深度强化学习
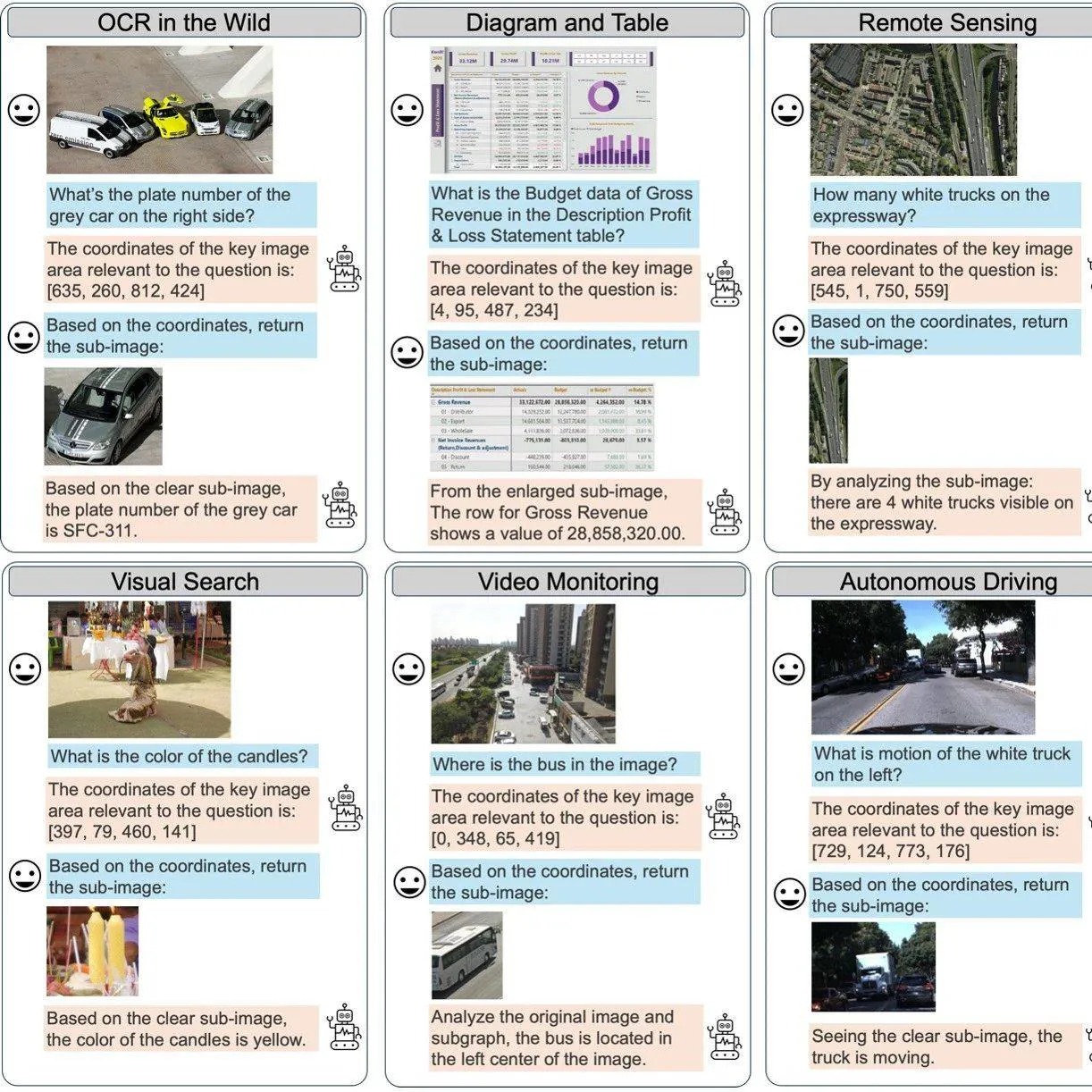
突破高分辨率图像推理瓶颈,复旦联合南洋理工提出基于视觉Grounding的多轮强化学习框架MGPO
本文的主要作者来自复旦大学和南洋理工大学 S-Lab,研究方向聚焦于视觉推理与强化学习优化。 先进的多模态大模型(Large Multi-Modal Models, LMMs)通常基于大语言模型(Large Language Models, LLMs)结合原生分辨率视觉 Transformer(NaViT)构建。 然而,这类模型在处理高分辨率图像时面临瓶颈:高分辨率图像会转化为海量视觉 Token,其中大部分与任务无关,既增加了计算负担,也干扰了模型对关键信息的捕捉。

控制成本降低150%,用于微型反应堆的强化学习模型
编辑丨@在能源危机的当下,核能,或者说,微型核反应堆(后称核微反应堆)凭借规模化优势,成为了当下可再生能源的一大重要供应来源。 通常来说,核微反应堆的经济可行性取决于通过自主控制技术降低成本,尤其是这些反应堆与其他能源系统协同运行的时候。 密歇根大学研究人员领导了一项研究,探讨了深度强化学习(RL)模型在微反应器实时鼓控制中,特别是在负荷跟随场景中的性能。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉