LLMs

开源框架BioChatter助力生物医学研究,降低LLM使用门槛
近年来,大型语言模型(LLMs)在各个领域的应用日益广泛,从内容创作到编程辅助,再到搜索引擎优化,无不展现出其强大的能力。 然而,在生物医学研究中,这些模型的应用仍面临着透明度、可重复性和定制化等方面的挑战。 针对这一问题,海德堡大学与欧洲生物信息研究所(EMBL-EBI)联合提出了一个开源 Python 框架 ——BioChatter,旨在帮助生物医学研究人员更轻松地使用 LLMs。

Toolformer揭秘:大语言模型如何自学成才,掌握工具使用!
大语言模型(LLMs)在处理自然语言处理任务时展现出了令人印象深刻的零样本和少样本学习能力,但它们在一些基础功能上表现不佳,例如算术运算或事实查找。 这些局限性包括无法访问最新事件的信息、倾向于虚构事实、难以理解低资源语言、缺乏进行精确计算的数学技能,以及对时间进展的不敏感。 为了克服这些限制,一个简单的方法是让语言模型能够使用外部工具,如搜索引擎、计算器或日历。

DeepSeek671B提到的MOE是什么?图解MOE(混合专家模型)
本文仅做记录,图挺形象的。 原文:,你可能会在标题中看到“MoE”这个词。 那么,这个“MoE”到底代表什么?

AI 网关对决:Higress 与 OneAPI 的功能对比
什么是 AI 网关? AI 网关旨在统一管理与各种大型语言模型(LLMs)的交互。 通过提供单一入口点,它解决了使用来自不同供应商的多个 AI 模型所带来的复杂性问题。
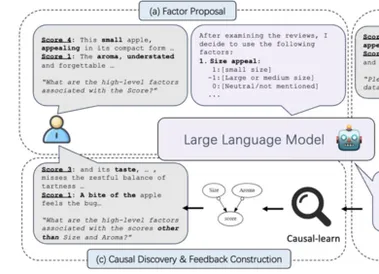
NeurIPS 2024 | 用LLM探寻隐秘的因果世界
因果发现的现实挑战:稀缺的高级变量寻找并分析因果关系是科学研究中的重要一环,而现有的因果发现算法依赖由专家预先定义的高级变量。 现实场景中的原始数据往往是图片、文本等高维非结构化数据, 结构化的高级变量是十分稀缺的,导致现有的因果发现和学习算法难以用于至更广泛的数据。 因此,香港浸会大学与MBZUAI、卡内基梅隆大学、香港中文大学、悉尼大学以及墨尔本大学合作发表论文《Discovery of the Hidden World with Large Language Models》,提出了一个名为 COAT 的新型框架,旨在利用大型语言模型和因果发现方法的优势,突破传统因果发现方法的局限性,更有效地在现实世界中定义高级变量、理解因果关系。

你的LLM评估方法过时了吗?这三个范式转变不容错过
在我的职业生涯中,我一直致力于为机器学习系统打造评估体系。 在担任 Quora 数据科学部门负责人时,我们为新闻源排序、广告投放、内容审查等构建了评估机制。 在 Waymo,我们团队为自动驾驶汽车开发了评估标准。

Torchtune:重塑大语言模型微调的新篇章
在当今的深度学习领域,大语言模型(LLMs)的微调已成为实现定制化模型功能的关键步骤。 为了满足这一需求,Torchtune应运而生,它是一个专为PyTorch设计的库,旨在简化LLMs的编写、微调及实验过程。 本文将详细介绍Torchtune的功能、特性、使用方法及其社区支持。

中国科大、科大讯飞团队开发ChemEval:化学大模型多层次多维度能力评估的新基准
编辑 | ScienceAI近日,认知智能全国重点实验室、中国科学技术大学陈恩红教授团队,科大讯飞研究院 AI for Science 团队发布了论文《ChemEval: A Comprehensive Multi-Level Chemical Evaluation for Large Language Models》,介绍了新研发的一个面向化学领域大模型能力的多层次多维度评估框架 ChemEval。论文链接: : (NLP)的领域中,大语言模型(LLMs)已经成为推动语言理解与生成能力不断进步的强大引擎。随着这些

大语言模型的规模化联邦全参数调优
光明实验室基础智能研究团队携手新加坡国立大学最新突破——大语言模型的规模化联邦全参数调优,为大语言模型(LLMs)的联邦学习开辟了全新篇章!其中共一第一作者是光明实验室基础智能研究团队负责人,共一第二作者是新加坡国立大学博士生,均师从新加坡国立大学的Bryan Low教授。论文链接:, :(LLMs)已在众多实际应用中变得不可或缺。然而,在规模化环境下对这些模型进行微调,尤其是在数据隐私和通信效率至关重要的联邦设置中,仍面临着重大挑战。现有方法通常采用参数高效微调(PEFT)来减轻通信开销,但这通常以牺牲模型性能为

浙大、腾讯团队发布科学LLM大规模评测基准,国产大模型表现亮眼
编辑 | ScienceAI随着大型语言模型(LLMs)在科学研究领域的广泛应用,评估这些模型在理解和应用科学知识方面的能力变得尤为重要,但是科学领域全面评估 LLMs 科学知识的高级基准非常缺乏。近日,来自浙江大学 NLP 实验室与腾讯 AI Lab 的研究者构建了 SciKnowEval 评测基准,定义了 L1 到 L5 不同层级的科学智能,共包含化学和生物领域 50,000 个不同层次的科学评测题目,并利用该数据集用于对 20 个开源和闭源 LLMs 进行基准测试。其中,拥有千亿至万亿参数的通用大语言模型如

字节团队提出猞猁Lynx模型:多模态LLMs理解认知生成类榜单SoTA
文章首次提出包括图像和视频任务的开放式视觉问答评估集 Open-VQA
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉