TACO

直面VLA的「阿喀琉斯之踵」:TeleAI用「反探索」提升具身推理稳定性
在机器人具身智能领域,视觉 - 语言 - 动作(Vision-Language-Action, VLA)模型正以惊人的速度发展。 从 RT-1、Octo 到最新的 π0、GR00T N1,这些集成了大规模视觉语言模型与机器人控制的系统展现出前所未有的泛化能力。 然而,一个被长期忽视的问题正阻碍着 VLA 模型从实验室走向真实世界 —— 推理阶段的不稳定性。
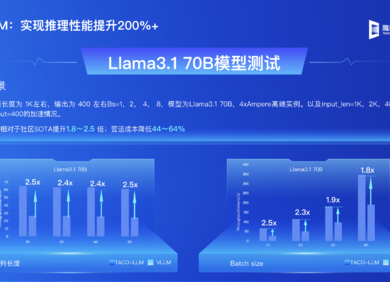
易用性对齐 vLLM,推理效率提升超200%,这款国产加速框架什么来头?
一、行业背景2022 年 10 月,ChatGPT 的问世引爆了以大语言模型为代表的的 AI 浪潮,全球科技企业纷纷加入大语言模型的军备竞赛,大语言模型的数量、参数规模及计算需求呈指数级提升。大语言模型(Large Language Model,简称 LLM 大模型)指使用大量文本数据训练的深度学习模型,可以生成自然语言文本或理解语言文本的含义。大模型通常包含百亿至万亿个参数,训练时需要处理数万亿个 Token,这对显卡等算力提出了极高的要求,也带来了能源消耗的激增。据斯坦福人工智能研究所发布的《2023 年 AI
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉