MatMul

13瓦功耗处理10亿参数,接近大脑效率,消除LLM中的矩阵乘法来颠覆AI现状
编辑 | 萝卜皮通常,矩阵乘法 (MatMul) 在大型语言模型(LLM)总体计算成本中占据主导地位。随着 LLM 扩展到更大的嵌入维度和上下文长度,这方面的成本只会增加。加州大学、LuxiTech 和苏州大学的研究人员声称开发出一种新方法,通过消除过程中的矩阵乘法来更有效地运行人工智能语言模型。这从根本上重新设计了目前由 GPU 芯片加速的神经网络操作方式。研究人员描述了如何在不使用 MatMul 的情况下创建一个自定义的 27 亿参数模型,性能与当前最先进的 Transformer 模型相当。该研究以「Scal
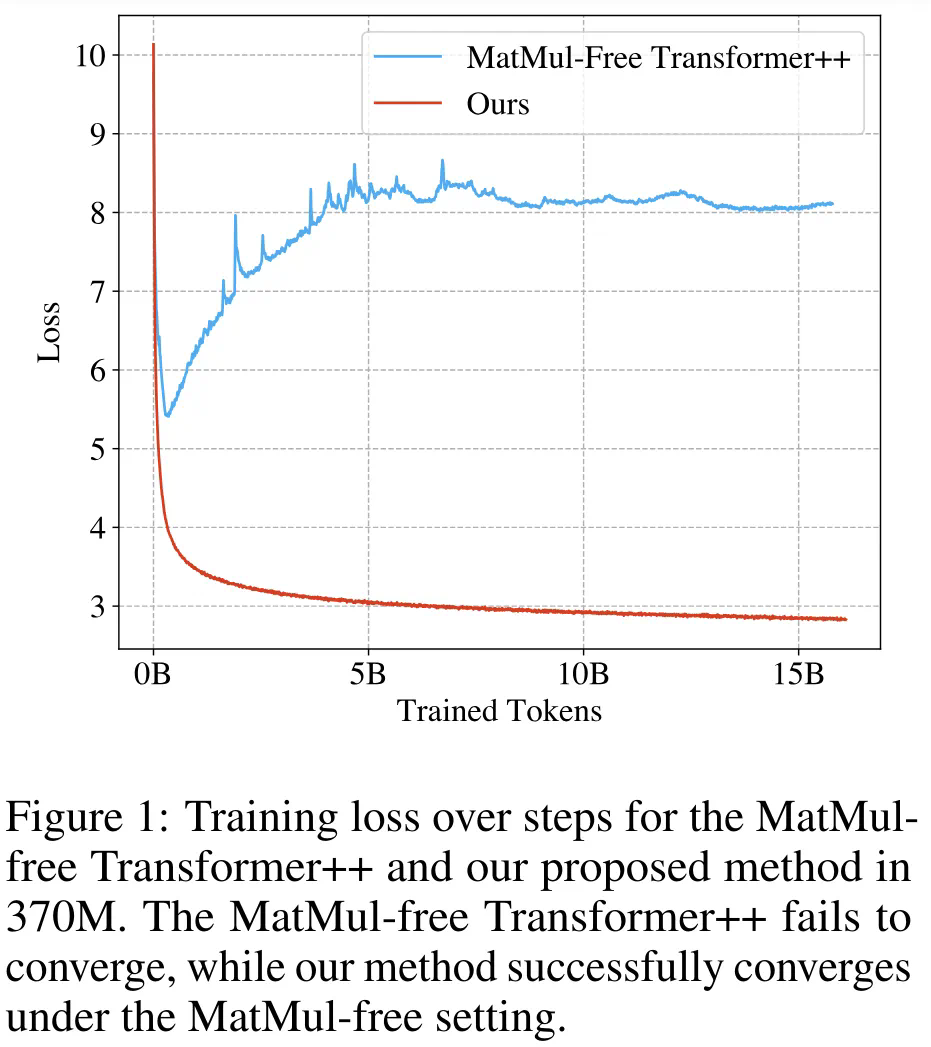
从LLM中完全消除矩阵乘法,效果出奇得好,10亿参数跑在FPGA上接近大脑功耗
让语言模型「轻装上阵」。一直以来,矩阵乘法(MatMul)稳居神经网络操作的主导地位,其中很大原因归结为 GPU 专门针对 MatMul 操作进行了优化。这种优化使得 AlexNet 在 ILSVRC2012 挑战赛中一举胜出,成为深度学习崛起的历史性标志。在这当中,有个值得注意的点是,AlexNet 利用 GPU 来提高训练速度,超越了 CPU 的能力,至此,GPU 的加入使得深度学习仿佛赢得了「硬件彩票」。尽管 MatMul 在深度学习中很流行,但不得不承认的是它占据了计算开销的主要部分,主要表现为 MatMu
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉