像素

Meta 发布 Sapiens 视觉模型,让 AI 分析和理解图片 / 视频中人类动作
Meta Reality 实验室最新推出了名为 Sapiens 的 AI 视觉模型,适用于二维姿势预估、身体部位分割、深度估计和表面法线预测 4 种以人为中心的基本视觉任务。这些模型的参数数量各不相同,从 3 亿到 20 亿不等。它们采用视觉转换器架构,任务共享相同的编码器,而每个任务有不同的解码器头。二维姿势预估:这项任务包括检测和定位二维图像中人体的关键点。这些关键点通常与肘、膝和肩等关节相对应,有助于了解人的姿势和动作。身体部位分割:这项任务将图像分割成不同的身体部位,如头部、躯干、手臂和腿部。图像中的每个像

「十亿像素」引领视觉智能技术变革,2022 GigaVision挑战赛圆满落幕
2012 年,深度学习在 ImageNet 图像挑战赛中取得了巨大的突破,被广泛认为是第三次人工智能革命的标志性事件。以此为开端,十多年间,从人脸识别、跟踪到动作识别,围绕各类视觉智能任务的技术都取得了显著的进展,人工智能理论与技术的大变革时代终于到来。
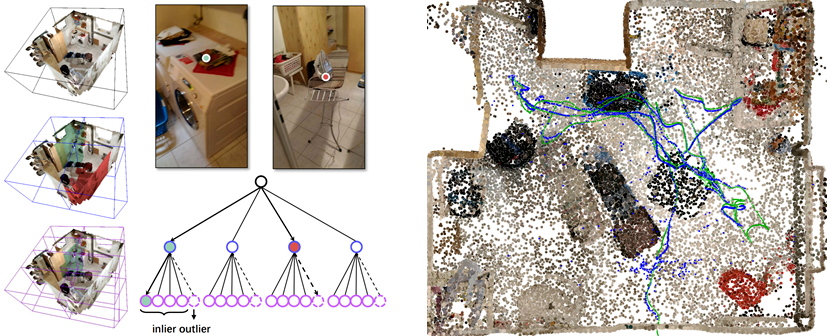
CVPR 2021 Oral | 室内动态场景中的相机重定位
本文是对发表于计算机视觉和模式识别领域的顶级会议 CVPR 2021的 Oral 论文 “Robust Neural Routing Through Space Partitions for Camera Relocalization in Dynamic Indoor Environments”(通过在空间划分中鲁棒的神经路由实现室内动态场景的相机重定位)的解读。
该论文由北京大学陈宝权研究团队与山东大学、北京电影学院、斯坦福大学和 Google Research 合作,针对室内动态变化场景的相机重定位问题,提出在场景空间划分中进行路由的思想,记忆场景静态信息的同时感知场景动态信息,从而实现鲁棒的相机位姿预测。
实验证明,该方法显著提升了动态变化场景中的相机重定位效果。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉