MoA

告别“单打独斗”!AI 协作新范式 MoA,如何集结大模型“梦之队”?
大模型浪潮下,你的 AI 应用遇到瓶颈了吗? 当 GPT、Claude、文心一言等各类强大模型如繁星般涌现,我们惊喜于它们令人惊叹的能力。 然而,在实际落地中,我们常常发现,即使是最顶尖的单一模型,也难以完美应对所有复杂场景的需求。
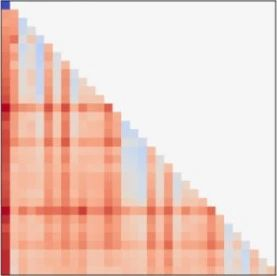
无问芯穹提出混合稀疏注意力方案MoA,加速长文本生成,实现最高8倍吞吐率提升
随着大语言模型在长文本场景下的需求不断涌现,其核心的注意力机制(Attention Mechanism)也获得了非常多的关注。 注意力机制会计算一定跨度内输入文本(令牌,Token)之间的交互,从而实现对上下文的理解。 随着应用的发展,高效处理更长输入的需求也随之增长 [1][2],这带来了计算代价的挑战:注意力高昂的计算成本和不断增长的键值缓存(KV-Cache)代价。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉