LMArena

国产大模型首登顶!文心5.0 Preview在LMArena全球竞技场拿下中国最高分
近日,全球公认的大模型“竞技场”LMArena发布了最新的模型排名。 根据AIbase获悉的最新数据显示,百度新一代模型ERNIE-5.0-Preview-1203凭借1451的高分正式登上文本榜单。 值得关注的是,这一成绩使其成功问鼎国内大模型第一的宝座,标志着国产原生大模型在国际主流测评体系中取得了里程碑式的突破。

谷歌Gemini 3发布后迅速登顶LMArena排行榜,马斯克与阿尔特曼齐送祝贺
谷歌发布Gemini 3后,其中Gemini 3 Pro以1501 Elo刷新LMArena公开榜单历史最高分,超越GPT-5.1、Claude 4. 5 与Grok-4.1,成为目前评分最高的多模态模型。 性能方面,Gemini 3 Pro在“人类终极考试”获37.5%、GPQA Diamond达91.9%,并在MMMU-Pro与Video-MMMU分别取得81%与87.6%,显示其在科学、数学及视频理解任务上全面领先。

LMArena最新排名:文心大模型5.0文本能力排名第一
在全球人工智能领域,竞争愈发激烈,最新消息显示,文心全新发布的 ERNIE-5.0-Preview-1022 模型在 LMArena 大模型竞技场的最新排名中脱颖而出,成为国内文本能力的冠军,同时在全球范围内并列第二。 这一成绩的取得,标志着中国在大模型技术上的再一次突破,也让人们对人工智能的未来充满期待。 根据 11 月 8 日发布的排名,ERNIE-5.0-Preview-1022 在创意写作、复杂长问题理解以及指令遵循等多个领域展现出卓越的性能,尤其在处理复杂的语言任务时,表现更是优于多款国际知名模型,包括 gpt-5-high。

谷歌新版Gemini马甲被扒! LMArena实测:唯一能看懂表的AI, GPT-5乱答
Gemini 3.0传了这么久,终于还是露出「马脚」了。 依然还是LMAreana竞技场,Gemini 3.0的两个「马甲」被扒了出来。 Gemini 3.0 Pro的马甲:lithiumflowGemini 3.0 Flash的马甲:orionmist这已经是「传统艺能」了,每次新模型上线,都要去LMArena上去造势一番。

凭什么Nano Banana能霸榜LMArena?
作者 | 朱先忠审校 | 重楼在AI图像生成领域,每隔一段时间就会有一款“现象级”模型横空出世。 2025年8月,谷歌DeepMind推出的Gemini 2.5 Flash Image,凭借“1-2秒出图”、“98.7%角色一致性”等颠覆性表现,被网友亲切称为“Nano Banana(纳米香蕉)”。 这款模型不仅在LMArena图像编辑榜单上以1362分的成绩刷新纪录,还让普通用户能像“指挥Photoshop学徒”一样用自然语言编辑图像。

免注册免费用!17种AI绘图模型一站式体验平台LMArena
从年初GPT4o的技惊四座,到年中Flux.1 Kontext的大放异彩,前不久Qwen的后来居上,再到前几天Nano-Banana的万众期待……近年来,国内外越来越多的AI绘图模型百花齐放,争奇斗艳。 这些模型各有所长又各有不足,面对复杂的设计需求很难做到一站式解决所有问题。 因此如何选择使用这些模型成了很多设计师朋友纠结和困扰的问题。

AI基准测试平台LMArena陷争议:研究指责其偏袒OpenAI、谷歌和Meta
人工智能领域知名的公共基准测试平台LMArena近日遭遇信任危机。 一项新的研究指出,该平台的排名系统存在偏袒OpenAI、谷歌和Meta等大型供应商的结构性问题,其不透明的流程和头部企业的固有优势可能导致排名失真。 然而,LMArena运营团队已公开否认这些指控。
LMArena正式成立公司,致力于提供中立的AI评估平台
近日,备受关注的人工智能评估平台 LMArena 宣布将成立一家新公司,名为 Arena Intelligence Inc.,以便为未来的项目改进提供更强大的资源。 LMArena 的创始团队在博客中表示,新公司的成立将帮助他们在保持中立的同时,增强大型语言模型(LLM)测试平台的功能,致力于为 AI 用户提供一个不受任何企业影响的公平评估环境。 LMArena 于2023年由加州大学伯克利分校的研究人员创建,迅速发展成为业内最受认可的 AI 基准测试平台之一。
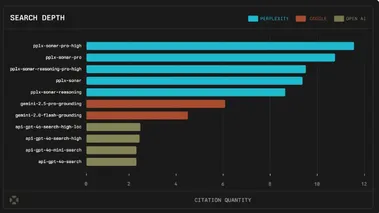
Perplexity 竞技场夺冠,Sonar挑战谷歌Gemini的搜索霸主地位
在最新的 LM Arena Search Arena 评估中,Perplexity 公司的 Sonar-Reasoning-Pro-High 模型表现优异,与谷歌的 Gem-2.5-Pro-Grounding 模型并列第一,直接对决的胜率达到53%。 这一消息无疑给搜索引擎领域带来了新的震动,显示了 Perplexity 在 AI 搜索技术上的强大实力。 Sonar 系列模型在此次评估中包揽了前四名,这不仅彰显了其深度搜索能力,也显示了其在严谨引证方面的出色表现。

Meta 新模型 Llama-4-Maverick 排名骤降,引发刷榜质疑
近日,Meta 公司发布的开源大模型 Llama-4-Maverick 在 LMArena 的排行榜上从第二名直降至第32名,这一剧烈波动引发了开发者们的广泛质疑,认为 Meta 可能通过提交特供版本以刷榜。 事情的起因要追溯到4月6日,Meta 发布了其最新的大模型 Llama4,包括 Scout、Maverick 和 Behemoth 三个版本。 其中,Llama-4-Maverick 在初期的评估中表现亮眼,位列 LMArena 排行榜的第二名,仅次于 Gemini2.5Pro。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉