视频理解
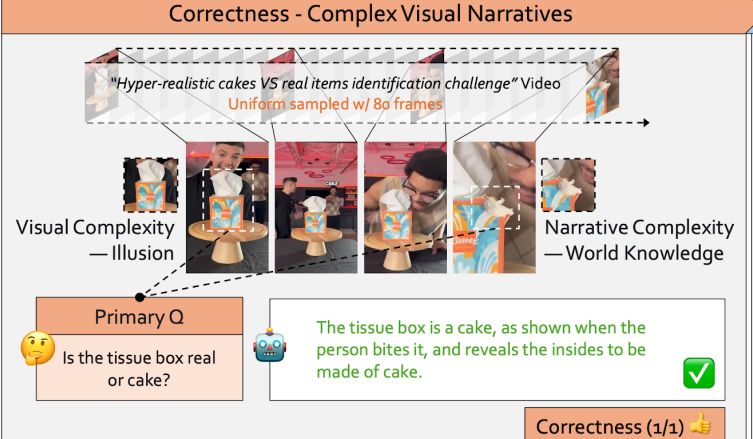
大模型无法真正理解视频,GPT-4o正确率仅36%,南洋理工大团队提出新基准
视频大型语言模型(Video LLMs)的发展日新月异,它们似乎能够精准描述视频内容、准确的回答相关问题,展现出足以乱真的人类级理解力。 但有一个非常本质的问题始终萦绕着研究者的心头:这些模型是真的“理解”了视频,还是仅仅在进行一种高级的“模式匹配”? 为了解决上述问题,来自南洋理工大学S-Lab的研究者们提出了一个全新的、极具挑战性的基准测试——Video Thinking Test(简称Video-TT)。
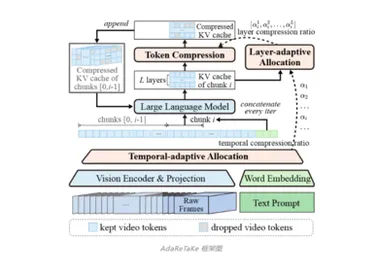
多榜单登顶!华为 & 哈工深团队提出 AdaReTaKe,突破长视频理解极限
第一作者为哈尔滨工业大学(深圳)博士生王霄和华为大模型研究员佀庆一,该工作完成于王霄在华为实习期间。 王霄的研究方向为多模态视频理解和生成,佀庆一的研究方向为多模态理解、LLM post-training和高效推理。 随着视频内容的重要性日益提升,如何处理理解长视频成为多模态大模型面临的关键挑战。
PVUW视频分割Workshop@CVPR 2025 | 征稿!比赛!
第四届真实世界下的像素级视频理解挑战赛(The 4th PVUW challenge)主页/Call for Paper::复杂场景视频目标分割挑战赛(MOSE Challenge):参赛、数据集下载::基于动作描述的指向性视频分割挑战赛(MeViS Challenge):参赛、数据集下载: 真实世界下的像素级视频理解(Pixel-level Video Understanding in the Wild, PVUW)挑战赛将于 CVPR 2025 期间在美国田纳西州纳什维尔的 Music City Center 举办。 像素级场景理解是计算机视觉中的核心问题之一,旨在识别图像中每个像素的类别、掩码和语义。 然而,现实世界是动态的,基于视频的,而非静态的图像状态,因此学习进行视频分割对于实际应用来说更为合理和实用。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉