微调
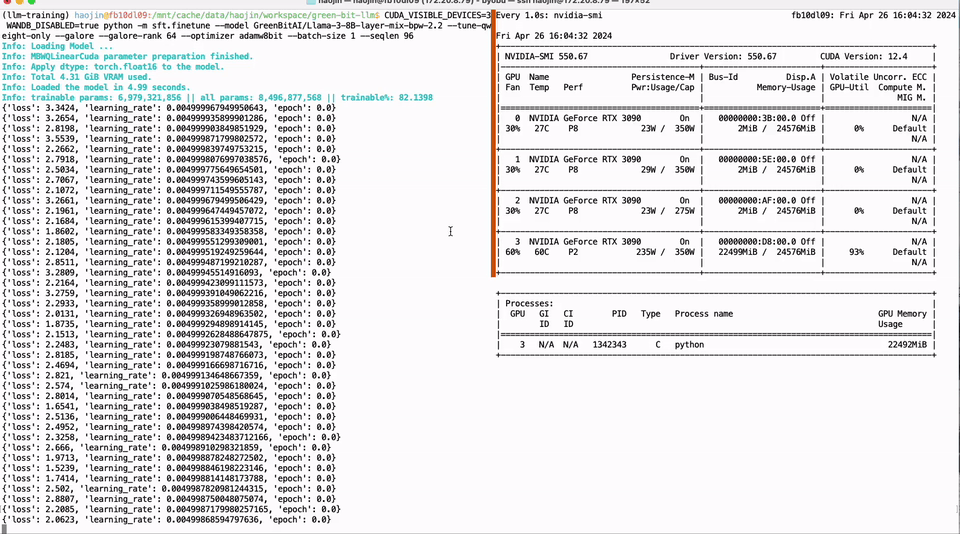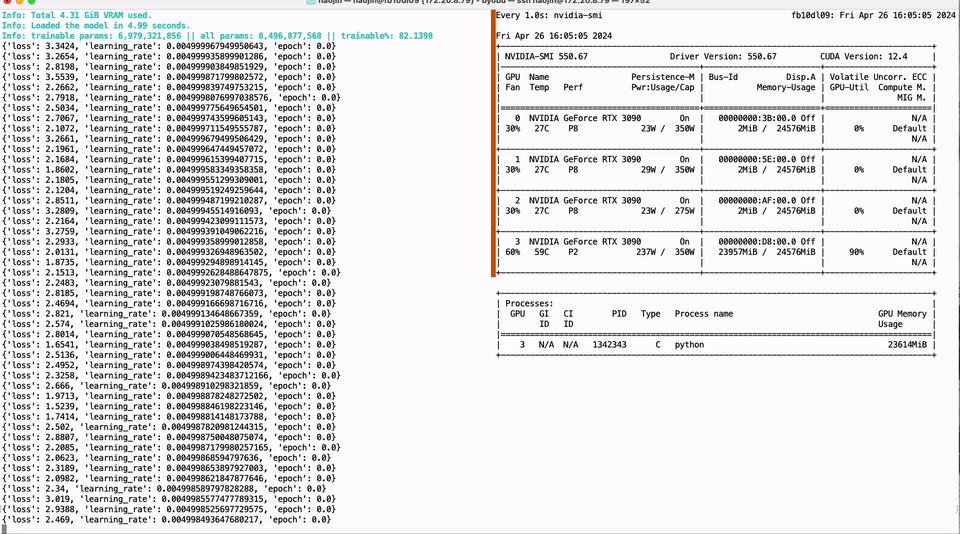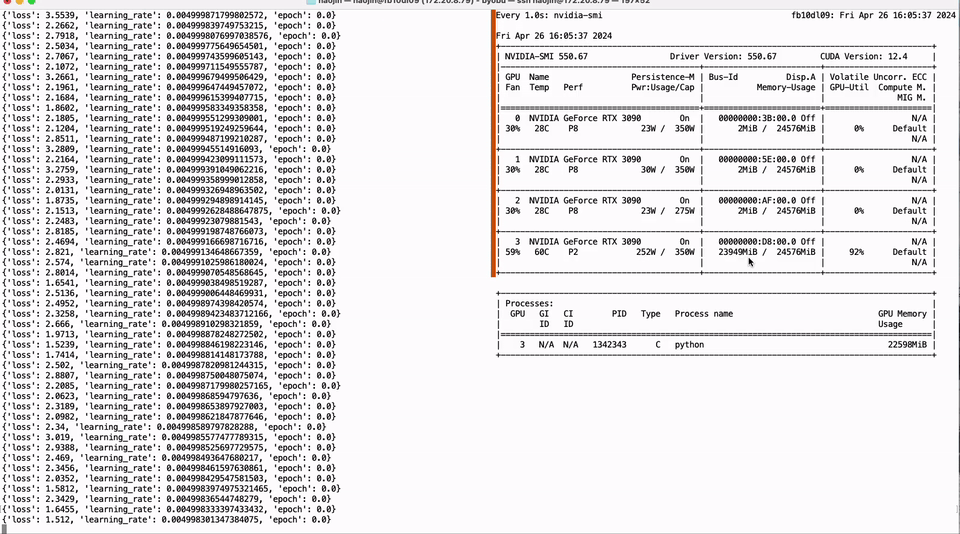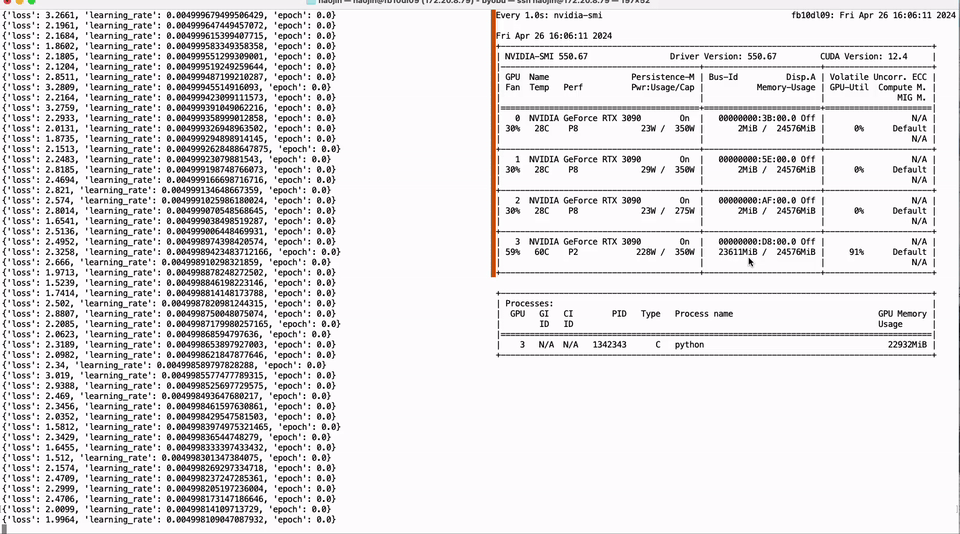
只需单卡RTX 3090,低比特量化训练就能实现LLaMA-3 8B全参微调
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。
投稿邮箱:[email protected];[email protected]

仅用250美元,Hugging Face技术主管手把手教你微调Llama 3
大语言模型的微调一直是说起来容易做起来难的事儿。近日 Hugging Face 技术主管 Philipp Schmid 发表了一篇博客,详细讲解了如何利用 Hugging Face 上的库和 fsdp 以及 Q-Lora 对大模型进行微调。我们知道,Meta 推出的 Llama 3、Mistral AI 推出的 Mistral 和 Mixtral 模型以及 AI21 实验室推出的 Jamba 等开源大语言模型已经成为 OpenAI 的竞争对手。不过,大多数情况下,使用者需要根据自己的数据对这些开源模型进行微调,才能

OpenAI 新动态:改善微调 API,扩展定制模型计划
感谢OpenAI 公司近日发布新闻稿,宣布改善微调(fine-tuning)API,并进一步扩展定制模型计划。IT之家翻译新闻稿中关于微调 API 的相关改进内容如下基于 Epoch 的 Checkpoint Creation在每次训练 epoch(将训练数据集中的所有样本都过一遍(且仅过一遍)的训练过程)过程中,都自动生成一个完整的微调模型检查点,便于减少后续重新训练的需要,尤其是在过拟合(overfitting,指过于紧密或精确地匹配特定数据集,以至于无法良好地拟合其他数据或预测未来的观察结果的现象)的情况下。
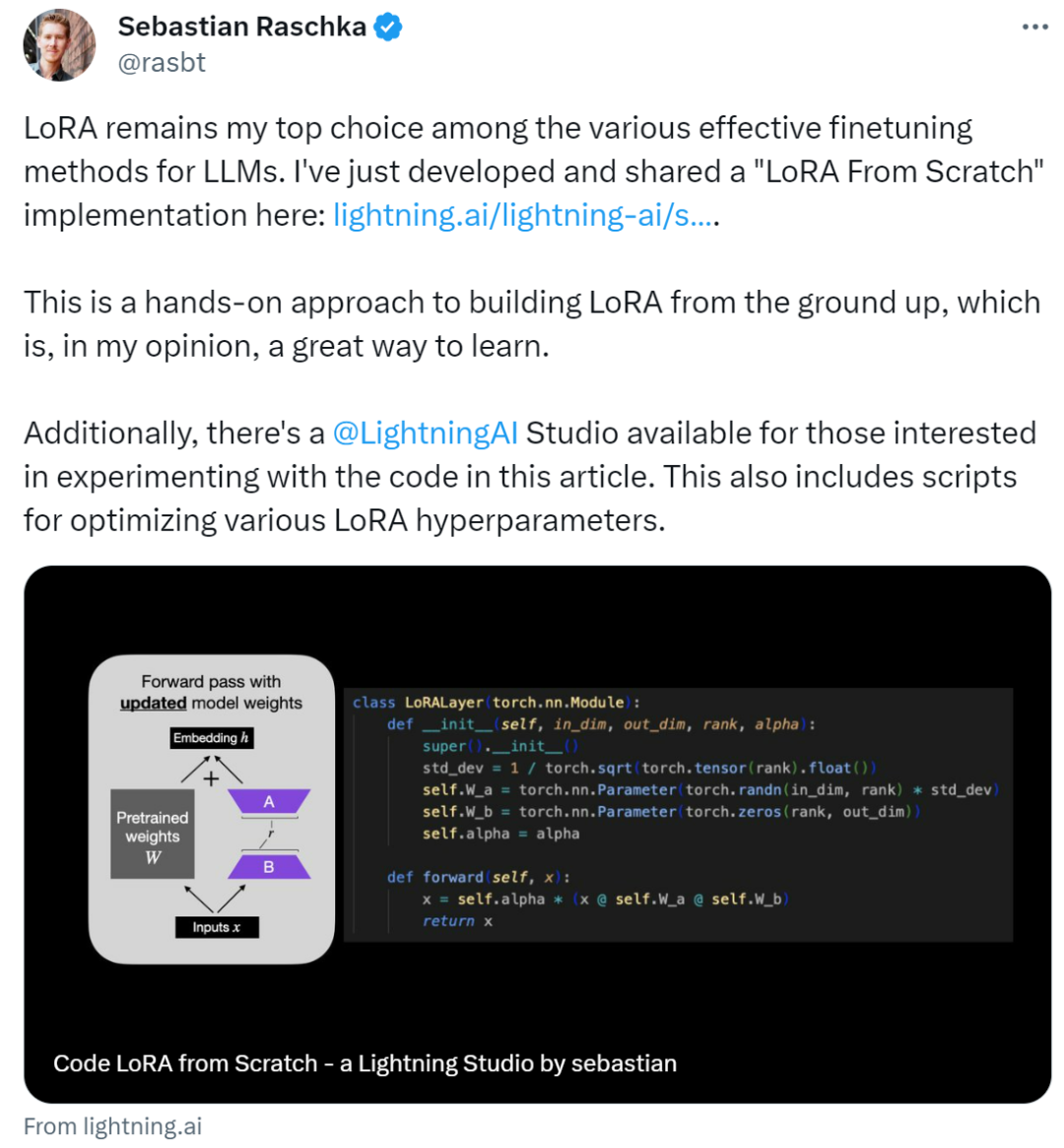
如何从头开始编写LoRA代码,这有一份教程
作者表示:在各种有效的 LLM 微调方法中,LoRA 仍然是他的首选。LoRA(Low-Rank Adaptation)作为一种用于微调 LLM(大语言模型)的流行技术,最初由来自微软的研究人员在论文《 LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS 》中提出。不同于其他技术,LoRA 不是调整神经网络的所有参数,而是专注于更新一小部分低秩矩阵,从而大大减少了训练模型所需的计算量。由于 LoRA 的微调质量与全模型微调相当,很多人将这种方法称之为微调神器。自发布

3000多条数据里选出200条效果反而更好,MiniGPT-4被配置相同的模型超越了
今年四月诞生的多模态大型语言模型 MiniGPT-4 不仅能看图聊天,还能利用手绘草图建网站,可以说是功能强大。而在预训练之后的微调阶段,该模型使用了 3000 多个数据。确实很少,但上海交通大学清源研究院和里海大学的一个联合研究团队认为还可以更少,因为这些数据中大部分质量都不高。他们设计了一个数据选择器,从中选出了 200 个数据,然后训练得到了 InstructionGPT-4 模型,其表现竟优于微调数据更多的 MiniGPT-4!这究竟是如何做到的?
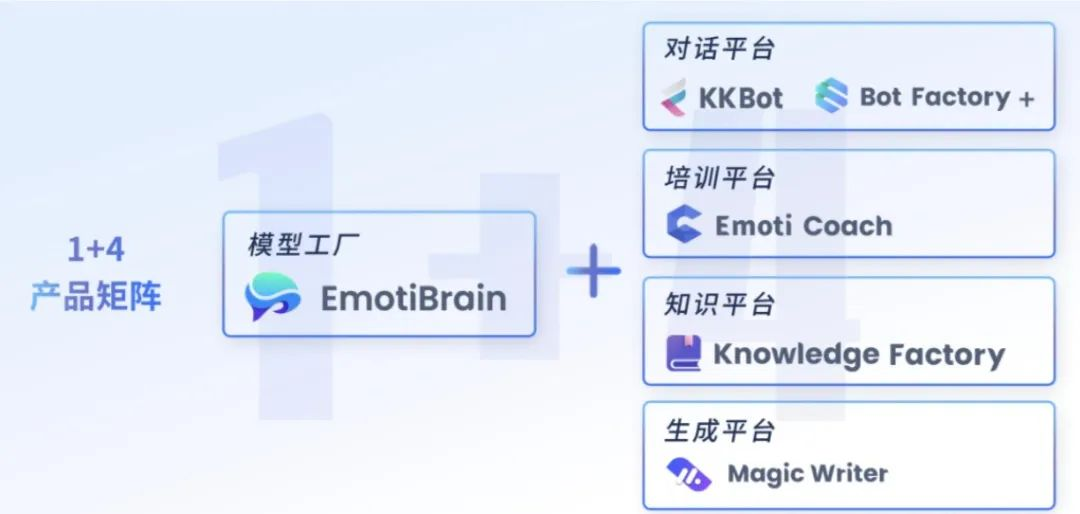
坚持做行业大模型,竹间智能给大模型造了一座「模型工厂」
企业被放在了开往大模型时代列车的驾驶座上。
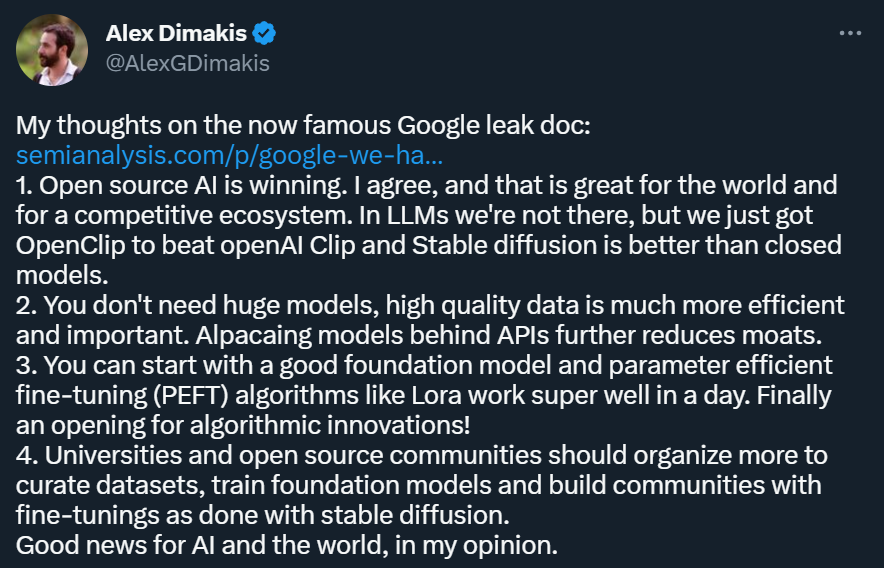
谷歌内部文件泄漏:谷歌、OpenAI都没有护城河,大模型门槛正被开源踏破
「我们没有护城河,OpenAI 也没有。」在最近泄露的一份文件中,一位谷歌内部的研究人员表达了这样的观点。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉