普林斯顿大学

Mamba作者团队提出SonicMoE:一个Token舍入,让MoE训练速度提升近2倍
混合专家(MoE)模型已成为在不显著增加计算成本的情况下,实现语言模型规模化扩展的事实标准架构。 近期 MoE 模型展现出明显的高专家粒度(更小的专家中间层维度)和高稀疏性(在专家总数增加的情况下保持激活专家数不变)的趋势,这提升了单位 FLOPs 的模型质量。 这一趋势在近期的开源模型中表现尤为明显,例如 DeepSeek V3、Kimi K2 以及 Qwen3 MoE 等,它们均采用了更细粒度的专家设计(更小的中间层维度)和更高的稀疏度,在保持激活参数量不变的同时大幅增加了总参数量。

北大校友、华人学者金驰新身份——普林斯顿大学终身副教授
今天,华人学者金驰(Chi Jin)宣布他在普林斯顿晋升为终身副教授。 金驰于 2019 年加入普林斯顿大学电气与计算机工程系,担任助理教授。 在普林斯顿的 6 年任期内,他在 AI 领域的学术影响力迅速提升。

DenseNet共一作者刘壮官宣新去向,将任普林斯顿大学助理教授
「还离这世界上最棒的地儿不远。」最新消息,DenseNet 作者之一刘壮将于 2025 年 9 月加盟普林斯顿大学,担任计算机科学系助理教授一职。刘壮主导了 DenseNet 和 ConvNeXt 的开发,这两款模型如今已成为深度学习和计算机视觉领域最主流的神经网络架构之一。
Nat. Mach. Intell.|设计超高效疫苗,普林斯顿团队开发首个解码mRNA序列大模型
图来自网络编辑 | ScienceAI普林斯顿王梦迪团队迎来了一项具有划时代意义的突破,该团队开发了世界首个解码mRNA非翻译区域序列的大模型,用于准确预测从mRNA到蛋白质的转录功能,及设计新序列用于mRNA疫苗。该研究论文的题目是「A 5’ UTR Language Model for Decoding Untranslated Regions of mRNA and Function Predictions」,已被《Nature Machine Intelligence》接收。这篇论文意味着大语言模型可以用于
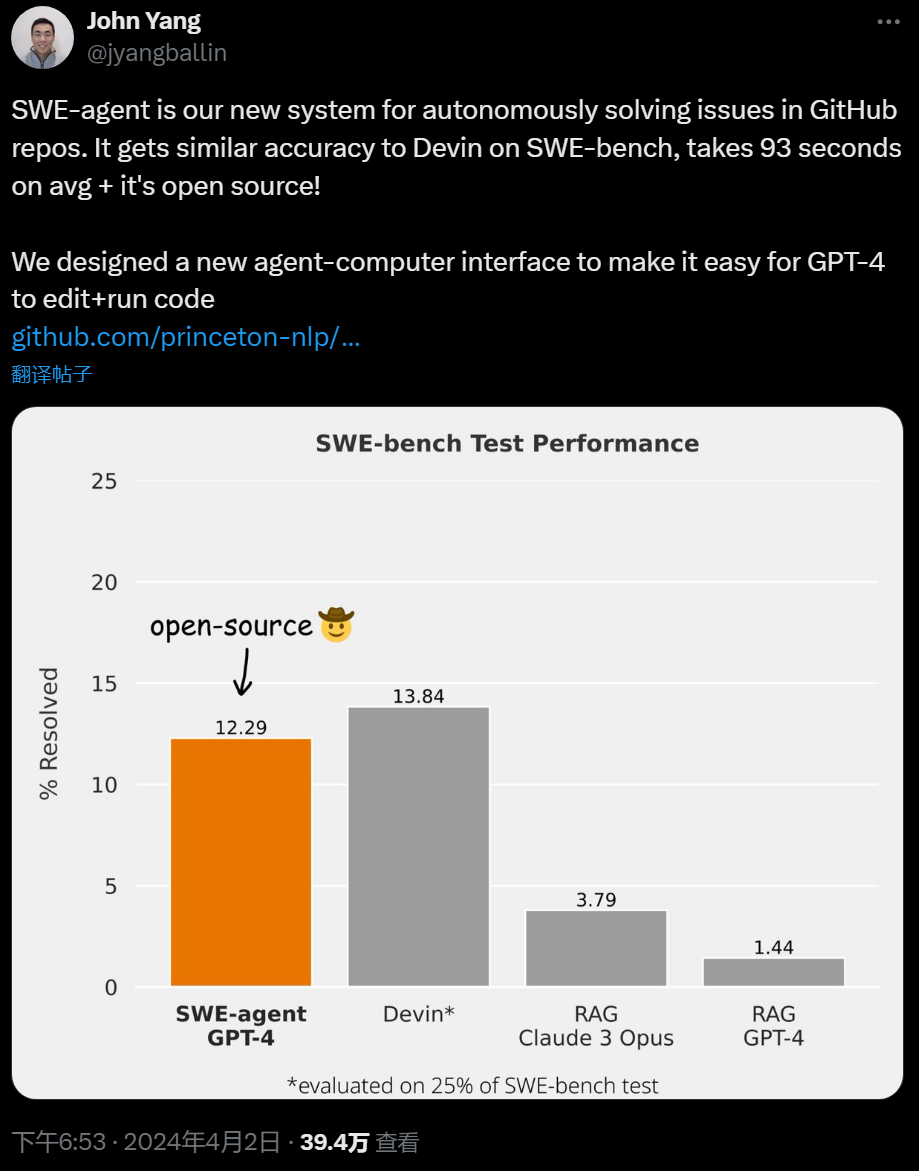
开源版AI程序员来了:GPT-4加持,能力比肩Devin,一天1.4k Star
不到 24 小时,Star 量突破 1400。最近,有很多人在为 AI 代替自己的工作而担忧。上个月火遍 AI 圈的「首位 AI 程序员」Devin,利用大模型能力已经掌握了全栈技能,仅需要人类给出自然语言指令,就可以自动完成复杂的代码任务。Devin 展示的能力非常惊艳,不过这款工具出自走闭源路线的创业公司,现在只有一小部分获得了内测名额的人才能使用。本周二,来自普林斯顿大学 NLP 组的研究人员放出了 SWE-agent —— 一个开源版 AI 程序员,不到一天就获得了上千的 GitHub Star 量。SWE

普林斯顿博士生高天宇指令微调进展速览:数据、算法和评估
自 ChatGPT 等大型语言模型推出以来,为了提升模型效果,各种指令微调方法陆续被提出。本文中,普林斯顿博士生、陈丹琦学生高天宇汇总了指令微调领域的进展,包括数据、算法和评估等。图源:(LLM)很强大,但要想真正帮助我们处理各种日常和工作任务,指令微调就必不可少了。近日,普林斯顿大学博士生高天宇在自己的博客上总结了指令微调研究方向的近期进展并介绍了其团队的一项近期研究成果。具有十亿级参数且使用万亿级 token 训练的大型语言模型(LLM)非常强大,直接就能用于解决大量不同的任务。但是,要用于真实世界应用以及作为
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉