图灵测试

国内首个,MiniMax 大模型通过人机辩论图灵测试
AI在线 7 月 29 日消息,据央视频今日报道,在 2025 中国 AI 盛典现场,一场人机辩论激烈上演,而围绕辩论的“图灵测试”也顺利通过。 奇葩说辩手陈铭与 MiniMax 大模型辩手展开辩论,现场有超过 30% 的观众被 AI“迷惑”了,根据“图灵测试”规则,测试通过。 AI在线注:图灵测试(Turing test)是英国计算机科学家艾伦・图灵于 1950 年提出的思想实验,这个实验的流程是由一位询问者写下自己的问题,随后将问题发送给在另一个房间中的一个人与一台机器,由询问者根据他们所作的回答来判断哪一个是真人,哪一个是机器,所有测试者都会被单独分开,对话以纯文本形式透过屏幕传输,因此结果不取决于机器的语音能力,这个测试意在探求机器能否模仿出与人类相同或无法区分的智能。

加州大学研究:AI 模型 GPT - 4.5 和 Llama 3.1 - 405B 可通过标准图灵测试
美国加州大学圣地亚哥分校研究显示,GPT-4.5和Llama 3.1-405B在PERSONA模式下通过三方图灵测试,提问者难以区分AI与人类。AI有望在社交场景中替代人类。#人工智能##图灵测试#

AI 在心理治疗领域获认可,ChatGPT 展现超凡同理心
近期,一项研究表明,OpenAI 的 ChatGPT 通过了心理治疗领域的图灵测试,显示出其在提供心理咨询建议时,竟然比人类治疗师更具同理心。 这一研究成果来自科技媒体 The Decoder 的最新报道。 研究团队邀请了830名参与者,要求他们对比 ChatGPT 与人类治疗师的回复。

ChatGPT 的心理治疗能力通过图灵测试 竟优于人类专家!
最近的一项研究显示,受试者在区分 ChatGPT 与人类治疗师的心理治疗反应时,遇到了很大的困难。 研究表明,AI 的回答往往被认为比专业人士的回答更具同理心。 这项研究应用了经典的图灵测试,旨在评估人类能否识别与机器还是与其他人互动。

用「图灵测试」检验AI尤其是大语言模型,真的科学吗?
当前的大型语言模型似乎能够通过一些公开的图灵测试。我们该如何衡量它们是否像人一样聪明呢?在发布后的近两年时间里,ChatGPT 表现出了一些非常类似人类的行为,比如通过律师资格考试。这让一些人怀疑,计算机的智力水平是否正在接近人类。大多数计算机科学家认为,机器的智力水平还不能与人类相提并论,但他们还没有就如何衡量智力或具体衡量什么达成共识。检验机器智能的经典实验是图灵测试,由艾伦・图灵在其 1950 年发表的论文《Computing Machinery and Intelligence》中提出。图灵认为,如果计算机
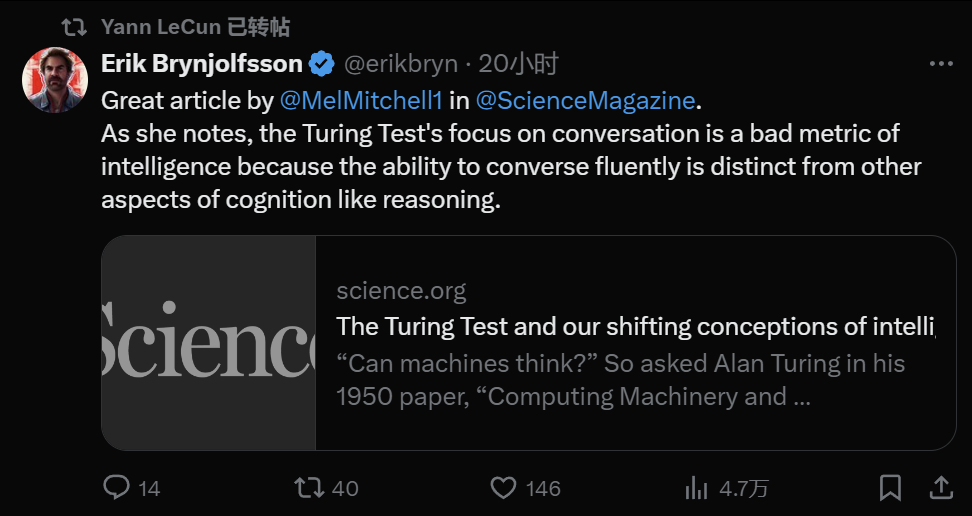
ChatGPT后,人工智能的终极里程碑却倒了
大模型的拟人行为,在让我们产生恐怖谷效应。「图灵测试是一个糟糕的测试标准,因为对话能力和推理完全是两码事。」最近几天,AI 圈里一个新的观点正在流行。如今已是生成式 AI 时代,我们评价智能的标准该变了。「机器能思考吗?」这是艾伦・图灵在他 1950 年的论文《计算机器与智能》中提出的问题。图灵很快指出,鉴于定义「思考」的难度,这个问题「毫无意义,不值得讨论」。正如哲学辩论中常见的做法,他建议用另一个问题代替它。图灵设想了一个「模仿游戏」,在这个游戏中,一位人类评判员分别与一台计算机和一名人类(陪衬者)对话,双方都

GPT-4能「伪装」成人类吗?图灵测试结果出炉
纯文本对话,安能辩我是 AI?在测试 AI 时,图灵测试是一个饱受争议但也久负盛名的评估方法,因此总会有研究者不畏繁琐,对新兴的语言模型进行图灵测试。近日,对 GPT-4 的图灵测试结果新鲜出炉了。 此图由AI生成「机器能够思考吗?」为了解答这个问题,图灵设计了一个能间接提供答案的模仿游戏。该游戏的最初设计涉及到两位见证者(witness)和一位审问者(interrogator)。两位见证者一个是人类,另一个是人工智能;他们的目标是通过一个纯文本的交互
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉