自然语言

Alexa+大升级!2026年起整合Expedia、Yelp等四大平台,Amazon欲打造AI版“超级入口”
继微软、OpenAI ChatGPT纷纷接入第三方服务后,亚马逊也加速将Alexa 从语音助手转型为AI驱动的消费服务平台。 公司于12月23日宣布,自2026年起,Alexa 将新增Angi(家庭服务)四大深度集成,用户可通过自然语言对话直接预订酒店、预约美发、获取家装报价、筛选餐厅等,无需打开任何App。 自然语言即操作指令,AI成为“万能中介”新功能延续Alexa 的多轮对话能力,支持动态调整需求。

一文看懂使用HuggingFace的完整拼图
无论你开发怎样的AI应用,如何依托成熟的开源技术栈进行应用构建都是一个关键的路径。 本文通过解析从环境配置到服务部署的完整链路,基于HuggingFace的生态系统,结合对话系统、内容生成等典型场景案例,为开发者提供可复用实施参考。 1.

微软 Copilot AI 实现邮件和文件直接连接,提升办公效率
近日,微软宣布对其 Copilot AI 助手进行了重要升级,允许用户直接连接 Outlook、Gmail 等多款个人生产力应用。 这项新功能的推出,使得用户在处理日常工作任务时更加高效,能够更轻松地获取所需信息。 根据微软的介绍,这项连接器功能是可选的,用户可以在设置中选择需要连接的服务。

深层网络通过分层抽象能够学习到更复杂的特征表示,从而提升模型对复杂数据的建模能力
神经网络层数越多效果越好这一观点,在特定条件下成立,其核心逻辑在于深层网络通过分层抽象能够学习到更复杂的特征表示,从而提升模型对复杂数据的建模能力。 图片理论机制:分层抽象与特征表示能力增强特征抽象的层次化神经网络通过堆叠层数实现特征的逐层抽象。 以图像识别为例:底层:学习边缘、纹理等简单特征(如卷积核检测水平/垂直边缘);中层:组合底层特征形成形状、部件(如检测车轮、车窗);高层:整合中层特征构成完整对象(如识别整辆汽车)。

斯坦福医院推出 ChatEHR:让医生用自然语言查询病历,提高医疗效率
在斯坦福健康护理系统,一款名为 ChatEHR 的工具已经投入使用,医生们可以像与 ChatGPT 对话一样,使用自然语言查询患者的医疗记录。 这一创新的工具旨在加速急诊室病历审核、简化患者转诊总结,并综合复杂的病历信息。 图源备注:图片由AI生成,图片授权服务商Midjourney斯坦福健康护理系统的高级副总裁兼首席信息与数字官迈克尔・阿・费弗在 VB Transform 的座谈中表示,早期试点结果显示,临床用户的信息检索速度显著提高,尤其是急诊医生在关键交接时的病历审核时间减少了40%。

机器人视觉语言导航进入R1时代!港大联合上海AI Lab提出全新具身智能框架
你对着家里的机器人说:“去厨房,看看冰箱里还有没有牛奶。 ”它不仅准确走到了厨房,还在移动过程中避开了椅子,转身打开冰箱,并回答你:“还有半瓶。 ”这不是遥远的科幻,而是视觉语言导航技术的下一站。

20个样本,搞定多模态思维链!UCSC重磅开源:边画框,边思考
现有开源多模态推理模型(Multimodal Reasoning Model)生成的推理链几乎都是纯自然语言,缺少对图像信息的显式引用与整合。 让多模态大语言模型(MLLM)既能条理清晰的思考,又能真正将推理过程「落到画面」上,在实现上仍然存在两个难点:1. 全是自然语言的思考内容看似很长,其内容有可能脱离图像信息,不一定能真正「看图说话」;2.

12.1万高难度数学题让模型性能大涨,覆盖FIMO/Putnam等顶级赛事难度,腾讯上海交大出品
12.1万道IMO级难度数学“特训题”,让AI学会像人类一样推导数学证明! “特训”过后,模型定理证明性能大涨,7B模型性能比肩或超越现有的开源模型和Claude3.7等商业模型。 “特训题”为DeepTheorem,是首个基于自然语言的数学定理证明框架与数据集,由腾讯AI Lab与上海交大团队联合推出。

Netflix 推出 GPT 驱动的自然语言搜索功能,仅限 iOS 用户
Netflix 宣布推出一项全新的搜索功能,采用 OpenAI 的 ChatGPT 技术,旨在让用户能够使用自然语言进行内容搜索。 用户可以通过简单的短语,如 “我想看一些搞笑的,但不要太傻” 来寻找适合的影片,而无需再输入具体的标题或关键词。 这一功能目前正在 iOS 设备上进行测试,早期测试已在澳大利亚和新西兰展开。

标点符号成大模型训练神器!KV缓存狂减一半,可处理400万Tokens长序列,来自华为港大等 | 开源
文字中貌似不起眼的标点符号,竟然可以显著加速大模型的训练和推理过程? 来自华为、港大、KAUST和马普所的研究者,就提出了一种新的自然语言建模视角——SepLLM。 起因是团队发现某些看似无意义的分隔符,在注意力得分中占据了不成比例的重要地位。

解锁IDEA新姿势:DeepSeek带你飞
一、引言在科技飞速发展的当下,人工智能(AI)已如潮水般涌入各个领域,编程界自然也不例外。 从早期简单的代码自动补全,到如今能根据自然语言描述生成复杂代码逻辑,AI 在编程领域的进化可谓日新月异。 它正逐步改变着开发者的工作方式,成为提升开发效率的强大助力。

大语言模型的解码策略与关键优化总结
本文系统性地阐述了大型语言模型(Large Language Models, LLMs)中的解码策略技术原理及其实践应用。 通过深入分析各类解码算法的工作机制、性能特征和优化方法,为研究者和工程师提供了全面的技术参考。 主要涵盖贪婪解码、束搜索、采样技术等核心解码方法,以及温度参数、惩罚机制等关键优化手段。
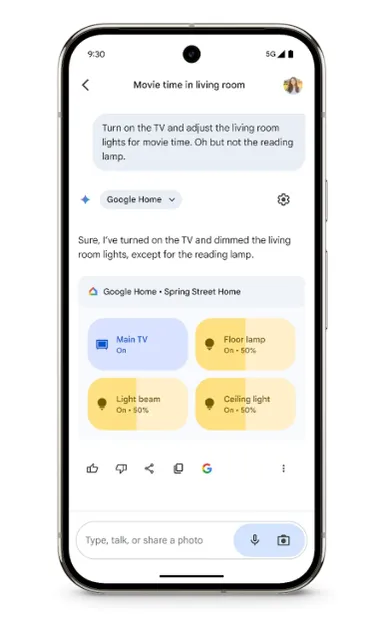
谷歌 Gemini AI 智能家居控制功能全面上线
谷歌近日宣布,其 Gemini 应用程序中的智能家居控制功能已向所有用户推出。 这一更新不仅让用户可以更方便地调整智能灯光、温控、音响等兼容设备,还新增了一些实用的功能,旨在提升用户的智能家居体验。 自去年11月首次预览以来,谷歌一直在不断优化 Gemini 的智能家居控制能力。

ELMo模型可用于训练动态词向量,该模型有哪些优缺点? 与BERT模型之间的区别是什么?|深度学习|大模型
ELMo(Embeddings from Language Models)是一种基于深度学习的动态词向量模型,它通过双向LSTM(长短期记忆网络)来生成词的表示,相较于传统的静态词向量方法,如Word2Vec和GloVe,ELMo能够根据上下文生成不同的词向量。 这使得ELMo能够更好地处理同义词、歧义词以及多义词的上下文依赖关系,从而提升自然语言处理(NLP)任务的表现。 然而,ELMo也存在一些局限性,例如模型训练复杂、计算资源消耗较大以及缺乏对长距离依赖的建模等。

2024 ACL Fellow名单出炉!微软高剑峰等4位华人科学家入选
2024 ACL Fellow的名单正式出炉了! 今年,国际计算语言学协会(ACL)评选了9位来自全球的科学家,其中华人学者占了4席。 他们分别是:微软高剑峰、哈尔滨工业大学(深圳)张民、Meta FAIR实验室Scott Wen-tau Yih、滑铁卢大学Jimmy Lin。

自然语言处理(NLP):开启人机交互新篇章
在数字化时代,我们与智能设备的交互日益频繁,从设置闹钟到获取产品推荐,这些便捷的操作背后,离不开一项关键技术——自然语言处理(Natural Language Processing, NLP)。 NLP作为计算机科学的一个重要分支,正逐步改变着我们与机器的交流方式,使计算机能够更智能地理解和响应人类语言。 本文将深入探讨NLP的基本概念、关键技术、应用场景以及未来发展,带领读者走进这一充满无限可能的领域。

终于把神经网络中的知识蒸馏搞懂了!!!
大家好,我是小寒今天给大家分享神经网络中的一个关键知识点,知识蒸馏知识蒸馏是一种模型压缩方法,用于将大型神经网络(教师模型)中的知识转移到较小的神经网络(学生模型)中。 这一技术能够在保持或接近原始模型性能的情况下,显著减小模型的体积,从而提升推理效率。 知识蒸馏在很多场景中非常有用,尤其是在计算资源有限或需要部署到边缘设备的应用中。

LLM-R:基于RAG和层次化Agent落地案例解析
在这个由智能设备主导的时代,维护工作的重要性愈发凸显,几乎成了生产活动的守护神。 想象一下,当一台精密的机器在深夜突发故障,而维护手册却像天书一样难以理解,这时,交互式电子技术手册(IETMs)就像一束温暖的灯塔,指引着维护人员安全渡过难关。 面对从图形用户界面(GUIs)到自然语言用户界面(LUIs)的转变,以及复杂逻辑关系的梳理,传统的IETMs显得有些力不从心。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉