SpatialLM
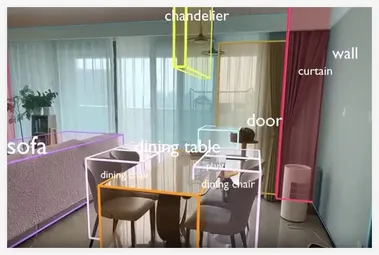
3D视觉大模型SpatialLM开源,实时识别场景内容
在人工智能领域,3D视觉与空间理解技术正成为推动具身智能、自主导航及虚拟现实等应用的关键。 2025年3月,杭州群核科技在GTC2025全球大会上宣布正式开源其自主研发的3D视觉大语言模型 SpatialLM,引发业界广泛关注。 这一模型以其强大的空间认知能力和低成本的数据处理方式,为机器人训练、建筑设计及AR/VR等领域带来了革命性突破。

杭州六小龙开源新模型SpatialLM,助力机器人瞬间理解 3D 世界!
最近,杭州的科技公司群核科技再次引起了行业关注,因其开源的空间理解模型 SpatialLM 被谷歌在一篇论文中点名感谢。 这个模型的创新之处在于,它能让机器人通过一段普通的视频理解物理世界的几何关系,标志着机器人训练领域的一次重大突破。 SpatialLM 的核心功能是将手机拍摄的视频转化为三维空间布局信息。
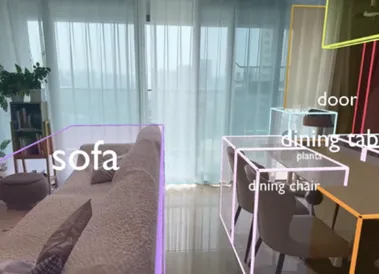
1段视频=亿万虚拟场景,当真实世界秒变机器人训练场
3月19日,群核科技在GTC2025全球大会上宣布开源空间理解模型SpatialLM,这是一个基于大语言模型的3D场景语义生成框架。 它突破了传统大语言模型对物理世界几何与空间关系的理解局限,赋予机器类似人类的空间认知和解析能力。 这相当于为具身智能领域提供了一个基础的空间理解训练框架,企业可以针对特定场景对SpatialLM模型微调,降低具身智能训练门槛。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉