状态空间模型
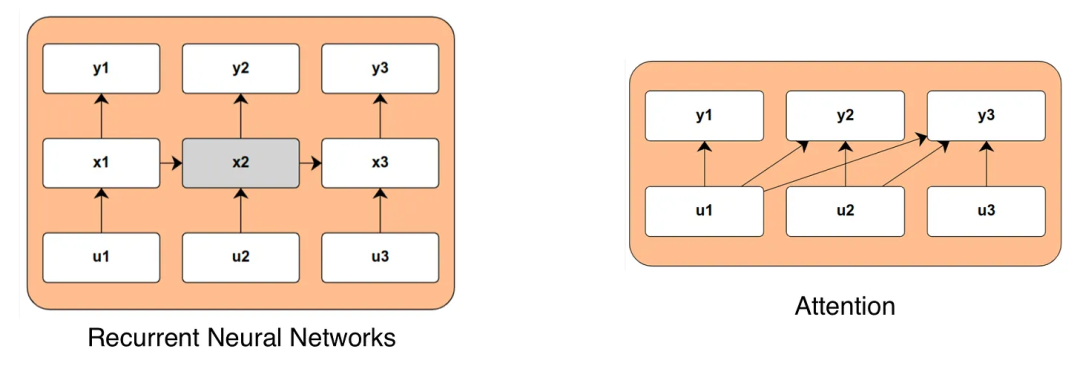
我们还需要Transformer中的注意力吗?
状态空间模型正在兴起,注意力是否已到尽头?最近几周,AI 社区有一个热门话题:用无注意力架构来实现语言建模。简要来说,就是机器学习社区有一个长期研究方向终于取得了实质性的进展,催生出 Mamba 两个强大的新模型:Mamba 和 StripedHyena。它们在很多方面都能比肩人们熟知的强大模型,如 Llama 2 和 Mistral 7B。这个研究方向就是无注意力架构,现在也正有越来越多的研究者和开发者开始更严肃地看待它。近日,机器学习科学家 Nathan Lambert 发布了一篇题为《状态空间 LLM:我们需

MoE与Mamba强强联合,将状态空间模型扩展到数百亿参数
性能与 Mamba 一样,但所需训练步骤数却少 2.2 倍。状态空间模型(SSM)是近来一种备受关注的 Transformer 替代技术,其优势是能在长上下文任务上实现线性时间的推理、并行化训练和强大的性能。而基于选择性 SSM 和硬件感知型设计的 Mamba 更是表现出色,成为了基于注意力的 Transformer 架构的一大有力替代架构。近期也有一些研究者在探索将 SSM 和 Mamba 与其它方法组合起来创造更强大的架构,比如机器之心曾报告过《Mamba 可以替代 Transformer,但它们也能组合起来使
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉