模型量化

ICLR 2024 Spotlight | 大语言模型权重、激活的全方位低bit可微量化,已集成进商用APP
模型量化是模型压缩与加速中的一项关键技术,其将模型权重与激活值量化至低 bit,以允许模型占用更少的内存开销并加快推理速度。对于具有海量参数的大语言模型而言,模型量化显得更加重要。例如,GPT-3 模型的 175B 参数当使用 FP16 格式加载时,需消耗 350GB 的内存,需要至少 5 张 80GB 的 A100 GPU。但若是可以将 GPT-3 模型的权重压缩至 3bit,则可以实现单张 A100-80GB 完成所有模型权重的加载。现有的大语言模型后训练量化算法依赖于手工制定量化参数,优于缺乏相应的优化过程,
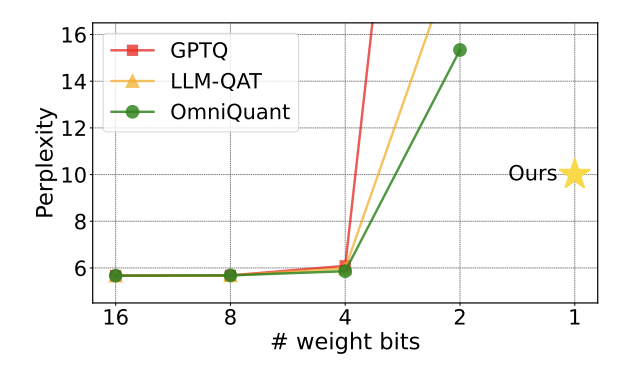
清华、哈工大把大模型压缩到了1bit,把大模型放在手机里跑的愿望就快要实现了!
近期,清华大学和哈尔滨工业大学联合发布了一篇论文:把大模型压缩到 1.0073 个比特时,仍然能使其保持约 83% 的性能!自从大模型火爆出圈以后,人们对压缩大模型的愿望从未消减。这是因为,虽然大模型在很多方面表现出优秀的能力,但高昂的的部署代价极大提升了它的使用门槛。这种代价主要来自于空间占用和计算量。「模型量化」 通过把大模型的参数转化为低位宽的表示,进而节省空间占用。目前,主流方法可以在几乎不损失模型性能的情况下把已有模型压缩至 4bit。然而,低于 3bit 的量化像一堵不可逾越的高墙,让研究人员望而生畏。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉