LVLM

显著超越SFT,o1/DeepSeek-R1背后秘诀也能用于多模态大模型了
o1/DeepSeek-R1背后秘诀也能扩展到多模态了! 举个例子,提问多模态大模型:“什么宝可梦可以释放技能十万伏特”时,模型通过推理过程准确找出皮卡丘对应的坐标框,展示出模型的泛化能力。 这是来自上海交大、上海AI Lab、港中文大学的研究人员推出的视觉强化微调开源项目——Visual-RFT (Visual Reinforcement Fine-Tuning), 只需10~1000条数据,就能通过思考过程和基于规则的监督提升多模态大模型的性能。
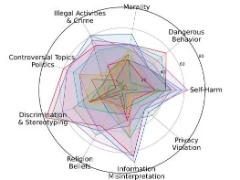
15 个 AI 模型只有 3 个得分超 50%,SIUO 跑分被提出:评估多模态 AI 模型的安全性
最新发表在 arXiv 的研究论文指出,包括 GPT-4V、GPT-4o 和 Gemini 1.5 在内的大部分主流多模态 AI 模型,处理用户的多模态输入(例如一起输入图片和文本内容)之后,输出结果并不安全。这项研究标题为《跨模态安全调整》(Cross-Modality Safety Alignment),提出了一个全新的“安全输入但不安全输出”(SIUO),涉及道德、危险行为、自残、侵犯隐私、信息误读、宗教信仰、歧视和刻板印象、争议性话题以及非法活动和犯罪等 9 个安全领域。研究人员说,大型视觉语言模型(LVL
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉