VLM

最新总结,不同抽取任务哪个模型最能打
图片在人工智能的浪潮中,多模态大模型(VLM)正以前所未有的速度改变着我们的世界。 从自然语言处理(NLP)到计算机视觉(CV),从大型语言模型(LLM)到检索增强生成(RAG)和智能体(Agent),AI的边界不断被拓展。 而今天,我们将聚焦于一个关键领域——文档结构化抽取,看看12种顶尖的VLM多模态大模型,谁才是真正的强者!
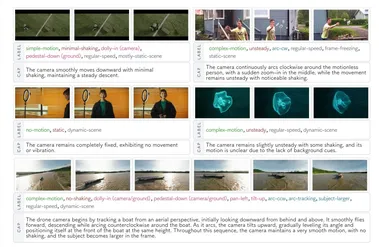
AI连镜头都不会看?别闹了!CameraBench 能直接给你上“电影课”
咱们天天聊 AI 多牛逼,能写诗、能画画、还能跟你唠嗑到天亮。 但你有没有想过,当 AI 看视频的时候,它真的“看懂”了吗?你可能会说:“当然了,都能识别猫猫狗狗、人山人海了!”打住!识别物体是一回事,但理解视频的 “灵魂” —— 也就是 摄像机是怎么动的 —— 那又是另一回事了!想象一下,你看希区柯克的电影,那经典的“滑动变焦”(dolly zoom)带来的眩晕感;或者《侏罗纪公园》里,镜头缓缓抬起(tilt up)又平移(pan right),第一次看到恐龙时的那种敬畏感;甚至是你看爱豆 vlog 时,那跟着爱豆跑的“跟踪镜头”(tracking shot)…… 这些运镜,都在讲故事,都在传递情感!可对 AI 来说,这些微妙的动作语言,之前很大程度上就是个“谜”。 它可能知道画面里有个人在跑,但很难说清摄像机是在跟着跑(tracking),还是在原地转圈(panning),或者是像喝醉了一样在那儿瞎晃(unsteady)。

开源的轻量化VLM-SmolVLM模型架构、数据策略及其衍生物PDF解析模型SmolDocling
缩小视觉编码器的尺寸,能够有效的降低多模态大模型的参数量。 再来看一个整体的工作,从视觉侧和语言模型侧综合考量模型参数量的平衡模式,进一步降低参数量,甚至最小达256M参数量,推理时显存占用1GB。 下面来看看,仅供参考。
Groundlight 开源框架,搞定复杂的视觉推理
一直专注于让AI看懂世界的 Groundlight 研究团队,近日放大招,宣布开源了一套全新的 AI 框架!这套框架旨在攻克视觉领域的一大难题——复杂的视觉推理,让AI不仅能“看图识物”,更能像福尔摩斯一样,从图像中推理出更深层次的信息。 我们都知道,现在的AI在识别猫猫狗狗方面已经炉火纯青,但要让它们理解图片背后的逻辑关系,进行更复杂的推理,就常常“卡壳”。 Groundlight 的研究人员指出,当前的视觉语言模型 (VLM) 在理解图像本身尚且不足的情况下,更难以完成需要深度解读的任务。

使用小型视觉语言模型(VLM)进行物体识别与计数
今天的重点是一个具有无数实际应用的功能:在边缘设备(如智能手机、物联网设备和嵌入式系统)上运行小型视觉语言模型(VLM)。 这些模型在识别和指出物体方面越来越出色。 具体来说,它们在检测制造缺陷、计数可用停车位或发现癌细胞方面表现优异。

最晚明年上半年落地L3:理想端到端自动驾驶,性能大幅提升
最近一段时间,生成式 AI 技术兴起,众多造车新势力都在探索视觉语言模型与世界模型的新方法,端到端的智能驾驶新技术似乎成为了共同的研究方向。上个月,理想汽车发布了端到端 VLM 视觉语言模型 世界模型的第三代自动驾驶技术架构。此架构已推送千人内测,将智能驾驶行为拟人化,提高了 AI 的信息处理效率,增强了对复杂路况的理解和应对能力。李想曾在公开的分享中表示,面对大部分算法难以识别和处理的罕见驾驶环境,VLM(Visual Language Model)即视觉语言模型可以系统地提升自动驾驶的能力,这种方法从理

这些VLM竟都是盲人?GPT-4o、Sonnet-3.5相继败于「视力」测试
四大 VLM,竟都在盲人摸象?让现在最火的 SOTA 模型们(GPT-4o,Gemini-1.5,Sonnet-3,Sonnet-3.5)数一数两条线有几个交点,他们表现会比人类好吗?答案很可能是否定的。自 GPT-4V 推出以来,视觉语言模型 (VLMs) 让大模型的智能程度朝着我们想象中的人工智能水平跃升了一大步。VLMs 既能看懂画面,又能用语言来描述看到的东西,并基于这些理解来执行复杂的任务。比如,给 VLM 模型发去一张餐桌的图片,再发一张菜单的图片,它就能从两张图中分别提取啤酒瓶的数量和菜单上的单价,算

视觉语言模型导论:这篇论文能成为你进军VLM的第一步
近些年,语言建模领域进展非凡。Llama 或 ChatGPT 等许多大型语言模型(LLM)有能力解决多种不同的任务,它们也正在成为越来越常用的工具。这些模型之前基本都局限于文本输入,但现在也正在具备处理视觉输入的能力。如果能将视觉与语言打通,那么势必能造就多种多样的应用 —— 这实际上也正是当前 AI 技术革命的关键方向。即便现在已有不少研究将大型语言模型扩展到了视觉领域,但视觉与语言之间的连接尚未被彻底打通。举些例子,大多数模型都难以理解空间位置关系或计数 —— 这还需要复杂的工程设计并依赖额外的数据标注。许多视

用GPT-4V和人类演示训练机器人:眼睛学会了,手也能跟上
微软提出使用人手运动视频直接教机器人完成任务的新方法,这种方法使用 GPT-4V 分解视频中的动作,结合大语言模型生成对应的行为表述并作为任务列表,训练机器人只需要动动手就能完成。如何将语言 / 视觉输入转换为机器人动作?训练自定义模型的方法已经过时,基于最近大语言模型(LLM)和视觉语言模型(VLM)的技术进展,通过 prompt 工程使用 ChatGPT 或 GPT-4 等通用模型才是时下热门的方法。这种方法绕过了海量数据的收集和对模型的训练过程,展示出了强大的灵活性,而且对不同机器人硬件更具适应性,并增强了系
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉