权重
大模型时代还不理解自注意力?这篇文章教你从头写代码实现
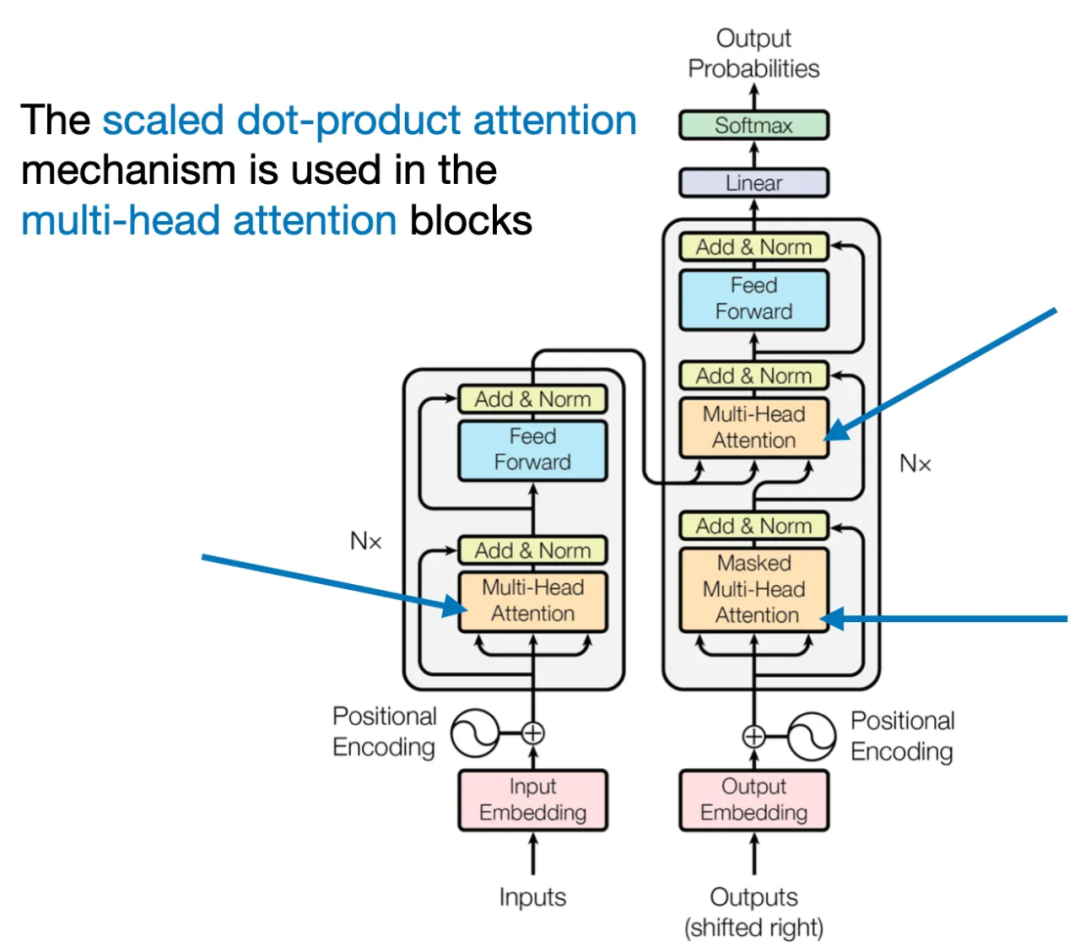
自注意力是 LLM 的一大核心组件。对大模型及相关应用开发者来说,理解自注意力非常重要。近日,Ahead of AI 杂志运营者、机器学习和 AI 研究者 Sebastian Raschka 发布了一篇文章,介绍并用代码从头实现了 LLM 中的自注意力、多头注意力、交叉注意力和因果注意力。太长不看版这篇文章将介绍 Transformer 架构以及 GPT-4 和 Llama 等大型语言模型(LLM)中使用的自注意力机制。自注意力等相关机制是 LLM 的核心组件,因此如果想要理解 LLM,就需要理解它们。不仅如此,这

S-LoRA:一个GPU运行数千大模型成为可能
一般来说,大语言模型的部署都会采用「预训练 — 然后微调」的模式。但是,当针对众多任务(如个性化助手)对 base 模型进行微调时,训练和服务成本会变得非常高昂。低秩适配(LowRank Adaptation,LoRA)是一种参数效率高的微调方法,通常用于将 base 模型适配到多种任务中,从而产生了大量从一个 base 模型衍生出来的 LoRA 适配程序。这种模式为服务过程中的批量推理提供了大量机会。LoRA 的研究表明了一点,只对适配器权重进行微调,就能获得与全权重微调相当的性能。虽然这种方法可以实现单个适配器
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉