语音

AI涌现人类情感!希腊「乐之神」Orpheus开源,单卡可跑语音流式推理
大语言模型(LLM)还能涌现什么能力? 这次开源模型Orpheus,直接让LLM涌现人类情感! 对此,Canopy Labs的开源开发者Elias表示Orpheus就像人类一样,已经拥有共情能力,能从文本中产生潜在的线索,比如叹息、欢笑和嗤笑。
4/16/2025 9:46:46 AM
新智元

阿里开源R1-Omni,DeepSeek同款RLVR首度结合全模态情感识别,网友:可解释性+多模态学习=下一代AI
首次将DeepSeek同款RLVR应用于全模态LLM,含视频的那种! 眼睛一闭一睁,阿里通义实验室薄列峰团队又开卷了,哦是开源,R1-Omni来了。 同样在杭州,这是在搞什么「开源双feng」(狗头保命)?
3/11/2025 1:47:10 PM
量子位

出门问问发布TicVoice 7.0 支持超自然语音克隆与跨语种生成能力
3月6日,出门问问(Mobvoi)联合香港科技大学、上海交通大学、南洋理工大学、西北工业大学等顶尖学术机构,共同开源新一代语音生成模型Spark-TTS,并重磅推出其商业化高品质TTS引擎——TicVoice7.0。 作为出门问问第七代TTS引擎,TicVoice7.0在语音生成领域实现了重大突破,开启了全新的语音生成范式。 TicVoice7.0的核心优势在于其创新的语音编码方式和建模结构。
3/7/2025 8:50:00 AM
AI在线
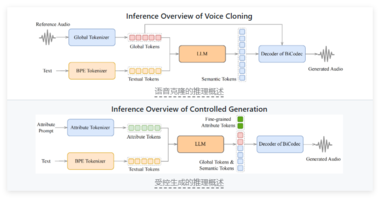
文本转语音系统Spark-TTS:支持零样本语音克隆与细粒度控制
日前,一款名为 Spark-TTS 的先进文本转语音系统引发了 AI 社区的广泛讨论。 根据最新的 X 帖子和相关研究,这款系统以其零样本语音克隆和细粒度语音控制能力脱颖而出,展现了语音合成领域的重大突破。 这款系统充分利用了大型语言模型(LLM)的强大能力,致力于实现高度准确且自然的语音合成,适用于研究和商业领域。
3/6/2025 11:29:00 AM
AI在线
Grok 语音模式全面开放:11 种模式上线,自带字幕成英语学习利器
xAI 公司开发的 AI 助手 Grok 今日宣布,其备受期待的语音模式已正式向所有用户开放。 这一更新不仅带来了11种独特的语音交互模式(包括2种18 限制模式),还新增了语音字幕功能,被用户称为“学习英语的好工具”。 消息在 X 平台上迅速传播,引发了广泛的兴奋与讨论。
3/5/2025 11:00:00 AM
AI在线
播客平台 Podcastle 推出AI文本转语音模型:提供 450 种语音
在快速发展的播客领域,Podcastle 平台近日宣布推出其全新的 AI 文本转语音模型 Asyncflow v1.0。 这个新模型不仅为用户提供了超过450种不同的 AI 语音,还向开发者开放了 API 接口,以便于他们将这一文本转语音功能直接集成到自己的应用程序中。 Podcastle 的创始人 Arto Yeritsyan 表示,公司一直希望能开发一个文本转语音模型,但由于过去高昂的训练成本和数据需求,这一愿望一直未能实现。
3/4/2025 11:19:00 AM
AI在线

Sesame 发布 CSM 语音模型:跨越“恐怖谷”,逼真程度惊艳全球
Sesame 公司最新推出的语音合成模型“Conversational Speech Model”(简称 CSM)近日在 X 平台上引发热议,被誉为“像真人说话一样的语音模型”。 这款模型以其惊艳的自然度和情感表达能力,不仅让用户“已经无法分辨”其与人类的区别,还宣称成功跨越了语音领域的“恐怖谷效应”。 随着演示视频和用户反馈的传播,CSM 正迅速成为 AI 语音技术的新标杆。
3/3/2025 11:37:00 AM
AI在线
Sesame发布超真实的AI语音产品:几乎没有AI味
语音助手逐渐成为我们生活中不可或缺的一部分,而现有的数字语音助手在与用户互动时,往往显得平淡无奇,缺乏情感和人性化的元素。 对此,Sesame 团队正在努力解决这一问题,致力于实现一种全新的 “语音存在” 概念,使得数字助手能够在交流中更真实、被理解和重视。 Sesame 的核心目标是创造一种数字伴侣,不仅仅是处理请求的工具,而是能够进行真实对话的伙伴。
3/3/2025 9:37:00 AM
AI在线

马斯克宣布新版 Grok 应用上线:语音模式体验大幅提升
埃隆·马斯克今日在社交平台 X 上发文,宣布其人工智能公司 xAI 的新版本 Grok 应用正式上线。 这一消息迅速引发科技爱好者和 X 用户的广泛关注。 马斯克特别推荐用户体验全新升级的 Grok 语音模式,称其交互能力显著提升,为用户带来更自然、更智能的对话体验。
2/28/2025 4:24:00 PM
AI在线

语音合成也遵循Scaling Law,太乙真人“原声放送”讲解论文 | 港科大等开源
活久见,太乙真人给讲论文了噻! 咳咳,诸位道友且听我一番唠叨。 老道我闭关数日,所得一篇妙诀,便是此Llasa之法。
2/28/2025 9:30:00 AM
量子位

Hugging Face 推出 FastRTC:实时语音视频应用开发变得轻而易举
AI 初创公司 Hugging Face 宣布推出 FastRTC,这是一个开源的 Python 库,旨在消除开发人员在构建实时音频和视频 AI 应用时面临的重大障碍。 Hugging Face 的 FastRTC 旨在简化 WebRTC 和 Websocket 应用的构建过程。 Freddy Boulton,FastRTC 的创建者之一表示:“在 Python 中,构建实时 WebRTC 和 Websocket 应用非常困难,直到现在才有所改变。
2/27/2025 10:41:00 AM
AI在线

Hume推出革命性文本转语音系统Octave:能理解情感与上下文
在人工智能领域,Hume AI公司最近宣布推出其全新产品Octave,这一系统被称为首个由大型语言模型(LLM)驱动的文本转语音系统。 Octave的创新之处在于其不仅能够生成自然的语音,还能理解上下文中的情感、语调、节奏和韵律,从而为用户提供更为生动和人性化的语音输出。 Hume AI的联合创始人兼首席执行官Alan Cowen在接受媒体采访时表示,Octave模型的设计初衷是为了使文本转语音的生成过程更加自然和灵活。
2/27/2025 9:27:00 AM
AI在线

OpenAI向免费用户推出基于GPT-4o mini的高级语音模式
OpenAI官方宣布,向免费用户推出GPT4o mini驱动的高级语音模式,免费用户也可以每天使用ChatGPT高级语音模式。 据了解免费用户使用 ChatGPT 高级语音模式会有每日使用限制,用户在剩余3分钟使用时间时会收到警告,达到限额后对话将自动结束。 尽管如此,观察表示,ChatGPT Plus 用户可以使用基于 GPT-4o 的完整版高级语音模式,每日限额是免费版的5倍,可以继续在高级语音中使用视频和屏幕共享功能,另外ChatGPT Pro 用户不设每日限额,可享更高的视频和屏幕共享限制。
2/26/2025 2:47:00 PM
AI在线

OpenAI免费开放ChatGPT高级语音聊天模式 基于GPT-4o mini
2月26日,OpenAI公司在X平台发布推文,正式向广大用户宣布,即日起将免费开放ChatGPT的高级语音模式(Advanced Voice Mode)。 据悉,ChatGPT的高级语音模式基于GPT-4o mini模型,通过优化计算效率,在性能方面已经能够媲美完整版的GPT-4o模型。 目前,macOS以及Windows10、Windows11系统的ChatGPT桌面应用程序均已支持高级语音模式,提供了5种语音选择,并支持自定义提示和对话内容回顾功能。
2/26/2025 10:56:00 AM
AI在线

被DeepSeek带火的知识蒸馏,开山之作曾被NeurIPS拒收,Hinton坐镇都没用
DeepSeek带火知识蒸馏,原作者现身爆料:原来一开始就不受待见。 称得上是“蒸馏圣经”、由Hinton、Oriol Vinyals、Jeff Dean三位大佬合写的《Distilling the Knowledge in a Neural Network》,当年被NeurIPS 2014拒收。 如何评价这篇论文的含金量?
2/7/2025 3:10:00 PM
量子位

豆包App更新实时语音通话功能,中文对话断崖式领先,人机难辨!
1月20日,豆包APP更新实时语音通话功能,面向所有用户开放。 该功能基于最新豆包实时语音大模型(Doubao Realtime Voice Model)。 更新后,豆包中文场景的对话能力在语音真实感和“喜怒哀乐”的情绪表现上近乎达到“人机难辨”的AI交互效果,可以模仿不同声线,并且在“逻辑思考”和“情绪感知”上有明显提升。
1/21/2025 9:16:00 AM
新闻助手

推动多语言语音科技迈向新高度:INTERSPEECH 2025 ML-SUPERB 2.0 挑战赛
随着语音技术在各领域应用的迅速扩展,全球语言与口音的多样性成为技术进一步突破的重大挑战。 为了应对这一难题,来自卡内基梅隆大学(CMU)、斯坦福大学(Stanford University)、乔治梅森大学(George Mason University)、台湾大学与芝加哥丰田技术学院(TTIC)的研究团队连手,在即将举行的 INTERSPEECH 2025 国际会议上推出了 ML-SUPERB 2.0 挑战赛(Multilingual SUPERB 2.0 Challenge)。 该挑战旨在推动多语言语音技术迈向新高度,为语音科技的全球化应用奠定坚实基础。
1/7/2025 2:49:00 PM
新闻助手
国产AI之光!TeleAI星辰大模型入选央企十大国之重器评选
近日,国务院国资委新闻中心发起“十大国之重器”年度盘点,从2024年中央企业建设的众多重点项目中精心选出20项既有影响力又有创新力的大国重器,诚邀广大网友评选“年度十大国之重器”。 由中电信人工智能科技有限公司和中国电信人工智能研究院(TeleAI)打造的“全国产化万亿参数星辰大模型发布”光荣入选,成为国产AI的佼佼者,展现了中国电信在人工智能领域的领先地位。 星辰大模型,开启国产AI新时代星辰大模型,是由中国电信自主研发打造的全国产化万亿参数大模型,是国内AI技术的重大突破。
12/25/2024 2:50:00 PM
新闻助手
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI绘画
大模型
机器人
数据
AI新词
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
技术
智能体
Gemini
马斯克
Anthropic
英伟达
图像
AI创作
训练
LLM
论文
代码
算法
苹果
AI for Science
Agent
Claude
腾讯
芯片
Stable Diffusion
蛋白质
开发者
具身智能
xAI
生成式
神经网络
机器学习
3D
人形机器人
AI视频
RAG
大语言模型
研究
百度
Sora
生成
GPU
工具
华为
字节跳动
计算
AGI
大型语言模型
AI设计
搜索
生成式AI
视频生成
DeepMind
特斯拉
场景
AI模型
深度学习
亚马逊
架构
Transformer
MCP
编程
视觉
预测