LLaVA

【多模态&LLM】LLaVA系列算法架构演进:LLaVA(1.0->1.5->Next(1.6)->NeXT(Video))
LLaVA模型架构目标是结合预训练LLM和视觉模型的能力,llava使用Vicuna作为的LLM (语言解码器),CLIP作为视觉编码器。 训练过程分两阶段:LLaVA 1.5LLaVA1.5是LLaVA改进版本,主要在网络结构、数据集规模上进行改进。 LLaVA 1.5模型结构还是之前的llava模型结构,但是做了一些小修改:将视觉-语言连接器由线性投影修改成一个两层的mlp(前期文章的NVLM-D也是两层的mlp链接视觉-语言模型);将224分辨率的视觉编码器修改为336pix的视觉编码器(带有MLP投影的CLIP-ViT-L-336px)。

用LLaVA解读数万神经元,大模型竟然自己打开了多模态智能黑盒
AIxiv专栏是AI在线发布学术、技术内容的栏目。 过去数年,AI在线AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。 如果您有优秀的工作想要分享,欢迎投稿或者联系报道。
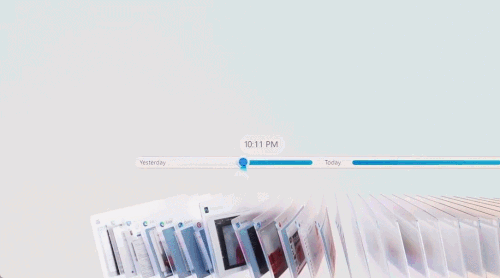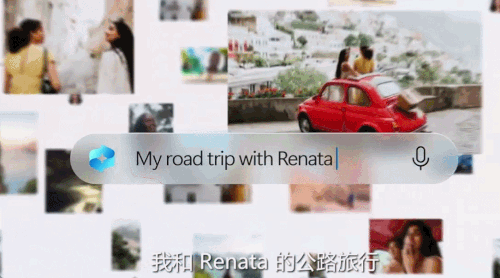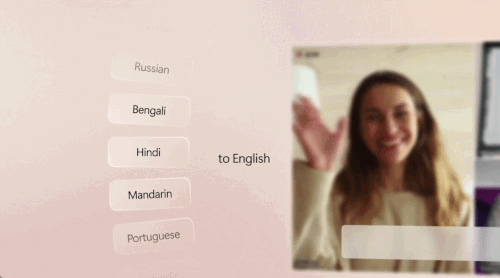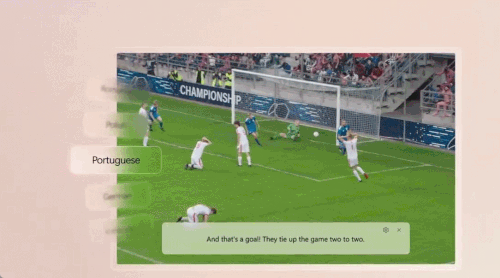
WAIC上,高通这一波生成式AI创新,让我们看到了未来
做最有挑战的事:把生成式 AI 送到每个人手上。没想到,生成式 AI 爆发后,产业格局的变化居然这么快。一个月前,微软向全世界介绍了专为 AI 设计的「Copilot PC」,AI PC 这个新品类突然有了标准款。这是迄今为止速度最快、最智能化的 Windows 个人电脑。凭借搭载的新型芯片,它能够实现超过 40 TOPS(每秒万亿次操作)AI 算力、电池续航时间长达一整天,而且无缝接入了世界最先进的人工智能模型。其发布之时,只有骁龙 X 系列的 45TOPS 能够满足这样的 Windows 11 AI PC
赶超Gemini Pro,提升推理、OCR能力的LLaVA-1.6太强了
去年 4 月,威斯康星大学麦迪逊分校、微软研究院和哥伦比亚大学研究者共同发布了 LLaVA(Large Language and Vision Assistant)。尽管 LLaVA 是用一个小的多模态指令数据集训练的,却在一些样本上展示了与 GPT-4 非常相似的推理结果。10 月,LLaVA-1.5 重磅发布,通过对原始 LLaVA 的简单修改,在 11 个基准上刷新了 SOTA。现在,研究团队宣布推出 LLaVA-1.6,主要改进了模型在推理、OCR 和世界知识方面的性能。LLaVA-1.6 甚至在多项基准测

通用视觉推理显现,UC伯克利炼出单一纯CV大模型,三位资深学者参与
仅靠视觉(像素)模型能走多远?UC 伯克利、约翰霍普金斯大学的新论文探讨了这一问题,并展示了大型视觉模型(LVM)在多种 CV 任务上的应用潜力。最近一段时间以来,GPT 和 LLaMA 等大型语言模型 (LLM) 已经风靡全球。 另一个关注度同样很高的问题是,如果想要构建大型视觉模型 (LVM) ,我们需要的是什么? LLaVA 等视觉语言模型所提供的思路很有趣,也值得探索,但根据动物界的规律,我们已经知道视觉能力和语言能力二者并不相关。比如许多实验都表明,非人类灵长类动物的视觉世界与人类的视觉世界非常相似,尽管
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉