MLLMs
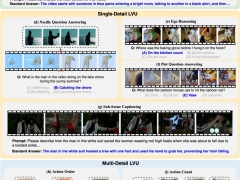
GPT-4o 差点没及格!首个多任务长视频评测基准,它有亿点难
难度大升级的多任务长视频理解评测基准 MLVU 来了!由智源联合北邮、北大和浙大等多所高校推出。究竟有多难呢?最终排名第一的 GPT-4o 单选正确率还不足 65%。而且研究发现,大部分模型的性能都会随着视频时长增加显著下降。研究进一步证明,提升上下文窗口,提升图像理解能力,以及使用更强大的 LLM Backbone 对长视频理解的性能具有显著的提升作用。目前相关论文及数据集已公开,具体细节下面一起看看吧~MLVU 的构建过程当前流行的 Video Benchmark 主要针对短视频设计,大部分视频的长度都在 1

苹果介绍 Ferret-UI 多模态大语言模型:更充分理解手机屏幕内容
感谢苹果公司近日发布研究论文,展示了 Ferret-UI AI 系统,可以理解应用程序屏幕上的内容。以 ChatGPT 为代表的 AI 大语言模型(LLMs),其训练材料通常是文本内容。为了能够让 AI 模型能够理解图像、视频和音频等非文本内容,多模态大语言模型(MLLMs)因此孕育而生。只是现阶段 MLLMs 还无法有效理解移动应用程序,这主要有以下几个原因:1. 手机屏幕的宽高比,和大多数训练图像使用的屏幕宽高比不同。2. MLLMs 需要识别出图标和按钮,但它们相对来说都比较小。因此苹果构想了名为 Ferre
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉