MATH

阿里云通义开源最强过程奖励PRM模型,7B尺寸比GPT-4o更能发现推理错误
1月16日,阿里云通义开源全新的数学推理过程奖励模型Qwen2.5-Math-PRM,72B及7B尺寸模型性能均大幅超越同类开源过程奖励模型;在识别推理错误步骤能力上,Qwen2.5-Math-PRM以7B的小尺寸就超越了GPT-4o。 同时,通义团队还开源首个步骤级的评估标准 ProcessBench,填补了大模型推理过程错误评估的空白。 在当前大模型推理过程中,不时存在逻辑错误或编造看似合理的推理步骤,如何准确识破过程谬误并减少它,对增强大模型推理能力、提升推理可信度尤为关键。
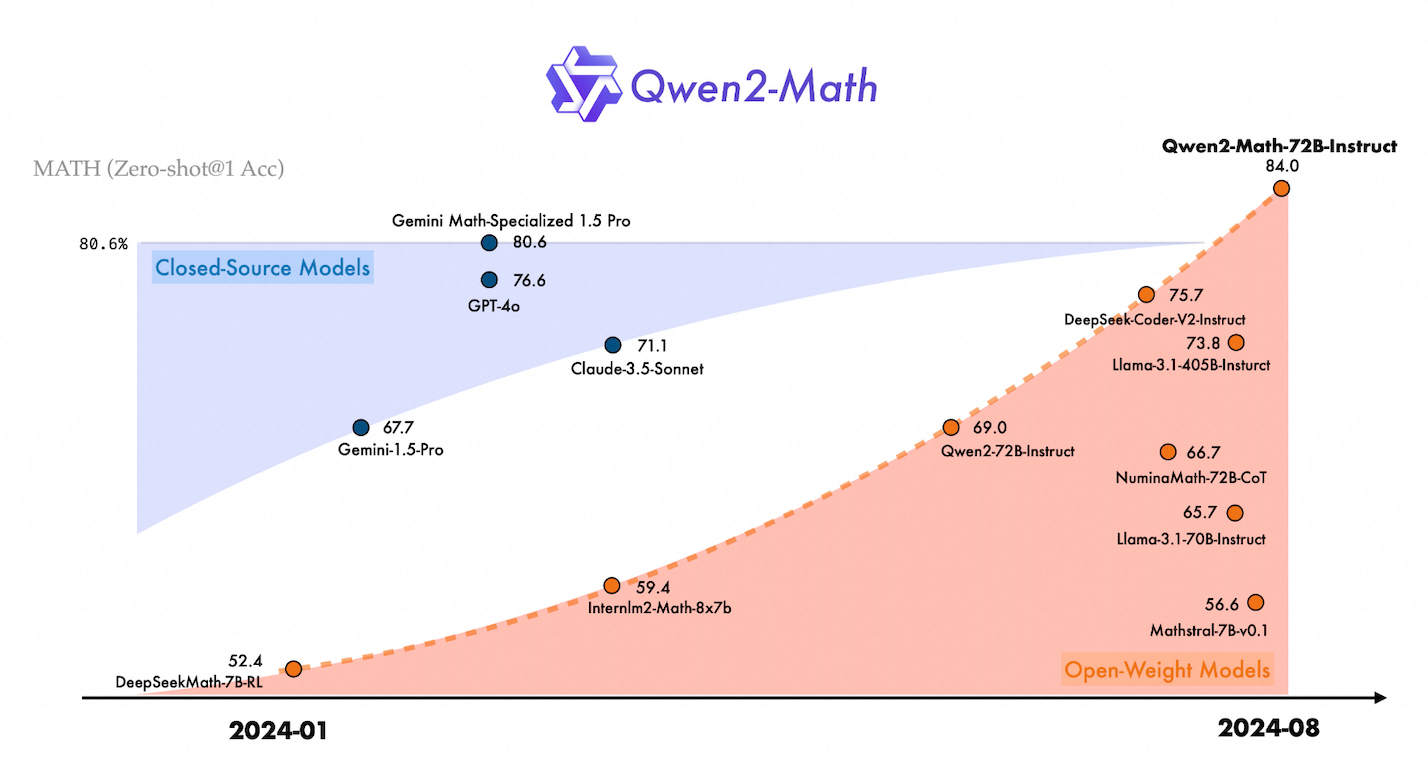
通义千问开源Qwen2-Math,成为最先进的数学专项模型
8月9日消息,阿里通义团队开源新一代数学模型Qwen2-Math,包含1.5B、7B、72B三个参数的基础模型和指令微调模型。Qwen2-Math基于通义千问开源大语言模型Qwen2研发,旗舰模型 Qwen2-Math-72B-Instruct在权威测评集MATH上的得分超越GPT-4o、Claude-3.5-Sonnet、Gemini-1.5-Pro、Llama-3.1-405B等,以84%的准确率处理了代数、几何、计数与概率、数论等多种数学问题,成为最先进的数学专项模型。注:在MATH基准测评中,通义千问数学模

Qwen2-Math 开源 AI 模型发布:阿里通义千问家族新成员,数学能力超 GPT-4o
感谢阿里通义千问 Qwen2 开源家族迎来新成员 Qwen2-Math,共有 15 亿参数、70 亿参数和 720 亿参数三个版本,是基于 Qwen2 LLM 构建、专门用于数学解题的语言模型。简介Qwen2-Math 是一系列基于 Qwen2 LLM 构建的专门用于数学解题的语言模型,其数学能力显著超越了开源模型,甚至超过了闭源模型(如 GPT-4o),官方希望为科学界解决需要复杂多步逻辑推理的高级数学问题做出贡献。性能团队在一系列数学基准评测上评估了我们的数学专用模型 Qwen2-Math。在 Math 上的评
陶哲轩力荐、亲自把关:AI for Math照这个清单学就对了
在 AI for Math 领域,如果你一直找不到合适的资源,这份清单或许会有帮助。刚刚,著名数学家陶哲轩的个人博客又更新了,这次他们整理了一份有用的资源列表,该资源专注于 AI for Math,专为那些希望进入数学 AI 领域的人提供帮助。这份清单发起时间最早可追溯到去年,发起机构由美国国家科学院、工程院和医学院组织的研讨会「人工智能辅助数学推理」提出,陶哲轩担任研讨会主持人。目前,网址资源已经公开。网址:,这是一个初步的资源列表,最初由 UIUC 教授 Talia Ringer 整理,供那些希望进入 AI 数
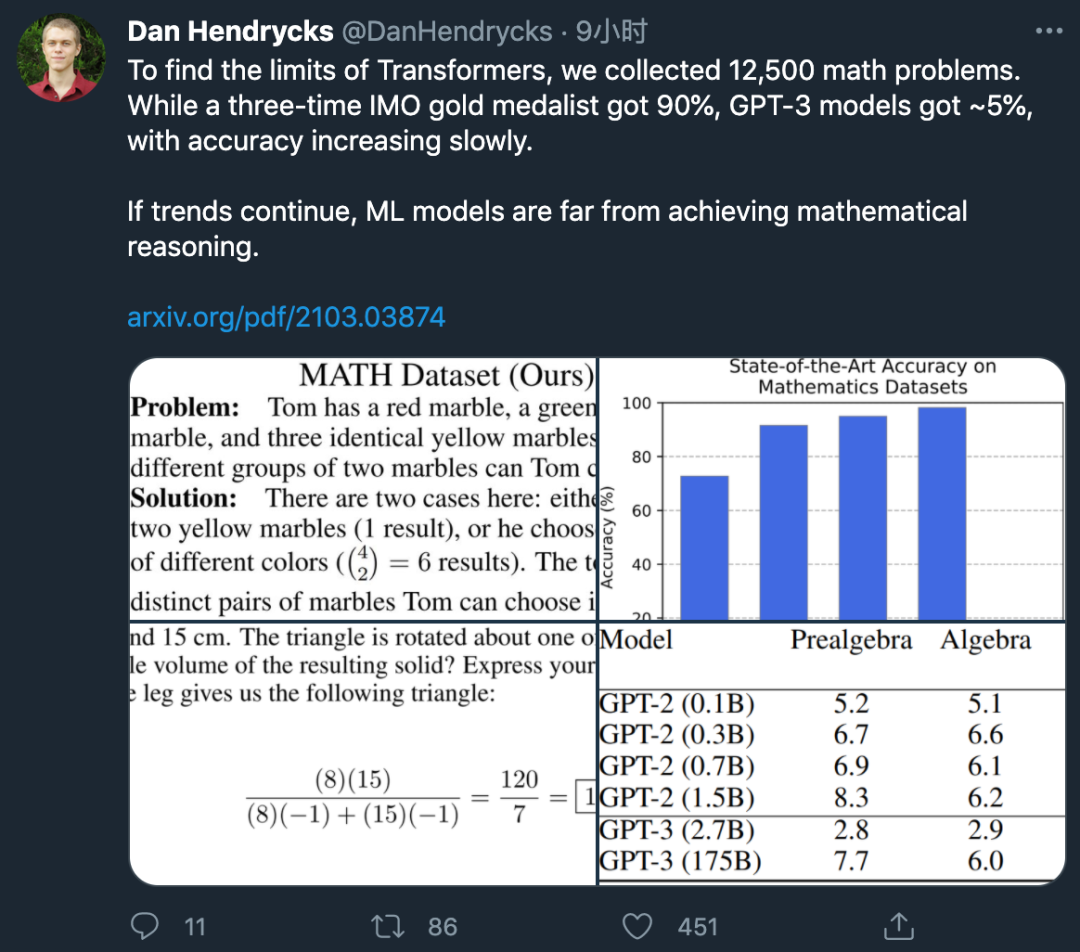
数学奥赛冠军都做不对的题,却被拿来考ML模型?GPT-3:我不行
为了衡量机器学习模型的数学求解能力,来自 UC 伯克利和芝加哥大学的研究者提出了一个包含 12, 500 道数学竞赛难题的新型数据集 MATH,以及帮助模型学习数学基础知识的预训练数据集 AMPS。研究发现,即使是大参数的 Transformer 模型准确率也很低。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉