与查询相关的子表区域(Table Retrieval),然后基于检索到的内容进行逻辑推理(Schema Interaction),最后完成计算或得出结论。这一过程对模型的结构化理解能力提出了极高要求。
实证分析表明,在 500 个错误案例中,47.7% 源于 Table Retrieval 错误,34.3% 源于 Schema Interaction 错误,这凸显了表格推理的核心瓶颈。
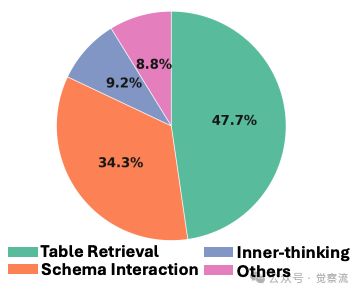
表格推理错误分布
Table Retrieval 指模型定位与查询相关的行/列区域的能力,而 Schema Interaction 则涉及基于检索内容进行的逻辑推理。这两类步骤构成了表格推理的核心,但现有 PRM 对它们的监督能力极为有限。
更细致的错误分类显示,表格推理错误主要集中在单位不匹配(15.0%)、行选择错误(14.8%)、计算错误(11.2%)、列选择错误(10.4%)和部分聚合(9.6%)等类别。
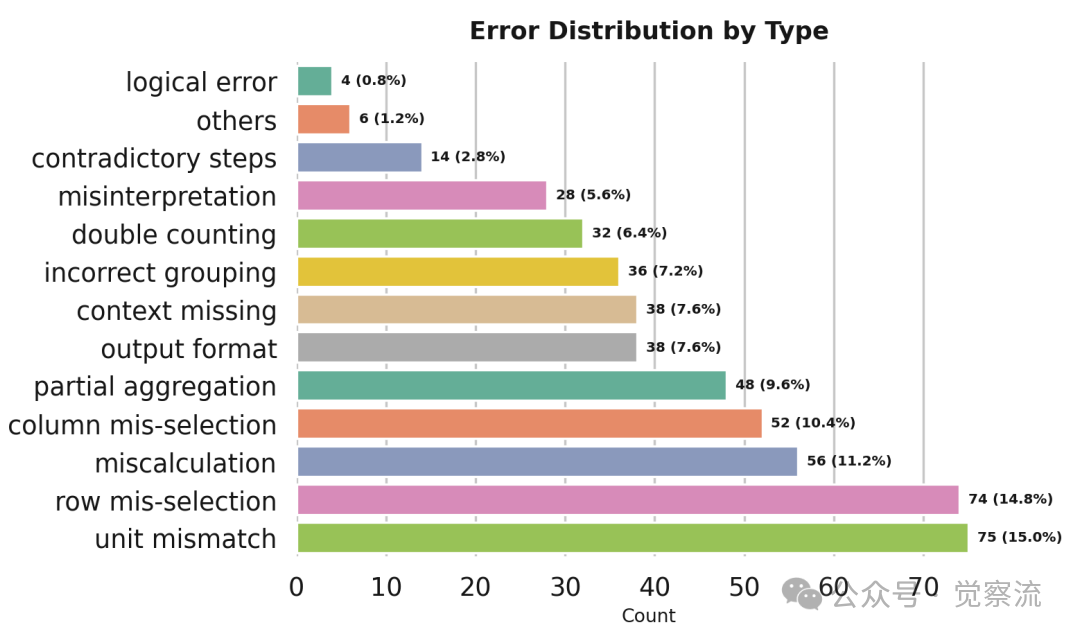
表格推理错误类型分布
这一分布揭示了一个关键问题:表格推理的挑战不仅在于纯逻辑推理,更在于模型对表格结构的理解与操作。
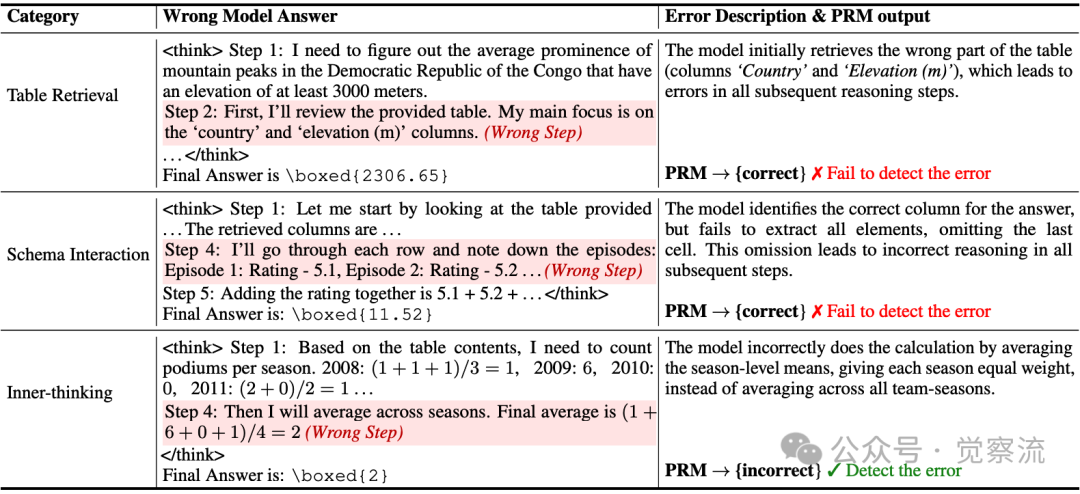
例如,在一个典型场景中,当模型需要计算"平均突出度"时,它本应检索"Prominence(m)"列,却错误地检索了"Country"和"Elevation(m)"列。
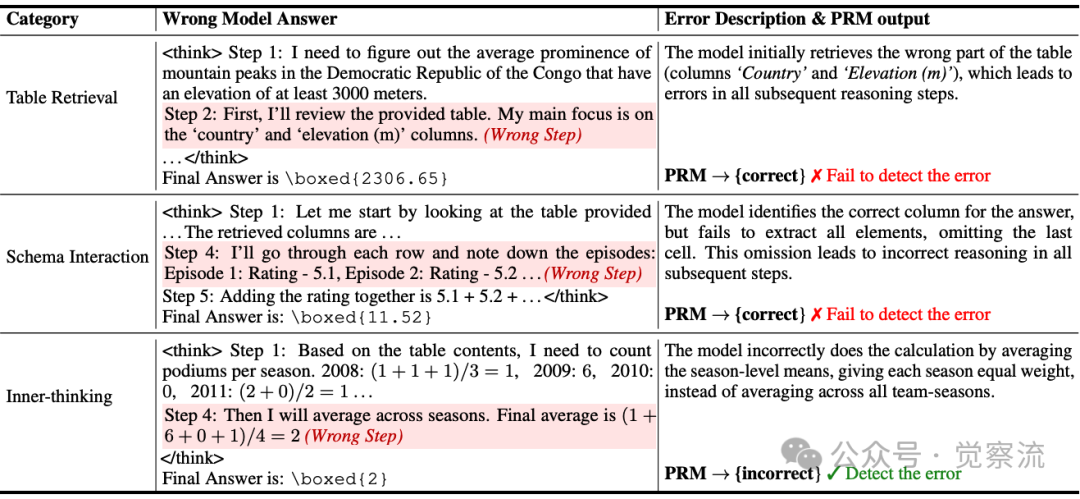
表格推理错误案例
在这个案例中,模型在第一步就错误地检索了无关列,但 PRM 仍给出"correct"的判定,这直接导致了错误的最终答案。这种监督失效使得 PRM 无法有效引导 LRM 修正表格检索错误,从而限制了整体推理质量。
尽管 PRM 能访问原始表格,但实验数据清晰显示它们无法有效利用表格信息。在一项关键实验中,研究者将 LRM 提取的子表替换为随机选择的子表区域后,Qwen2.5-Math-PRM-72B 给出的奖励分布与原表几乎一致。
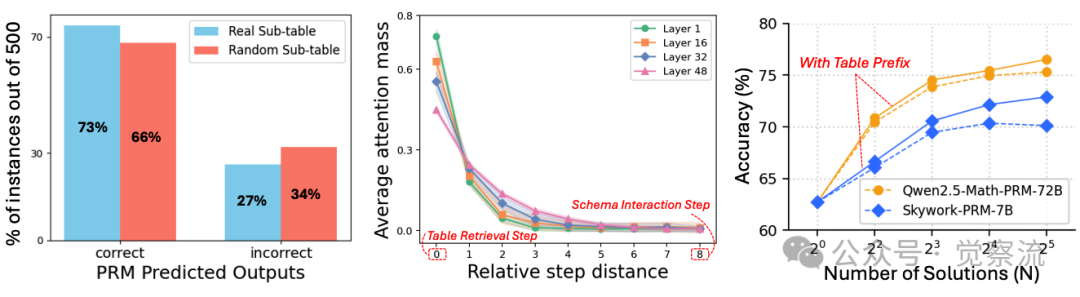
PRM对真实与随机子表的奖励分布
这一现象证明 PRM 对表格检索的正确性不敏感,无法区分相关与无关表格内容,导致其监督信号质量低下。
更令人担忧的是,性能饱和现象进一步印证了现有 PRM 的局限性。
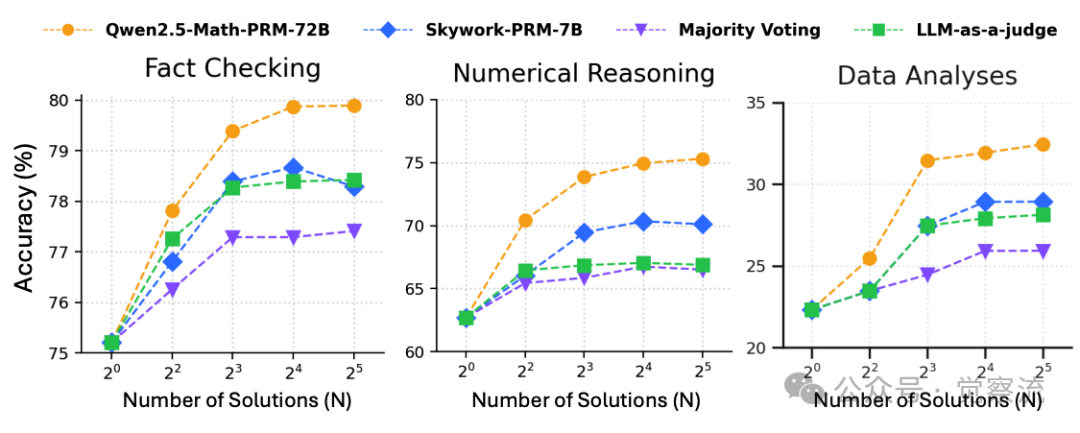
性能饱和现象
上图显示,当响应数量 N≥8 时,即使使用 Qwen2.5-Math-PRM-72B,Fact Checking 任务准确率也停滞在 79.84%,无法充分利用额外测试时计算资源。这一现象在三种表格任务的性能曲线上均清晰可见,表明现有 PRM 无法有效指导 LRM 生成更高质量的推理轨迹。
现有 PRM 的局限性:实证分析揭示两大致命短板及其根源
研究者通过实证分析揭示了现有 PRM 在表格推理中的两大致命短板。在 Table Retrieval 方面,PRM 无法判断模型是否提取了正确的子表区域。实验表明,在 500 个案例中,将 LRM 检索的子表替换为随机选择的子表后,Qwen2.5-Math-PRM-72B 给出的奖励分布几乎不变,这证明 PRM 对表格检索的正确性不敏感。
典型案例显示,当模型错误地检索"Country"和"Elevation(m)"列进行山峰平均突出度计算时,PRM 仍将其判定为正确步骤,导致后续所有推理步骤均出错。
表格推理错误案例
上表中,模型在第一步就错误地检索了无关列,但 PRM 仍给出"correct"的判定,这直接导致了错误的最终答案。这种监督失效使得 PRM 无法有效引导 LRM 修正表格检索错误,从而限制了整体推理质量。
在 Schema Interaction 方面,由于注意力局部性偏置,模型在后续步骤中倾向于忽略早期检索的表格内容。错误分析表明,500 个错误案例中,47.7% 源于 Table Retrieval 错误,34.3% 源于 Schema Interaction 错误。更细致的错误分类显示,表格推理错误主要集中在单位不匹配(15.0%)、行选择错误(14.8%)、计算错误(11.2%)、列选择错误(10.4%)和部分聚合(9.6%)等类别。
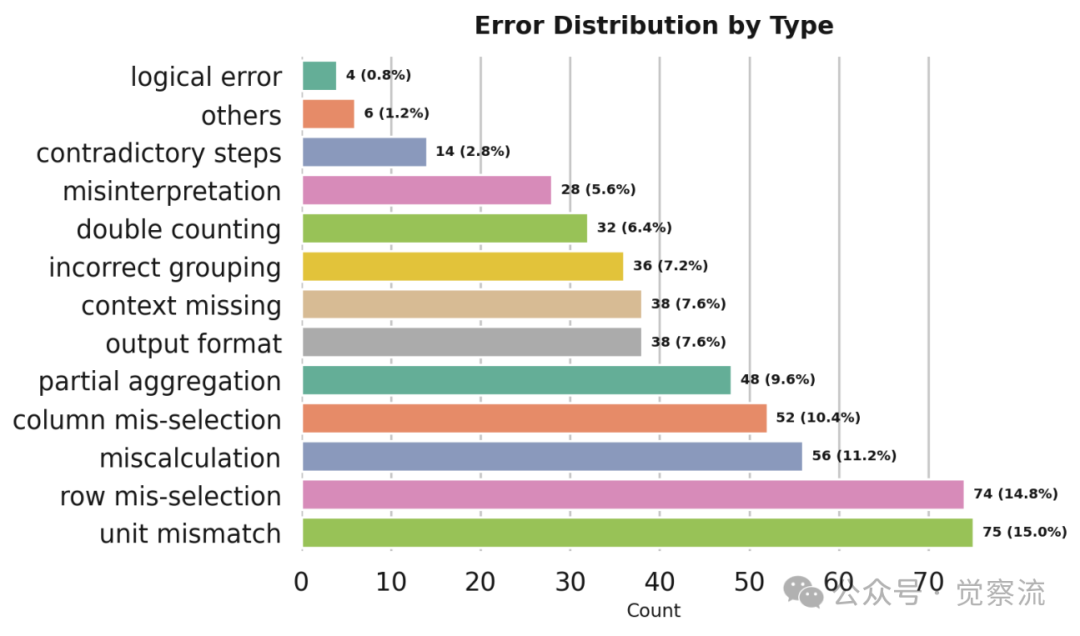
表格推理错误类型分布
注意力分布分析进一步证实,Schema Interaction 步骤(第 8 步)对 Table Retrieval 步骤(第 0 步)的注意力质量随距离急剧衰减,导致模型频繁误解或丢弃先前检索的内容。
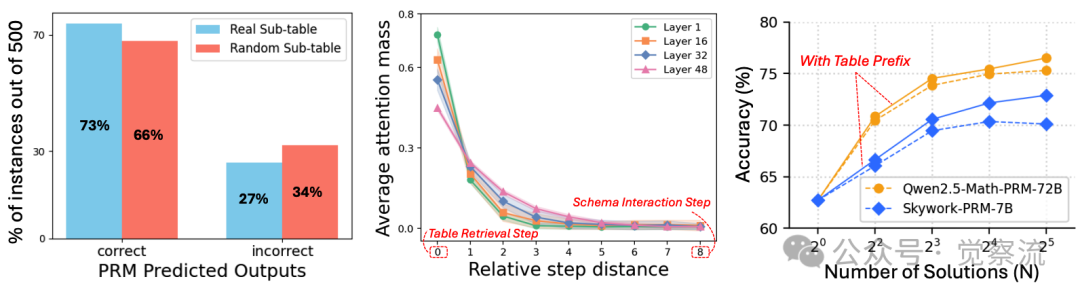
注意力质量随距离衰减
上面中图清晰展示了这一现象,注意力质量从第 0 步到第 8 步急剧下降,使得模型难以维持对早期检索内容的关注。
而现有 PRM 由于评估高度局限于当前步骤,无法捕捉远距离步骤间的依赖关系。Figure 3右图展示了这一关键发现:当在每个Schema Interaction步骤前添加正确的子表前缀时,数值推理任务的准确率显著提升。这一实验结果揭示了一个重要洞见——如果PRM能直接访问相关表格内容,而非依赖远距离注意力,就能有效监督Schema Interaction步骤。
然而,这一方法面临现实挑战:当前PRM无法自动识别Schema Interaction步骤,且LRM检索的子表前缀本身可能不准确。这一发现直接催生了TATTOO的核心创新:让PRM不仅"看得见表格",还能"主动验证表格检索正确性"。在表格推理流程中,当模型进行Schema Interaction时,TATTOO会主动插入工具调用代码,验证检索内容的正确性,从而解决注意力衰减导致的监督失效问题。
TATTOO 的设计哲学:让 PRM "看得见表格、用得了工具"
针对现有 PRM 的局限性,研究者提出 TATTOO(Table Thinking PRM with Tool integration abilities),其核心思想是将奖励监督分解为两类:inner-thinking reward(针对纯文本推理步骤)与 table-aware reward(针对表格操作步骤),以提供针对性监督。
TATTOO 的关键创新在于显式工具集成验证(Tool Integration)。与现有 PRM 不同,TATTOO 在生成验证理由时,主动插入工具调用代码并模拟执行结果作为判断依据。计算工具(如 Python/SQL)用于精确验证聚合与算术操作,避免文本推理中的计算错误;查表工具(如 Polars DataFrame API)用于验证行列检索正确性,解决 Table Retrieval 问题。
在验证容量求和步骤时,TATTOO 会自动生成包含 total_capacity = sum(row[capacity_index] for row in table["data"]) 的代码沙盒,并基于执行结果进行判断。与现有 PRM 的本质区别在于,TATTOO 的验证过程本身成为一种可执行的、可靠的推理,而非仅依赖对文本的判断。
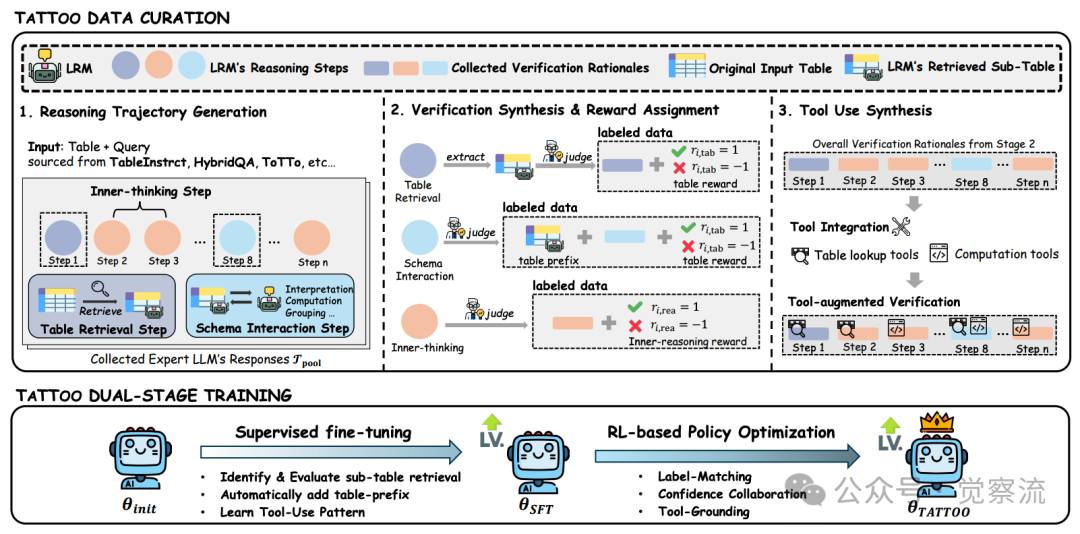
TATTOO框架概述
上图详细展示了 TATTOO 的框架设计。在数据构建阶段,研究者设计了可扩展的数据整理管道,通过整合专家验证理由与工具执行结果,构建了超过 60k 高质量步骤级标注数据集。具体而言,该管道包含三个主要阶段:
1. 推理轨迹生成:从专家 LRM(如 DeepSeek-R1 和 Claude-Opus-4.1)收集表格问题的响应,涵盖 TableInstruct、HybridQA、ToTTo 和 WikiTQ 等多个基准。通过生成多个响应并进行双重验证(人工标注员和专家 LLM),确保数据质量。
2. 验证合成与奖励分配:为每个候选响应提供步骤级验证理由和奖励标签,对表格检索步骤、Schema Interaction 步骤和 Inner-thinking 步骤分别处理。对于表格检索步骤,使用 LLM-as-a-judge 评估检索内容与查询的相关性;对于 Schema Interaction 步骤,将准确子表作为前缀添加到验证理由中;对于 Inner-thinking 步骤,则直接评估推理质量。
3. 工具使用合成:在验证理由中添加工具调用、执行结果和反馈,主要使用两类工具:计算工具(Python/SQL 代码片段)和表格查找工具(DataFrame API)。例如,当验证求和操作时,将手动计算替换为代码执行结果;当需要查找特定单元格时,替换为明确的查找工具调用。
这一数据构建方法确保了 TATTOO 能够学习到精确的表格验证能力,而非仅依赖于文本推理。通过将工具调用整合到验证过程中,TATTOO 能够提供更可靠、更精确的监督信号,有效解决现有 PRM 在表格推理中的"失明"问题。
值得注意的是,TATTOO 的验证过程本身成为一种可执行的推理轨迹,这与传统 PRM 仅提供判断结果有本质区别。当 TATTOO 验证一个计算步骤时,它会生成可执行的代码片段,通过实际执行来验证结果,而不是依赖文本推理中的计算。这种设计使得 TATTOO 的验证过程本身具有高度可靠性,避免了传统 PRM 在复杂计算中容易出错的问题。
双阶段训练范式:从模仿到强化的跃迁
TATTOO 采用双阶段训练范式实现从基础工具使用能力到可靠验证能力的跃迁。第一阶段为监督微调(SFT),使模型学习识别准确子表区域、动态整合检索表格前缀到每个 Schema Interaction 步骤,并生成带有工具集成模式的验证理由。SFT 阶段建立了基础工具使用能力,但验证仍可能出错。

TATTOO训练动态
上图展示了 TATTOO 和变体的训练动态,SFT+RL 训练过程中的奖励信号持续提升,而仅使用 SFT 或规则基线的模型则无法达到相同水平。这直观证明了双阶段训练的有效性。
理论分析通过 Theorem 4.1 揭示了 TATTOO 如何改进下游策略。该定理表明,TATTOO 的分解奖励设计能通过提升奖励信号的可区分性(variance)与对策略优势的对齐度(alignment),共同驱动下游 LRM 的策略改进:

特别值得注意的是,TATTOO 的奖励设计通过工具集成实现了对表格操作的精准监督。在 TB-DA(数据分析)任务中,47.7%的错误源于 Table Retrieval,而 TATTOO 通过 tool-grounding 项使 PRM 能够准确识别这些错误,从而引导 LRM 改进其表格检索能力。这种针对性监督是传统 PRM 无法实现的,因为它们缺乏对表格内容的精确验证能力。
实验结果与泛化能力:精准打击,全面领先
突破性能瓶颈:持续扩展的TTS能力
鉴于 82% 的错误集中于 Table Retrieval (47.7%) 与 Schema Interaction (34.3%),TATTOO 针对性地强化这两类步骤的监督,取得了显著效果。在 TableBench 数据分析(TB-DA)任务上,TATTOO 将准确率从 27.7% (N=4) 提升至 34.3% (N=32),绝对提升 6.6 个百分点。
在 TableBench 数值推理(TB-NR)任务上,TATTOO (78.1%) 显著超越 Qwen2.5-Math-PRM-72B (75.3%),且性能随 N 增加持续提升,而基线在 N=16 后即达到饱和。
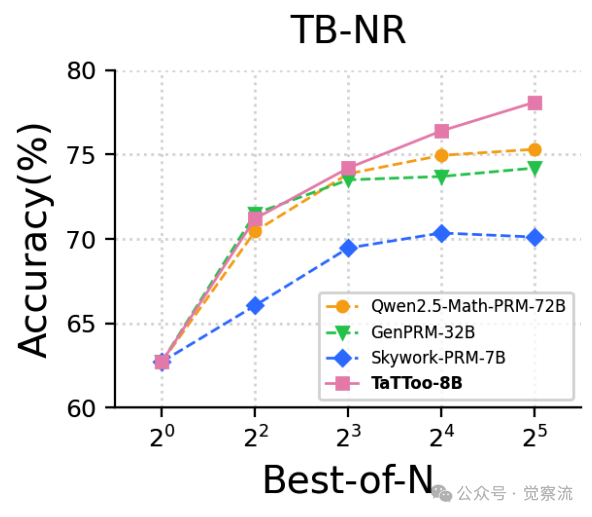
TB-NR任务上随N增加的性能曲线
上图清晰展示了这一趋势,TATTOO 在 N=32 时达到 78.3%,而 Qwen2.5-Math-PRM-72B 在 N=16 后几乎停滞。
TATTOO在TB-DA(TableBench数据分析)任务上的突破性提升(+6.6%)直接对应其解决的核心问题。数据分析任务高度依赖准确的Table Retrieval(占比47.7%)和Schema Interaction(占比34.3%),而这两类错误正是TATTOO的专攻领域。相比之下,TB-FC(事实核查)任务中Inner-thinking步骤占比更高,因此提升幅度相对较小(+2.2%)。这一任务差异性验证了TATTOO设计的针对性——它不是通用PRM的简单替代,而是专为表格推理瓶颈量身定制的解决方案。
在五个表格推理基准(TableBench、WTQ、MMQA 等)上,TATTOO 平均提升 30.9%,展现了卓越的泛化能力。尤为引人注目的是其参数效率:TATTOO-8B 在 TableBench 事实核查(TB-FC)任务上达到 82.0% (N=32),超越参数量 9 倍于它的 Qwen2.5-Math-PRM-72B (79.8%),实现了以小博大的技术突破。
TATTOO的参数效率奇迹源于其精准的监督靶向性。传统PRM需庞大参数量来泛化各种推理模式,而TATTOO通过将监督分解为inner-thinking reward与table-aware reward,使8B参数模型能专注于表格推理的关键瓶颈。参数敏感性分析进一步证实,当=0.8和=1.0时,模型达到最佳性能平衡点。这种精准调控使TATTOO能以小搏大,在TB-FC任务上以8B参数实现82.0%的准确率,超越参数量9倍的竞品。
双阶段训练的必要性:SFT vs SFT+RL
消融实验表明,双阶段训练对 TATTOO 的性能至关重要。Table 3 显示,仅 SFT 训练的 TATTOO 平均准确率为 72.3%,而加入 RL 后提升至 78.5%,带来 10.2% 的平均准确率提升。

SFT与RL阶段验证对比
奖励塑形组件分析进一步揭示了各部分的贡献:移除 tool-grounding 项导致 TB-DA 任务在 N=32 时下降 4.0%,证明工具调用对表格验证至关重要;排除 confidence calibration 使 TB-FC 任务平均下降 1.6%,显示其在稳定奖励信号中的互补作用。
案例研究直观展示了 RL 训练前后的差异:SFT 阶段的 TATTOO 仅靠文本推理验证步骤 3 的计算,得出错误结果 16,920 并错误判定步骤不正确;而 RL 阶段的 TATTOO 学会调用 Python 代码进行验证,正确计算出 22,460 并准确判定步骤正确。随机抽样 500 条轨迹的分析表明,RL 训练后工具集成比例提升了 26.3%。
奖励塑形参数的敏感性分析揭示了TATTOO性能的精细调控空间。当λcal从0.3提升至0.8时,TB-DA任务准确率从33.1%提升至34.3%,表明适当的置信度校准能稳定训练过程;当λtool从0.1提升至1.0时,TB-DA任务准确率从30.8%跃升至34.3%,证明工具集成对表格验证的决定性作用。但过度强调任一组分都会导致性能下降——当λcal=1.0或λtool=1.3时,性能开始回落。这种精确的参数平衡使TATTOO能在不同任务间保持稳健表现,也凸显了双阶段训练中RL微调的必要性。
TATTOO 在 Best-of-N、Beam Search 和 Diverse Verifier Tree Search (DVTS) 三种测试时扩展策略下均表现稳健,无性能饱和现象,能有效利用更大的响应池。
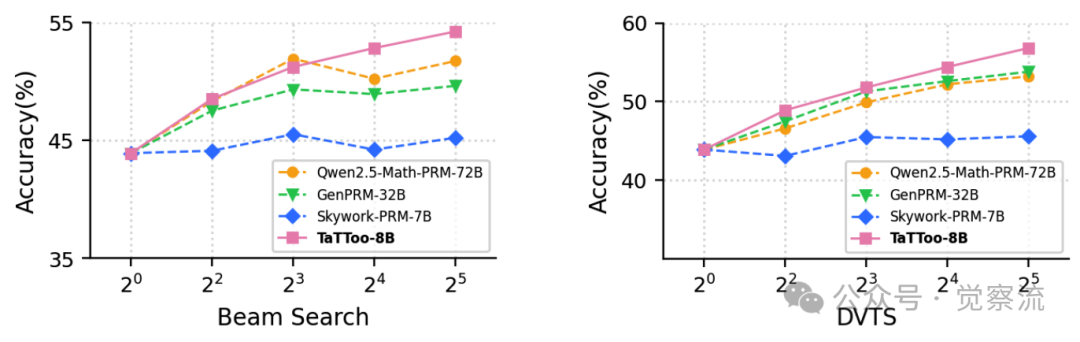
TATTOO在多种TTS策略下的表现
在 Beam Search 中,TATTOO 将平均准确率从 45.0% 提升至 54.8%,而 GenPRM-32B 则饱和在 51% 左右。这些结果突显了 TATTOO 在不同 TTS 策略下的一致优越性,证明其不仅能突破性能瓶颈,还能有效利用更大规模的测试时计算资源。
特别值得注意的是,在 TB-DA 任务中,TATTOO 的性能随 N 增加而持续提升,而其他 PRM 在 N=16 后即达到饱和。这表明 TATTOO 能够有效区分更多样化的推理轨迹,为下游 LRM 提供更丰富的监督信号。这种能力源于 TATTOO 的工具集成验证机制,使其能够精确评估表格操作的正确性,而不仅仅是依赖文本推理的表面一致性。
对我们的启示
TATTOO 的研究揭示了一个重要洞见:表格推理不能仅靠"文本思维",必须引入结构感知与可执行验证——验证过程本身应成为可靠的推理。PRM 的未来发展方向是从"判官"变为"工具化验证智能体",其验证过程具备可执行性与可靠性。
对工业实践而言,构建高质量步骤级监督数据与工具链集成构成可扩展的推理监督范式;双阶段训练(SFT+RL)是培养工具使用能力的关键路径;奖励塑形设计应明确鼓励工具调用,而非仅关注最终正确性。
然而,TATTOO 也面临现实挑战。与仅 SFT 训练相比,RL 阶段引入了额外的计算开销,包括额外的 rollout、奖励评估和优化步骤,这增加了训练成本和资源需求,可能影响低资源环境的可复现性。此外,当前框架仅限于文本-表格推理,尚未扩展到多模态表格(含图表)。如果工具或训练数据包含错误,这些错误可能被放大而非纠正,因此需要探索验证器可靠性审计机制。
特别值得关注的是,TATTOO 的设计理念可能适用于其他结构化数据推理任务,如代码理解、公式推导等。在这些任务中,同样存在"文本思维"与"结构感知"的鸿沟,而工具集成验证机制可能提供类似的性能提升。随着结构化数据在AI应用中的重要性不断提升,这种将验证过程本身设计为可执行推理的方法,有望成为下一代推理监督框架的核心思想。


