数据集

五部门:加快构建国资央企大数据体系,支持企业开发高质量数据集
国家数据局、中央网信办、工业和信息化部、公安部、国务院国资委 12 月 25 日发布《关于促进企业数据资源开发利用的意见》。

麻省理工研究人员提高机器学习模型准确性
机器学习(ML)有可能通过利用大量数据进行预测洞察来改变医疗决策。 然而,当这些模型在不能充分代表所有人口群体的数据集上进行训练时,就会出现一个严重挑战。 预测疾病患者治疗计划的模型可以在主要包含男性患者的数据集上进行训练。

LANL将中子星并合用于人工智能训练模型
美国洛斯阿拉莫斯国家实验室(LANL)开发的中子星并合模拟正在为Polymathic AI合作项目做出重要贡献,该项目正在训练人工智能模型,以帮助推动看似不同领域的科学发现。 这些模拟准确地跟踪了宇宙中一些最具活力的事件的后果,为基础模型数据集提供了独特的代码,可以帮助训练人工智能模型,使其能够做出与天体物理学、生物学、声学、化学、流体动力学等领域相关的预测。 中子星并合是指两个中子星互相绕转,释放引力波,轨道能量损失,最终在剧烈碰撞、释放引力波暴之后合二为一。

终于把机器学习中的交叉验证搞懂了!!
交叉验证是一种评估机器学习模型性能的方法,用于衡量机器学习模型的泛化能力(即在未见数据上的表现)。 它通过将数据集分成多个部分,交替使用不同的部分作为训练集和测试集,从而充分利用数据、避免过拟合或欠拟合,并更准确地评估模型的泛化能力。 核心思想数据划分:将数据集划分为训练集和测试集。

全自动组装家具! 斯坦福发布IKEA Video Manuals数据集:首次实现「组装指令」真实场景4D对齐
随着人工智能技术的快速发展,让机器理解并执行复杂的空间任务成为一个重要研究方向。 在复杂的3D结构组装中,理解和执行说明书是一个多层次的挑战:从高层的任务规划,到中层的视觉对应,再到底层的动作执行,每一步都需要精确的空间理解能力。 斯坦福Vision Lab最新推出的IKEA Video Manuals数据集,首次实现了组装指令在真实场景中的4D对齐,为研究这一复杂问题提供了重要基准。

为大模型提供全新科学复杂问答基准与测评体系,UNSW、阿贡、芝加哥大学等多家机构联合推出SciQAG框架
编辑 | ScienceAI问答(QA)数据集在推动自然语言处理(NLP)研究发挥着至关重要的作用。高质量QA数据集不仅可以用于微调模型,也可以有效评估大语言模型(LLM)的能力,尤其是针对科学知识的理解和推理能力。尽管当前已有许多科学QA数据集,涵盖了医学、化学、生物等领域,但这些数据集仍存在一些不足。其一,数据形式较为单一,大多数为多项选择题(multiple-choice questions),它们易于进行评估,但限制了模型的答案选择范围,无法充分测试模型的科学问题解答能力。相比之下,开放式问答(openQA
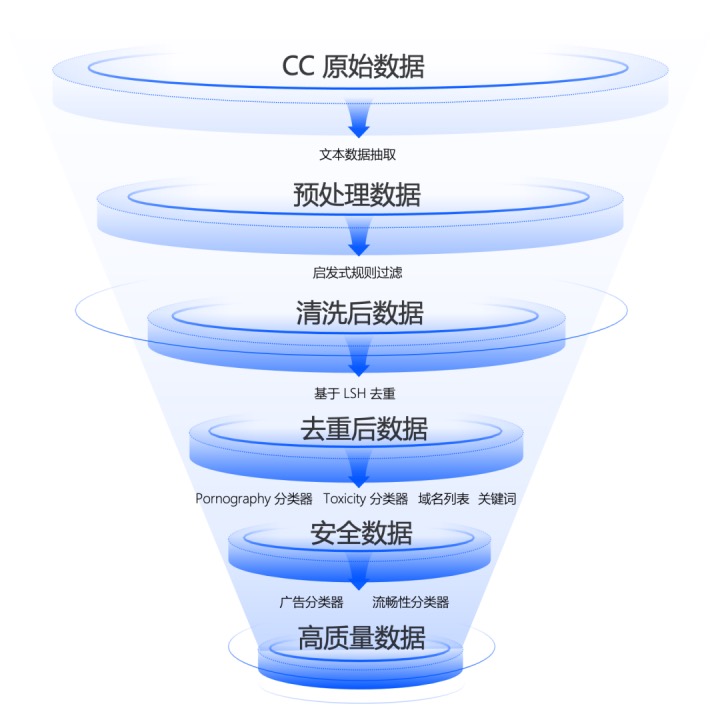
上海AI实验室开源发布高质量语料“万卷CC”
近日,上海人工智能实验室(上海AI实验室)发布新一代高质量大模型预训练语料“万卷CC”(WanJuan-CC),首批开源的语料覆盖过去十年互联网上的公开内容,包含1千亿字符(100B token),约400GB的高质量英文数据。 作为“大模型语料数据联盟”今年首发的开源语料,WanJuan-CC将为学界和业界提供大规模、高质量的数据支撑,助力构建更智能可靠的AI大模型。 预训练数据的质量对大模型整体性能至关重要。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉