大模型浪潮下,你的 AI 应用遇到瓶颈了吗?
当 GPT、Claude、文心一言等各类强大模型如繁星般涌现,我们惊喜于它们令人惊叹的能力。然而,在实际落地中,我们常常发现,即使是最顶尖的单一模型,也难以完美应对所有复杂场景的需求。
为什么呢?因为现实世界的任务往往是多模态、跨领域的。解决一个问题可能既需要强大的逻辑推理,又需要丰富的知识储备,甚至还需要调用外部工具或API。让一个模型包揽一切,就像要求一位数学家同时成为诗人、程序员和历史学家一样,效率和效果都难以保证。
那么,未来的方向在哪里?答案或许在于协作。
不同于让模型内部的模块分工(比如 MoE),我们正在见证一种更灵活、更强大的协作模式崛起:让多个独立的、各有所长的大模型或 AI Agent 组成一个“梦之队”,共同解决难题。
今天,我们要聚焦的,就是这一前沿领域的一个重要探索——混合 Agent(Mixture of Agents),简称 MoA。它不再是模型内部的“分身”,而是系统层面的“集结号”,让不同的强大模型为了同一个目标而协同作战!
你可能听说过 MoE (Mixture of Experts),它是一种提高模型效率和容量的内部技术,像是模型自己搭建了一个内部“专家团”,根据任务把计算分配给不同的内部子网络。
而 MoA (Mixture of Agents) 则是一种更高维度的协作。它不是在模型内部做文章,而是把多个已经训练好的独立大模型(就像一个个具备特定技能的“智能体”Agent)拉到一个协作框架里。
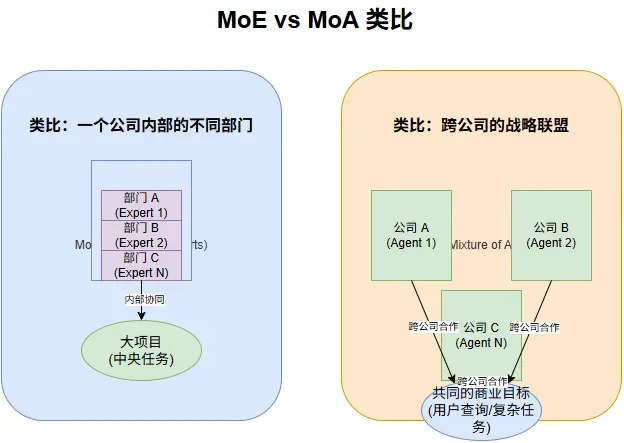
你可以把 MoE 理解为一个公司内部的不同部门协同完成一个大项目;而 MoA 更像是一个跨公司的战略联盟,每个公司(Agent)都有自己的核心优势和技术栈,为了一个共同的商业目标(用户查询/复杂任务)而紧密合作。
在 MoA 框架下,当一个复杂任务来临时,它不是直接扔给一个“全能选手”。相反,它会被分发给联盟中的多个“智能体”。
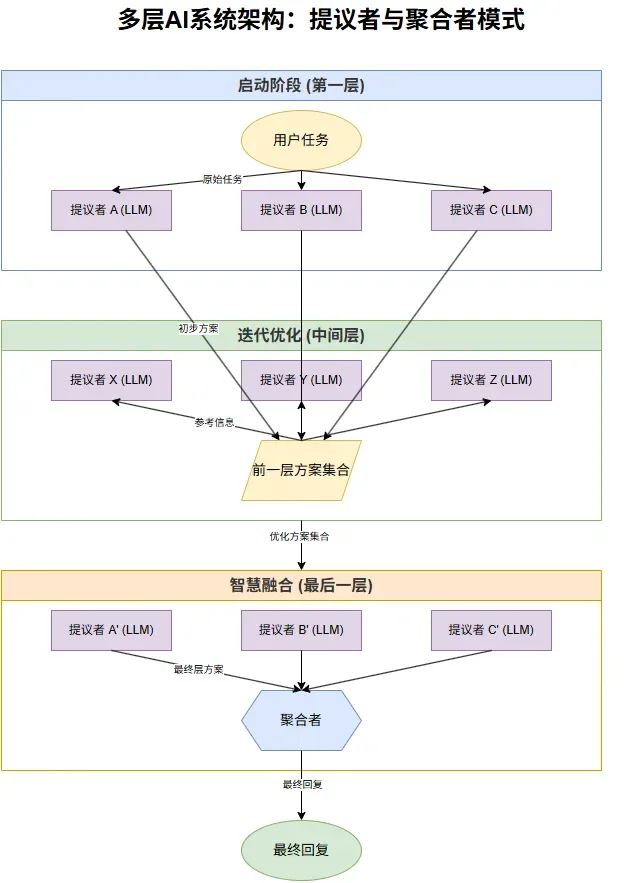
MoA 系统通常采用一种巧妙的分层结构,核心是两种角色:提议者 (Proposers) 和 聚合者 (Aggregators)。
启动阶段(第一层)
收到用户任务后,系统会把任务发给第一层的多个“提议者”(它们是不同的、独立的 LLM)。这些提议者就像接到同一个咨询需求的多个专家,各自独立思考并提出自己的初步“方案”。
迭代优化(中间层)
接下来,前一层所有提议者的“方案”会被收集起来,作为新的参考信息,传递给下一层的提议者。这些下一层的提议者在参考了前人的智慧结晶后,再生成自己的、可能更精进的“方案”。这个过程可以重复多次,形成多层结构。
智慧融合(最后一层与聚合)
当达到最后一层时,所有提议者生成的“方案”会被提交给一位特殊的成员——“聚合者”。聚合者就像一位经验丰富的总编辑或项目经理,它会审阅所有提交的方案,从中吸收精华、整合信息,最终形成一个结构完整、内容丰富、质量最高的最终回复呈现给用户。
MoA 的强大之处在于,它不是简单地从多个回复中“挑一个最好的”,而是通过聚合者的综合能力,将不同提议者在不同侧面的优势整合起来,形成一个超越任何单个提议者能力的答案。
而且,这个协作框架是基于提示词(Prompt-based)实现的!这意味着你不需要去修改或微调底层的 LLM,只需设计好如何组织和传递信息给它们即可。如果未来出现了更强的模型,你可以轻松地将其加入这个“智能体联盟”中,即插即用,大大提高了系统的灵活性和可升级性。
MoA 在多个公开基准测试中展现出了令人印象深刻的性能。在 AlpacaEval 2.0 和 MT-Bench 这类考验模型通用对话能力的榜单上,采用 MoA 结构的系统,通过汇聚多个顶尖 LLM 的智慧,在某些配置下甚至超越了当时最先进的单一模型!
特别是在 FLASK 这样的细粒度评估数据集上,MoA 在正确性、信息完整度、问题理解深度等多个关键维度上表现出色,证明了“集思广益”在提升回复质量方面的有效性。
对比简单的“选优”策略(比如只从多个提议者中挑一个最佳回复),MoA 的“融合”策略被证明能带来更稳定的性能提升,因为它能够博采众长,弥补单个模型的不足。
想尝试 MoA?一些研究和实践经验或许能帮到你:
在构建一个高效的语言模型协同工作系统时,成员的多样性至关重要,就像组建团队需要不同背景和技能的人一样,选择不同架构和训练偏向的语言模型(LLM)作为提议者,其效果往往优于使用多个相同的模型。
增加提议者的数量通常能提升整体性能,因为它带来了更多元的视角和信息来源供聚合者参考,但这需遵循适度原则,平衡性能提升与成本效率。系统的“队长”——聚合者的能力至关重要,一个强大的、擅长信息整合和文本生成的LLM能更好地发挥提议者集群的优势。
研究表明,即使是层数较少的配置(如双层MoA-lite),通过合理的模型搭配,也能在性能上接近甚至超越一些顶级模型,同时显著降低运行成本,体现了性价比的优势。
当然,这种多模型协作并非没有代价。最主要的挑战在于延迟。等待多个提议者生成回复,再由聚合者进行处理,这个流程显然会比单个模型直接输出要耗时。如何优化响应速度,尤其缩短用户感知到的首字生成时间(TTFT),是未来 MoA 发展需要解决的关键问题。一些潜在方案包括并行处理、流式聚合等。
写在最后
MoA 为我们展示了一个充满想象力的 AI 协作新范式。它突破了单一模型的局限,通过有机地组合和协同多个具备不同能力的智能体,去攻克那些复杂多变、需要综合智慧的任务。
这不仅仅是一种技术架构的创新,更代表着一种理念的转变:未来的 AI 不会是少数几个“超级英雄”统治世界,而更可能是一个由各种专业智能体构成的、高效协作的“联盟”。
2025年的今天,AI创新已经喷井,几乎每天都有新的技术出现。作为亲历三次AI浪潮的技术人,我坚信AI不是替代人类,而是让我们从重复工作中解放出来,专注于更有创造性的事情,关注我们公众号口袋大数据,一起探索大模型落地的无限可能!