自然语言处理

多模态RAG技术:从语义抽取到VLM应用与规模化挑战
一、基于语义抽取的多模态 RAG多模态 RAG 的发展方向旨在构建一个高度集成的系统,能够无缝融合文本、图像和其它多媒体元素,为用户提供更丰富的信息交互体验。 实现多模态 RAG 系统的三种主要技术路径如下:传统对象识别与解析(雕花路线)传统的多模态文档处理首先会运用图像识别技术,如 OCR(Optical Character Recognition,光学字符识别),从图像中抽取出文字、表格和图片等元素。 之后,这些独立的对象会被进一步解析,转换成文本格式,以便于后续的信息检索与分析。
用有限的预算构建AI应用程序
译者 | 布加迪审校 | 重楼人工智能(AI)已经成为现代软件应用程序不可或缺的一部分,因为它可以为传统应用程序添加更强大的功能。 本教程将指导你使用一种简单的方法来构建AI应用程序。 人工智能(AI)已经成为现代软件应用程序不可或缺的一部分,因为它可以为传统应用程序添加前所未有的更强大功能,比如语音识别、图像检测/分类以及自然语言处理(NLP)等等。

提高深度学习模型效率的三种模型压缩方法
译者 | 李睿审校 | 重楼近年来,深度学习模型在自然语言处理(NLP)和计算机视觉基准测试中的性能稳步提高。 虽然这些收益的一部分来自架构和学习算法的改进,但数据集大小和模型参数的增长是重要的驱动因素。 下图显示了top-1 ImageNet分类精度作为GFLOPS的函数,GFLOPS可以用作模型复杂性的指标。

基于PyTorch的大语言模型微调指南:Torchtune完整教程与代码示例
近年来,大型语言模型(Large Language Models, LLMs)在自然语言处理(Natural Language Processing, NLP)领域取得了显著进展。 这些模型通过在大规模文本数据上进行预训练,能够习得语言的基本特征和语义,从而在各种NLP任务上取得了突破性的表现。 为了将预训练的LLM应用于特定领域或任务,通常需要在领域特定的数据集上对模型进行微调(Fine-tuning)。
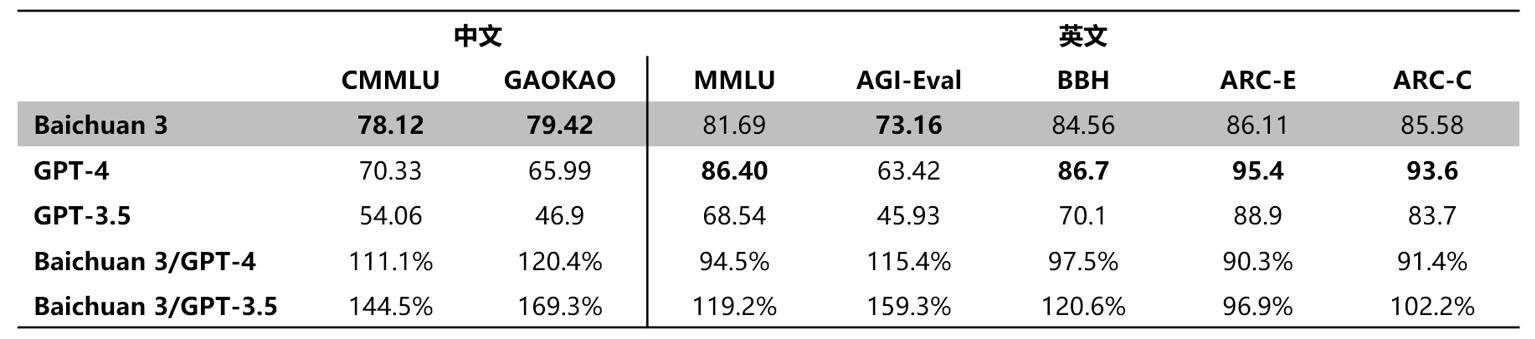
百川智能发布超千亿大模型Baichuan 3,中文评测水平超GPT-4
1 月 29 日,百川智能正式发布千亿参数的大语言模型 Baichuan 3。在多个权威通用能力评测如 CMMLU、GAOKAO 和 AGI-Eval 中,Baichuan 3 都展现了出色的能力,尤其在中文任务上更是超越了 GPT-4。而在数学和代码专项评测如 MATH、HumanEval 和 MBPP 中同样表现出色,证明了 Baichuan 3 在自然语言处理和代码生成领域的强大实力。不仅如此,其在对逻辑推理能力及专业性要求极高的 MCMLE、MedExam、CMExam 等权威医疗评测上的中文效果同样超过了
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉